本文主要是介绍NVIDIA CUDA初级教程(P5-P10)GPU体系架构和CUDA/GPU编程模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.GPU体系架构
- 2.CUDA/GPU 编程模型
- 3.Linux下CUDA程序分析和调试工具
1.GPU体系架构
为什么需要GPU?
- 应用的需求越来越高
- 计算机技术由应用驱动(Application Driven)
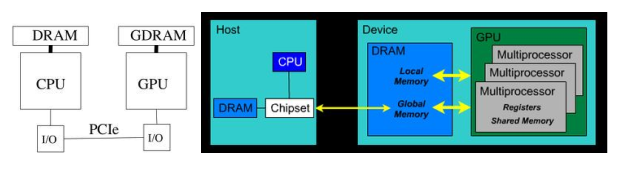
GPU(Graphic Processing Unit)
- GPU是一个异构的多处理器芯片,为图形图像处理优化
- CPU类型的存储器架构

- GPU类型的存储器架构

2.CUDA/GPU 编程模型
CPU-GPU交互
- 各自的物理内存空间
- 通过PCIE总线互连(8GB/s~16GB/s)
- 交互开销较大
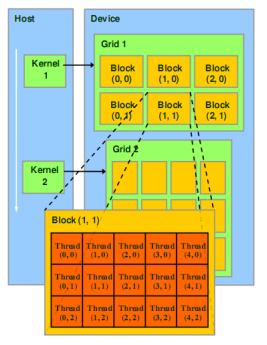
GPU线程组织模型
- 一个Kernel具有大量线程
- 线程被划分成线程块‘blocks’
(1) 一个block内部的线程共享 ‘Shared Memory’
(2)可以同步 ‘_syncthreads()’ - Kernel启动一个‘grid’,包含若干线程块
(1)用户设定 - 线程和线程块具有唯一的标识

GPU内存模型

GPU内存和线程之间的关系

GPU应用
- 常规意义的GPU用于处理图形图像,操作于像素,每个像素的操作都类似
- 还可以应用SIMD (single instruction multiple data),也可以认为是数据并行分割

- Single Instruction Multiple Thread (SIMT)
GPU版本的 SIMD;
大量线程模型获得高度并行;
线程切换获得延迟掩藏;
多个线程执行相同指令流;
GPU上大量线程承载和调度;
CUDA编程模式:Extended C
-
CUDA 函数声明

(1)__global__ 定义一个 kernel 函数
入口函数,CPU上调用,GPU上执行
必须返回void
(2) __device__ 和 __host__ 可以同时使用
(3)Global和device函数:尽量少用递归、不使用静态变量、少用malloc(现在允许但不鼓励)、小心通过指针实现的函数调用 -
eg:

CUDA术语
-
Host – 即主机端 通常指 CPU
采用ANSI标准C语言编程 -
Device – 即设备端 通常指 GPU (数据可并行)
采用ANSI标准C的扩展语言编程 -
Host 和 Device 拥有各自的存储器
-
CUDA 编程
包括主机端和设备端两部分代码 -
Kernel核函数:数据并行处理函数
通过调用kernel函数在设备端创建轻量级线程;
线程由硬件负责创建并调度;
线程层次Thread Hierarchies
-
CUDA 核函数(Kernels)
在N个不同的CUDA线程上并行执行

-
CUDA 程序的执行

-
Grid – 一维或多维线程块(block),多个线程块
一维 二维 或 三维;

-
Block:一组线程,线程块
一维,二维或三维,例如: 索引数组,矩阵,体;
一个Grid里面的每个Block的线程数是一样的;
block内部的每个线程可以:同步 synchronize、访问共享存储器 shared memory;不同块的两个线程不能通信;
Thread ID: Scalar thread identifier
- 线程索引: threadIdx
- 一维Block: Thread ID == Thread Index
- 二维Block (Dx, Dy)
Thread ID of index (x, y) == x + y D y D_y Dy - 三维Block (Dx, Dy, Dz)
Thread ID of index (x, y, z) == x + y D y D_y Dy + z D x D_x Dx D y D_y Dy - eg:

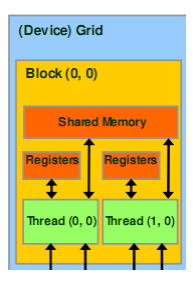
Thread Block线程块
- 线程的集合
- 位于相同的处理器核心(SM)
- 共享所在核心的存储器
- 块索引: blockIdx
维度: blockDim, 一维或二维或三维

- 线程块之间彼此独立执行
任意顺序: 并行或串行
被任意数量的处理器以任意顺序调度
处理器的数量具有可扩展性

一个块内部的线程
- 共享容量有限的低延迟存储器
- 同步执行
(1)合并访存
(2)__syncThreads()
Barrier – 块内线程一起等待所有线程执行到某处语句
轻量级
- eg:
通过grid和block坐标计算线程id
int threadID=blockIdx.x * blockDim.x + threadIdx.x;用线程id从输入读入元素
float x=input[threadID];在输入数据上执行函数,数据可并行
float y= func(x);output[threadID] = y;
CUDA 内存传输
- 寄存器Registers
(1)每个线程专用
(2)快速、片上、可读写
(3)eg:G80每个SM有769个线程,8K个寄存器、则每个线程可以分别有8K/768线程=10寄存器/线程 - 局部存储器Local Memory
(1)存储于global memory,作用于每个thread
(2)用于存储自动变量数组,通过常量索引访问 - 共享存储器shared Memory
(1)每个块
(2)快速、片上、可读写
(3)全速随机访问 - eg:G80的共享存储器的每个SM包含8个blocks,16KB共享存储、所以每个block可以分配16KB/8=2KB/block
- 全局存储器Global memory
(1)长延时(100个周期)
(2)片外、可读写
(3)随机访问影响性能 - 常量存储器Constant Memoy
(1)短延时、带宽高、当所有线程访问同一位置时只读
(2)存储于global memory但是有缓存
(3)Host主机端可读写
(4)容量64KB

- Global and constant变量

Host可以通过以下函数访问
cudaGetSymbolAddress();
cudaGetSymbolSize();
cudaMemcpyToSymbol();
cudaMemcpyFromSymbol();constants变量必须在函数外声明
-
设备端代码
(1)R/W per-thread registers
(2)R/W per-thread local memory
(3)R/W per-block shared memory
(4)R/W per-grid global memory
(5)read only per-grid constant memory -
主机端代码
R/W per-grid global and constant memory;
主机端读写global memory和constant memory -
Host 可以从 device 往返传输数据
(1)Global memory全局存储器
(2)Constant memory常量存储器
在设备端分配 global memory
cudaMalloc()
释放存储空间
cudaFree()float* Md;
int size=width*width*sizeof(float);
//Md:Pointer to device memory
//size:size in bytes
cudaMalloc((void**)&Md, size);
cudaFree(Md);内存传输
cudaMemcpy()
Host to host
Host to device
Device to host
Device to device//host to device
//cudaMemcpy(Destination,Source,XX,XX)
cudaMemcpy(Md,M,size,cudaMemcpyHostToDevice);
cudaMemcpy(Md,M,size,cudaMemcpyDeviceToHost);
- eg:Matrix Multiply 矩阵相乘算法
(1)P = M * N
(2)假定 M and N 是方阵
(3)1,000 x 1,000矩阵:1,000,000 点乘,Each 1,000 multiples and 1,000 adds

Matrix Multiply: CPU 实现void MatrixMulOnHost(float* M, float* N, float* P, int width)
{for (int i = 0; i < width; ++i)for (int j = 0; j < width; ++j){float sum = 0;for (int k = 0; k < width; ++k){//二维数组的一维表示形式float a = M[i * width + k];float b = N[k * width + j];sum += a * b;}P[i * width + j] = sum;}
}
Matrix Multiply: CUDA C 实现
第1步:在算法框架中添加 CUDA memory transfers
#include "cuda.h"
void MatrixMulOnDevice(float* M,float* N, float* P,int Width)
{int size=Width*Width*sizeof(float);//分配输入:Load M and N to device memorycudaMalloc(Md,size);cudaMemcpy(Md,M,size,cudaMemcpyHostToDevice);cudaMalloc(Nd,size);cudaMemcpy(Nd,N,size,cudaMemcpyHostToDevice);//分配输出:Allocate P on the devicecudaMalloc(Pd,size);//Kernel invocation code//从device读回:Read P from the devicecudaMemcpy(P,Pd,size,cudaMemcpyDeviceToHost);//Free device matricescudaFree(Md);cudaFree(Nd);cudaFree(Pd);
}第2步:CUDA C编程实现 kernel
//Matrix multiplication kernel-thread specification
__global__ void MatrixMulKernel(float* Md, float* Nd, float* Pd, int Width)
{//2D Thread ID//每个线程可以处理结果矩阵的一个元素,x,y表示结果矩阵的下标//访问一个matrix,所以采用二维blockint tx=threadIdx.x;int ty=threadIdx.y;//每个kernel线程计算一个输出:Pvalue stores the Pd element that is computed by thr threadfloat Pvalue=0;for (int k=0;k<Width;++k){float Mdelement=Md[ty*Md.width+k];float Ndelement=Md[k*Md.width+tx];Pvalue += Mdelement*Ndelement;}//每个结果矩阵里面的元素是独立的//Write the matrix to device memory each thread writes one elementPd[ty*Width+tx]=Pvalue ;
}
第3步:CUDA C编程调用 kernel
//Setup the execution configuration
dim3 dimBlock(WIDTH,WIDTH);//一个block含有widyh*width个线程
dim3 dimGrid(1,1);//Launch the device computation threads!
//<<<dimBlock,dimGrid>>>代表配置参数
MatrixMulKernel<<<dimBlock,dimGrid>>>(Md,Nd,Pd);
Matrix Multiply: CUDA C 实现解释
- 一个线程block计算Pd
每个线程计算Pd的一个元素 - 每个线程
读入矩阵Md的一行
读入矩阵Nd的一列
为每对Md和Nd元素执行一次乘法和加法 - (not very high) 计算次数和片外访存次数比率接近1:1(不是很高,读一次数据做一次乘累加)
- 矩阵的长度受限于一个线程块允许的线程数目(一个线程处理一个元素)

问题
- 矩阵长度限制
仅用一个block
G80 和 GT200 – 最多512 个线程/block
解决办法:去除长度限制,目的是适应更大的矩阵
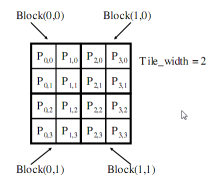
将Pd 矩阵拆成tile小块,把一个tile 布置到一个block,通过 threadIdx 和blockIdx索引

将Pd矩阵拆分为4个block
矩阵: 4x4
TILE_WIDTH = 2
Block 尺寸: 2x2
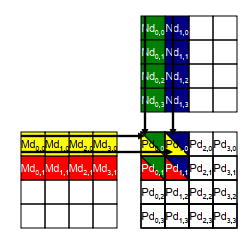
__global__ void MatrixMulKernel(float* Md, float* Nd, float* Pd, int Width)
{//计算矩阵Pd 和M的行索引int Row = blockIdx.y * blockDim.y + threadIdx.y;//计算矩阵Pd 和N的列索引int Col = blockIdx.x * blockDim.x + threadIdx.x;float Pvalue = 0;//每个线程计算块内子矩阵的一个元素for (int k = 0; k < Width; ++k)Pvalue += Md[Row * Width + k] * Nd[k * Width +Col];Pd[Row * Width + Col] = Pvalue;
}调用 kernel:
//dim3 表示三维类型
//Width / TILE_WIDTH宽度方向上有多少block
//Height / TILE_WIDTH高度方向上有多少block
dim3 dimGrid(Width / TILE_WIDTH, Height / TILE_WIDTH);//需要多少block
dim3 dimBlock(TILE_WIDTH, TILE_WIDTH);//每个block的大小
//Grid维度表示有多少block,Block表示有多少线程
MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, TILE_WIDTH);
向量数据类型
- 同时适用于host和device代码
char[1-4],uchar[1-4]
short[1-4],ushort[1-4]
int[1-4],uint[1-4]
long[1-4],ulong[1-4]
longlong[1-4],ulonglong[1-4]
float[1-4]
double1,double2
- 通过函数make_构造,eg:
int2 i2=make_int2(1,2);
float4 f4=make_float4(1.0f,2.0f,3.0f,4.0f);
- 通过.x,.y,.z,and .w访问
int2 i2=make_int2(1,2);
int x=i2.x;
int y=i2.y;
- 数学函数
部分函数列表:
sqrt、rsqrt、exp、log、sin、cos、tan、sincos、asin、acos、atan2、trunc、ceil、floor
- Instrinsic function内建函数
仅面向Device设备端;
更快,但精度降低;
以__为前缀,eg:__exp,__log,__sin,__pow
线程同步
- 块内线程可以同步
- 调用__syncthreads创建一个barrier栅栏
- 每个线程在调用点等待块内所有线程执行到这个地方,然后所有线程继续执行后续指令
- eg:
Mds[i]=Md[j];
__syncthreads();
func(Mds[i], Mds[i+1]);
- 同步流程可以参考如下




- 线程同步__syncthreads()会导致线程暂停吗?
会,下面是逻辑错误,可能会导致死锁
if (someFunc())
{__syncthreads();
}
else
{__syncthreads();
}
- 线程调度中SP和SM的区别

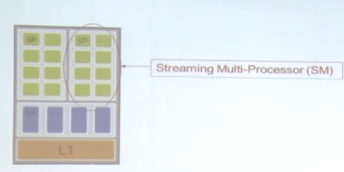
- Warp:块内的一组线程
(1)运行于同一个SM
(2)线程调度的基本单位
(3)threadIdx值连续
(4)若warp内部线程沿着不同分支执行,可能会产生Divergent线程束分化
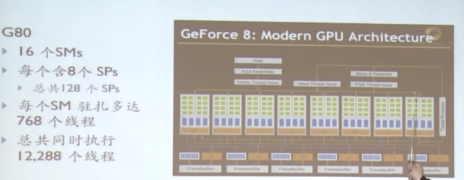
(5)若一个SM分配了3个block,其中每个block含有256个线程,总共有多少warp?
假设一个block有32个warp,256/32*3=24;
(6)GT200的一个SM最多可以驻扎1024个线程,那相当于多少个warp?
1024/32=32;
(7)每个warp含有32个线程,但是每个SM只有只有8个SPs(这里假设一个SP只允许一个线程),如何分配?
当一个SM调度一个warp时,指令已经准备好了;
在第一个周期,8个线程进入SPs;
在第二、三、四个周期,各进入8个线程;
so,分发一个warp需要4个周期
读写global memory的优化
-
原因:
G80 峰值GFLOPS: 346.5(每个浮点数是4个字节),意味着需要 1386 GB/s 的带宽来达到(346.5*4)
G80 存储器实际带宽: 86.4 GB/s,限制代码 21.6 GFLOPS;
实际上,代码运行速度是 15 GFLOPS
所以必须大幅减少对 global memory 的访问 -
每个输入元素被Width 个线程读取
使用 shared memory 来减少global memory 带宽需求
做法:把 kernel 拆分成多个阶段,每个阶段用 Md 和 Nd 的子集累加Pd,每个阶段有很好的数据局部性
每个线程:读入瓦片TILE内 Md 和 Nd 的一个元素存入 shared memory

__global__ void MatrixMulKernel(float* Md, float* Nd, float* Pd, int Width)
{//Shared memory 存储Md 和 Nd 的子集__shared__ float Mds[TILE_WIDTH][TILE_WIDTH];__shared__ float Nds[TILE_WIDTH][TILE_WIDTH];int bx = blockIdx.x; int by = blockIdx.y;int tx = threadIdx.x; int ty = threadIdx.y;int Row = by * TILE_WIDTH + ty;int Col = bx * TILE_WIDTH + tx;float Pvalue = 0;//Width/TILE_WIDTH//阶段数目m//当前阶段的索引for (int m = 0; m < Width/TILE_WIDTH; ++m) {//从Md 和 Nd 各取一个元素存入 shared memoryMds[ty][tx] = Md[Row*Width + (m*TILE_WIDTH + tx)];Nds[ty][tx] = Nd[Col + (m*TILE_WIDTH + ty)*Width];//等待block内所有线程, 即等到整个瓦片存入 shared memory__syncthreads();//累加点乘的子集for (int k = 0; k < TILE_WIDTH; ++k)Pvalue += Mds[ty][k] * Nds[k][tx];__synchthreads();}//把最终结果写入global memoryPd[Row*Width+Col] = Pvalue;
}
如何选取 TILE_WIDTH的数值?
- eg:G80: 16KB / SM 并且 8 blocks / SM,所以:2 KB / block(每个block占用2KBshared memory),所以1 KB 给 Nds ,1 KB 给 Mds (1024/4=256,256=16*16,16 * 16 * 4),所以TILE_WIDTH = 16
注意: 更大的 TILE_WIDTH 将导致更少的块数 - Shared memory 瓦片化的好处
(1)global memory 访问次数减少TILE_WIDTH倍,16x16 瓦片 减少16倍
(2)所以,现在的global memory 支持 345.6 GFLOPS(20*16,其中20来自上述的G80 存储器实际带宽: 86.4 GB/s,限制代码 21.6 GFLOPS;) - 每个 thread block有多少个线程?
TILE_WIDTH 为 16 时(16*16 Pd): 16*16 = 256 个线程,即1个block有256个线程;
若一个 1024*1024 Pd矩阵需要多少block: 64*64 = 4K Thread Blocks(因为32*32=1024不够矩阵大小)
Atomic Functions原子函数
- 尽量少用原子操作
- 对同一个内存地址做了add,那么其余线程都会去排队
// 算术运算 // 位运算
atomicAdd()
atomicSub()
atomicExch()
atomicMin()
atomicMax()
atomicAdd()
atomicDec()
atomicCAS()atomicAnd()
atomicOr()
atomicXor()
3.Linux下CUDA程序分析和调试工具
LInux程序开发环境
-
CUDA5.5有nsight环境
-
一个显卡用来显示,一个显卡用来计算

-
nsight开发测试
只用K5000
源码添加

-
CUDA gdb
nvcc -g -G myXX.cucuda-gdb a.out
help cuda
cuda thread (2,0,0)多余的GPU 需要关掉
这篇关于NVIDIA CUDA初级教程(P5-P10)GPU体系架构和CUDA/GPU编程模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







