本文主要是介绍【预训练语言模型】K-BERT: Enabling Language Representation with Knowledge Graph,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【预训练语言模型】K-BERT: Enabling Language Representation with Knowledge Graph
核心要点:
- 融合KG到BERT,并非是embedding融合,而是将KG和原始文本结合形成sentence-tree;
- 根据sentence tree提出soft-position和visible matrix以避免knowledge noise;
- K-BERT在中文领域上先预训练(不加KG),然后在fine-tuning(加KG)
简要信息:
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | K-BERT |
| 2 | 发表位置 | AAAI 2020 |
| 3 | 所属领域 | 自然语言处理、预训练语言模型 |
| 4 | 研究内容 | 知识增强的语言模型 |
| 5 | 核心内容 | Knowledge-enhanced PLM |
| 6 | GitHub源码 | https://github.com/autoliuweijie/K-BERT |
| 7 | 论文PDF | https://ojs.aaai.org//index.php/AAAI/article/view/5681 |
一、动机
- 现如今无监督的预训练语言模型在诸多任务上达到SOTA。但是这些方法忽略了引入domain knowledge。由于预训练和微调之间的领域差异(domain-discrepancy),在依赖于knowledge的任务上这些模型的表现并不很好;
Even though they can refresh the state-of-the-art of GLUE (Wang et al. 2018) benchmark by learning from open-domain corpora, they may fail in some domain-specific tasks, due to little knowledge connection between specific and open domain.
- 引入知识图谱表征并与语言模型的表征进行融合可以实现增强。但是这种knowledge integration存在两个挑战:(1)实体的embedding和word embedding来自不同的语义空间,即异构嵌入空间(Heterogeneous Embed- ding Space,HES);(2)过多地引入knowledge可能会带来大量的噪声Knowledge Noise(KN);
二、方法
本文提出一种知识增强的预训练语言模型,模型架构如下图所示:

- Knowledge Layer:对输入的文本,检索相应的三元组,并结合原始文本,将输入转换为sentence tree;
- Embedding Layer:将sentence tree喂入Emebdding Layer得到token-level embeddng;
- Seeing Layer:将sentence tree喂入该模块得到visible matrix,对于每个token控制其可见范围,以控制语义的表示;
2.1 Knowledge Layer
旨在将输入的文本以及对应的KG,将文本转换为sentence tree
- K-Query:从KG中查询与当前输入文本有关的所有三元组: E = K Q u e r y ( s , K ) E=K_{Query}(s, \mathbb{K}) E=KQuery(s,K)
- K-Inject:将检索到的三元组,根据其对应的entity mention的position,嵌入到原始的文本中,并生成sentence tree: t = K I n j e c t ( s , E ) t=K_{Inject}(s, E) t=KInject(s,E)。
sentence tree的样例如下图所示:

2.2 Embedding Layer
引入Knowledge Layer得到的是tree结构,因此需要将其转换为序列。转换的方法(re-arrangement):
In our re-arrange strategy, tokens in the branch are inserted after the corresponding node, while subsequent tokens are moved backwards.
例如下图:

- Token embdding:选择BERT的embedding和分词方法;
- Soft-position embedding:改进position embedding,将sentence tree上的节点也进行编号;
- Segment embedding:与BERT一致;
2.3 Seen Layer
动机: The input to K-BERT is a sentence tree, where the branch is the knowledge gained from KG. However, the risk raised with knowledge is that it can lead to changes in the meaning of the original sentence
因为将外部知识也直接插入到了原始文本中,避免模型在进行attention计算时,将没有相关联的实体进行计算,因此需要生成一个visible matrix以限制attention的计算范围:
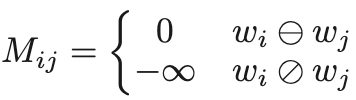
限制方法:如果token i i i 和 j j j 属于同一个branch(即 w i ⊖ w j w_i\ominus w_j wi⊖wj),则允许计算它们之间的attention,否则不计算attention。
例如:
● Cook和Apple在同一个分支上,则需要计算attention;
● Apple和China不在同一个分支上,不需要计算attention;
● Cook和Beijing在同一个分支(原始文本序列),需要计算attention
根据visible matrix,对attention矩阵进行mask,计算过程如下所示:

三、实验
3.1 数据语料
Pre-trained Corpora
使用两个中文语料:
- WikiZh:https://dumps.wikimedia.org/zhwiki/latest/
- WebtextZh:https://github.com/brightmart/nlp_chinese_corpus
Knowledge Graph
- 复旦知识工场:http://kw.fudan.edu.cn/cndbpedia/intro/
- HowNet:http://www.keenage.com/
- MedicalKG:作者自己构建的中文医疗KG
3.2 实验设置
baseline
- 原始的BERT;
- 将BERT重新在WikiZh和WebtextZh上进行预训练;
parameter - 所有参数与BERT保持一致;
- K-BERT的预训练阶段不融入KG,在Fine-tuning和Inference阶段使用KG;
For K-BERT pre-training, all settings are consistent with (Devlin et al. 2018). One thing to emphasize is that we don’t add any KG to K-BERT during the pre-training phase. Be- cause KG binds two related entity names together, thus mak- ing the pre-trained word vectors of the two are very close or even equal and resulting in a semantic loss. Therefore, in the pre-training phase, K-BERT and BERT are equivalent, and the latter’s parameters can be assigned to the former. KG will be enabled during the fine-tuning and inferring phases.
3.3 实验结果
在若干Open domain Task上进行fine-tuning的结果如下表所示:

- KG对于情感分析类任务没有实质的增益;
- 对于语义相似判断类的任务(NLI等),HowNet更优势;而对于QA和NER类任务,CN-DBpedia更优势;因此对于不同的任务,需要考虑选择相应的KG;
在若干Specific-domain Task进行fine-tuning的结果如下表所示:

- 可知引入KG可以有效提高P、R和F1值
3.4 消融实验:

这篇关于【预训练语言模型】K-BERT: Enabling Language Representation with Knowledge Graph的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



