本文主要是介绍On Improving Code Mixed Speech Synthesis with Mixlingual Grapheme-to-Phoneme Model,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章出自Microsoft STC India, INTERSPEECH 2020。
本文主要解决的问题在于,针对英文-印度语混读情景,当印地语使用罗马字母拼写的时候,已有的G2P模型无法很好的将其与英文区分开,并标注正确的发音,并且这些工具比较复杂。因此,本文在已有工作[1,2,3]基础上,使用一种端到端G2P模块简化了模型,提出了一种使用分离音素集(seperated phoneset)训练混读G2P前端的方式,实现英文-印地语混读的方法。
本文重点在于前端,后端合成与已有工作相同,训练数据使用polyglot data。贡献主要有:
- 提出了一种生成印地语音素标注的方法
- 提出了一种混读G2P前端系统,
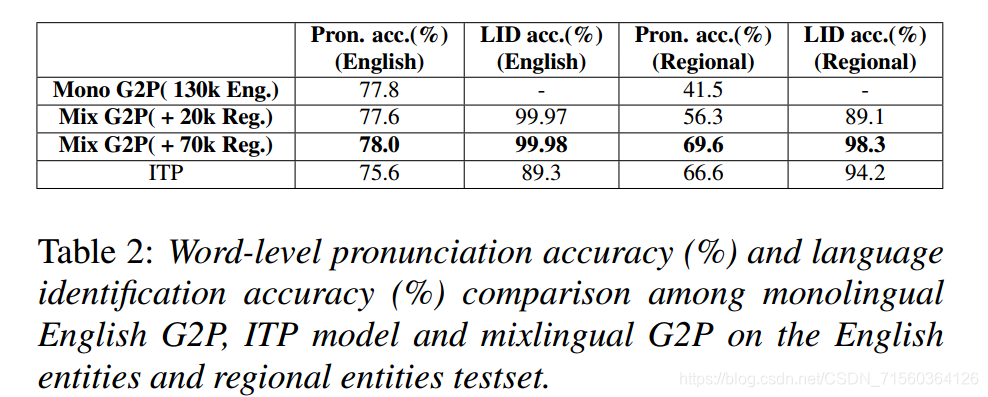
- 实验证明separated honeset比shared phoneset效果更好。
亮点主要还是在于使用transformer作为前端,其他的语种识别等等更偏向于技术实践。
Q&A
Q1 : 为什么要用分开的音素集? 分开的音素集(separated phoneset)是什么样子的?
A1 :
首先,目前的引文G2P模型使用的是英文语料训练(English entities), 在使用组合音素集的时候(全部映射为英文音素),当碰到用罗马字母书写的regional entities(本地单词),表现会很差,这里原因有三:
- regional entities 的读音很多是在英文G2P模型使用的音素(整合)集合之外的
- 书写错误。regional entities的发音规则跟英文发音规则不同,用English entities训练的G2P模型,不能转换出正确的发音
- 英语语言的非音标性。
其次,关于seperated phonset。相对应的combine honeset 或者 shared phoneset,指的两种语言,发音相近的,用一种音素表示(映射),不同的,则各自添加到音素集合中。将shared phoneset添加语种前缀,就成为seperated phoneset
Q2 : G2P模块是怎么实现和训练的?
A2 : 语种识别 + 音译策略 + native G2P
Q3 : regional entities 是什么?
A3 : 本文的指定概念,比如英文句子中含有本地语言的单词,改单词就是 regional entities 。
Q4 : 什么是英语语言的非音标性( Non-phonetic nature of the English language )?
系统

该系统包含一个前端和一个合成器,其中前端包含文本正则、英文词典以及一个混读G2P模块(严格来说更像是一个特殊的native G2P模块)。
组成包含:
- 语种识别 : LID model by Gella et al + 170k英文词典
- 音译策略 : Brahmi-net transliteration (http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.703.1218 该模型的训练语料来自微软azure认知服务
- native G2P : 印地语发音生成器使用的是一个基于transformer的结构实现。
处理流程如图所示:
- 输入文本首先使用英文词典查询,成功则输出发音并标注‘en_’前缀
- 否则,文本输入到混读G2P前端,输出发音,并标记‘hi_’前缀。
- 对于多音字 ( language-polyphony), 指的是印地语写成罗马字母时,与英文已有单词完全相同,但是读音不同。此时需要维护一个列表,
Ref
- [1] S. K. Rallabandi and A. W. Black, “On Building Mixed Lingual Speech Synthesis Systems.” in INTERSPEECH, 2017, pp. 52–56
- [2] K. R. Chandu, S. K. Rallabandi, S. Sitaram, and A. W. Black,“Speech Synthesis for Mixed-Language Navigation Instructions.” in INTERSPEECH, 2017, pp. 57–61
- [3] A. L. Thomas, A. Prakash, A. Baby, and H. A. Murthy, “Codeswitching in Indic speech synthesisers.” in Interspeech, 2018, pp.1948–1952
这篇关于On Improving Code Mixed Speech Synthesis with Mixlingual Grapheme-to-Phoneme Model的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





