phoneme专题

PhoneME简介(翻译)
PhoneME简介(翻译) 作者:陈跃峰 出自: http://blog.csdn.net/mailbomb phoneME Feature software是一个优化了的Java ME架构。它的核心是支持多任务的MIDP2.1规范实现。 当phoneME Feature software运行多个MIDlet时,它只使用一个系统进程,因为一个Java虚拟机实例可以执行几个应用,并

《PHONEME-BASED DISTRIBUTION REGULARIZATION FOR SPEECH ENHANCEMENT》论文阅读
ABSTRACT 现存的语音增强方法有时域和频域的方法,但是这些方法啊没有关注过带噪信号里面的语义信息。这篇论文,作者希望借用语义信息能够使得增强的效果更好。因而,提出了一个音素级分布正则化模块PbDr,将帧级语义信息作为条件整合到增强网络里面。频域上不同的音素导致不同的特征分布,通过因素分类模块产生了一个参数对,尺度和偏置。这个参数对不只包括帧级,也包括频域级,能够有效的将特征

【李宏毅2021机器学习深度学习】2-1 Phoneme Classification【hw2】
文章目录 写在前面标准提示:实验记录:1. Sample code2. 数据归一化,添加了BN,大的batch_size由64改为128,修改激活函数为Relu,添加plot_learning_curve工具看loss曲线,3. (overfitting)make model simpler(直接去掉第三层全连接层)4. batch_size直接改为5125. lr = 0.001(默认参数
通过wav文件和text文件训练出phoneme文件的过程
环境:python2.7和python3.6 最近训练的一个神经网络需要wav文件和phn文件作为自己输入。 所有的数据库中都有wav文件,但是phoneme文件却不是每个数据库都有。 TIMIT数据库中就PHN文件。 先贴个PHN文件的图。 SX127.PHN 再看一下这句话的文本。 后面就是这句话没问题,0-24679肯定就是时间了。 我们看到时间是1.543,因为

Fantasy Mix-Lingual Tacotron Version 4: Google-ZYX-Phoneme-HCSI-DBMIX 调整LID
0. 说明 VAE + LID效果目前是最好的, 将LID调整下, 不在decoder拼接LID, 在encoder_output处拼接 1. 枚举方案 有以下方案 speaker emb和residual仍然在decoder拼接, 只LID在前面speaker emb和residual放在前面与否, 仅仅是被query的内容不同; 而根据query为声学特征, memory为文本特征,
On Improving Code Mixed Speech Synthesis with Mixlingual Grapheme-to-Phoneme Model
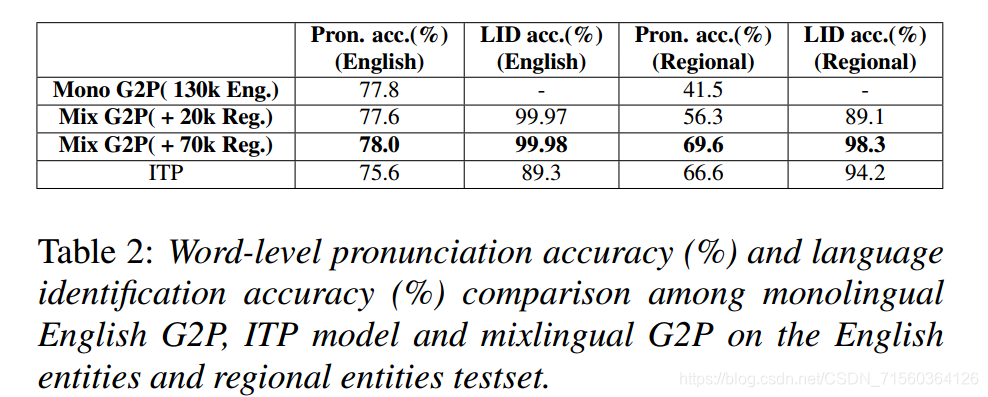
文章出自Microsoft STC India, INTERSPEECH 2020。 本文主要解决的问题在于,针对英文-印度语混读情景,当印地语使用罗马字母拼写的时候,已有的G2P模型无法很好的将其与英文区分开,并标注正确的发音,并且这些工具比较复杂。因此,本文在已有工作[1,2,3]基础上,使用一种端到端G2P模块简化了模型,提出了一种使用分离音素集(seperated phoneset)训练混