本文主要是介绍Beyond action valuation:基于DRL的足球比赛进攻场景评估和决策优化——1.训练过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.数据集
采用某联赛(e.g. 英超联赛)的某一赛季(e.g.2022-2023赛季)的全部比赛,将从联赛层面和球队层面分别训练以给出针对化的建议。
数据由追踪数据(记录了每帧内22名球员和球的[x,y]坐标,每秒记录10次)和事件数据(记录了传球、射门、进球、带球等重要事件,并标注了其它特征(球员、时间戳、球开始位置、球结束位置、事件成功/失败等))组成,需要说明的是,追踪数据的一帧画面被称为“snapshot”。在数据处理上,需要将追踪数据和事件数据合并,合并后数据的每条记录都包括所有球员和球的坐标,以及每次snapshot的相应特征(?如何处理没有交代)。其中,追踪数据的每一帧的信息表示了比赛在这一帧的状态。
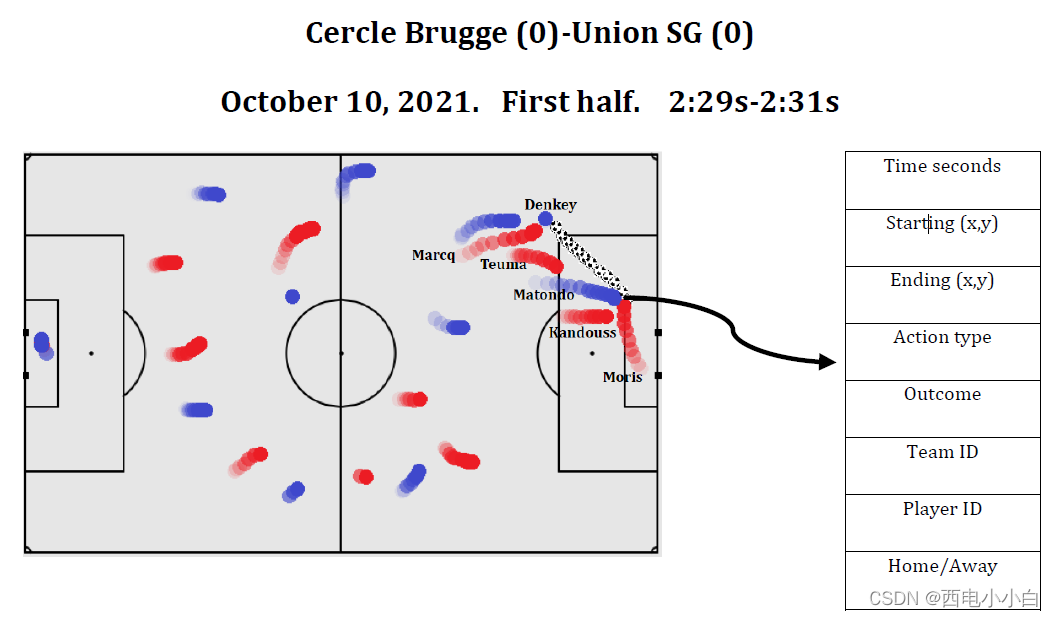
2.对某个进攻场景的建模——概率平面
足球比赛进攻场景中的策略被定义为:在某一状态下(开始控球帧的追踪数据),球队选择行动(将球传往球场任意目的地)的可能性分布。为了表示比赛中任何情况下的策略概率分布,需要评估出两个概率平面:传球选择平面和传球成功平面。传球选择平面展示了给定进攻状态下,球被选择传到球场任意位置的可能性,所有位置值的总和为1,它代表了各队在选择球的目的地位置方面的行为策略。传球成功平面展示了给定进攻状态下,球能成功(控球仍然持续)传到球场任意位置的可能性,每个位置的值在0到1之间。


这两个平面是通过训练策略网络获得的,该网络接收特定比赛情况作为输入,并产生概率平面作为输出。在事件和跟踪数据的基础上构建了策略网络,并使用深度学习技术来解决时空问题的复杂性。下一部分将介绍比赛状态的表示和策略网络架构。
3.状态表示和输入通道
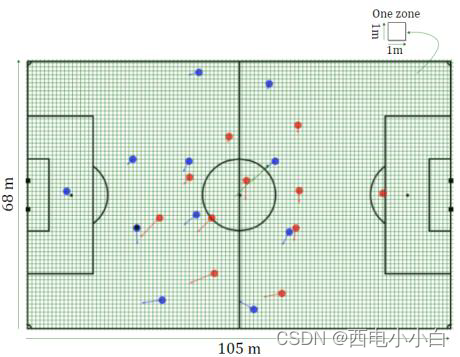
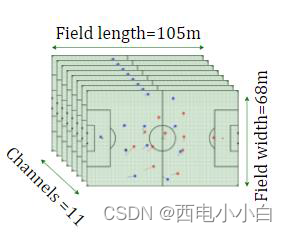
第1节中描述了数据集的每个快照的游戏状态,包括所有球员和球的具体位置(x,y)、相应的速度以及特定事件的各自结果(如传球成功或失误)。为了表示这些信息,我们以适合策略网络的输入格式构建了 11 个输入通道。每个通道都是一个大小为(105×68)的矩阵,分别代表比赛场地的长度和宽度(见下图)。输入数据通道包含比赛场地每平方米的不同类型的低层次信息,以获得特定时间步长下比赛的上下文表示。构建以下输入通道来表示每种游戏状态:
1. InChlt:攻击队球员的位置。每个球员的位置值都设为 1。
2. InChlo:防守方球员的位置。每个球员的位置值都设为 1。
3. InChVxt:进攻方球员速度的 x 分量。
4. InChVyt: 攻击队球员速度的 y 分量。
5. InChVxo:防守方球员速度的 x 分量。
6. InChVyo:防守方球员速度的 y 分量。
7. InChdb: 球到球场上每个位置的欧氏距离。
8. InChdg: 防守方球门到场上每个位置的欧氏距离。
9. InChabg:球场上每个位置的球与球门之间的夹角。
10. InChcosabg:球场上每个位置的球与球门之间夹角的余弦值。
11. InChsinabg:球场上每个位置的球与球门之间夹角的正弦值。
4.策略网络结构
为了推断概率平面和制定策略,我们采用了深度学习技术。我们使用的策略网络是一种神经网络,它将大量博弈状态作为输入,并将概率平面作为输出。
从技术角度看,任何概率平面都包含 105×68=7140 个概率,在特定比赛状态下,球场上每个不相连的区域都有一个概率。在传球选择平面中,所有区域的概率之和等于 1。但是,成功面中每个区域的概率代表的是,如果球被送到该区域,行动成功(即球队保住控球权)的可能性。
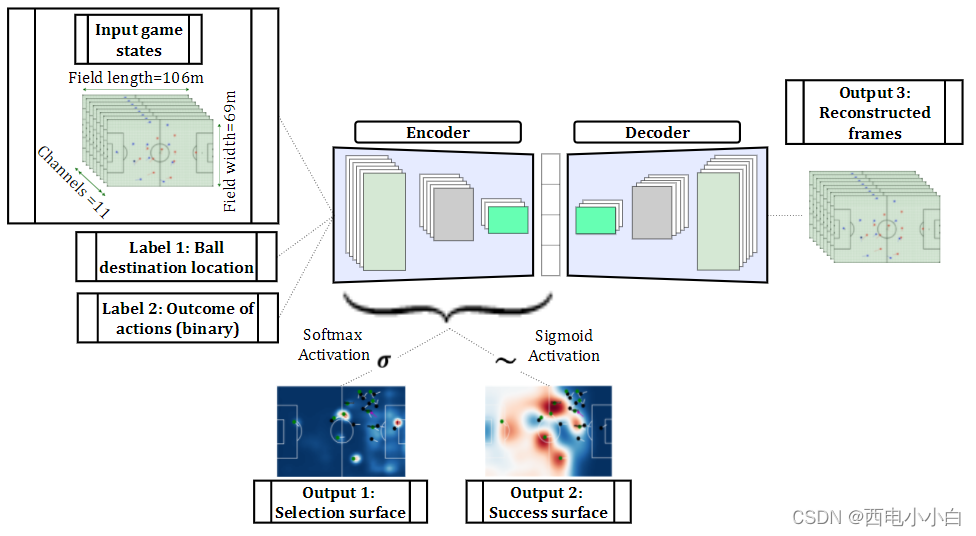
上图展示了产生上述概率曲面的策略网络结构。输入帧序列是上一节所述的输入通道矩阵。策略网络的输出取决于编码器最后一层的设置:将激活函数设置为 softmax 和 sigmoid 将分别产生选择平面和成功平面。输出 1 是选择概率平面,在本文中被视为数据的行为策略。输出 2 是成功平面,表示如果球被送到球场上的每个位置,行动成功的概率。输出 3 是重构的行动序列(新控球),用于模拟网络的学习策略。
5.如何获得一支队伍的最佳优化策略?
到目前为止,我们已经为每种比赛状态准备了选择平面和成功平面。但是,估计出的平面还不够全面,无法帮助球员和教练做出最优决策:
1。选择平面是根据历史比赛的一般策略估计出来的,没有证据表明球队和球员在之前的比赛中做出的决策和策略是最优的。
2.成功平面只显示了球员将球移动到该位置后不失去控球权所获得的短期回报。
目前的分析方法建议通过训练神经网络来预测未来 10 个动作内或实际控球结束时的进球概率,从而估算出价值平面。在本节中,我们将详细介绍我们提出的优化算法,该算法可以直接估算出最优的全概率平面,覆盖场上所有球的目标位置,而不是学习之前比赛中发生的每个离散动作的值。
5.1马尔可夫控球环境
马尔可夫决策过程(MDP)是一个用于连续决策的框架。说到足球控球,由于控球过程中的动作具有连续性,因此我们可以利用这种在 RL 任务中常用的优化技术对控球进行建模。MDP模拟的是在所有 22 名球员和球的当前位置下,持球者传球到球场目标点的选择概率。我们用MDP对足球进行建模的方法需要一些定义明确的要素:(𝑆,𝐴,𝑅,𝜋)组成的元组,其中 𝑆 表示状态集合,𝐴 表示行动集合,𝑅 表示奖励函数,规定了代理在任何给定状态/行动对中获得的奖励,而 𝜋 表示策略,解释为智能体根据当前环境状态采取任何给定行动的概率。
现在,我们可以在我们的足球控球环境中定义这些组成部分:
Episode (𝝉): 每一个Episode都从控球一方的第一次控球事件开始,以进球或控球失利并转移给对手结束。由于足球比赛中的控球没有统一的定义,因此我们将控球定义为:从一队的持球动作开始,直到进球或连续两次以上将球输给对方的一系列动作。因此,当对方球员连续触球次数少于三次时,我们不将它视为失去控球权。射门失败后的反弹球、出界球和犯规如果在接下来的三个动作中被球队争抢回来,则不视为失去控球权。
State (𝒔): 状态由球员和球的位置以及之前描述的任何比赛情况下的其他输入通道组成。有两种被排除的状态即:进球和失球,也就是控球结束的定义。
Action space (𝒂): 我们使用两种类型的动作空间。首先,考虑连续的动作空间,其中动作被定义为持球者在场上选择将球移动到的具体位置。其次,出于可解释性和可说明性的考虑,我们将动作空间离散化为回传、向前传球、左右传递和射门。
Policy (𝝅): 我们将策略定义为在当前状态下,持球者选择场上任何特定位置作为球的目的地的概率。
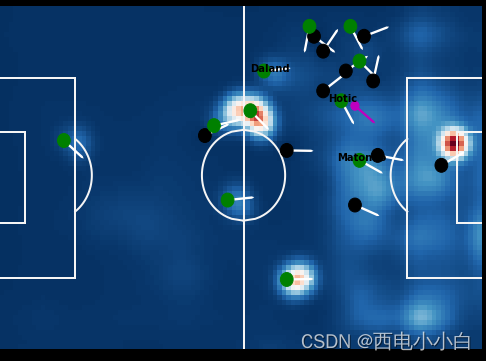
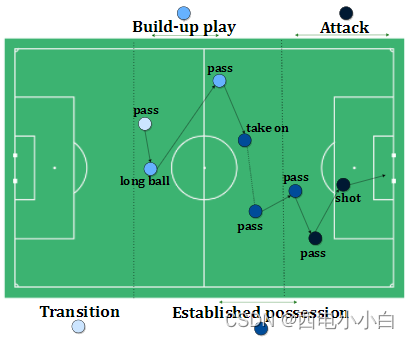
Reward signal (𝑹(𝒔,𝒂)): 足球比赛的主要奖励来自于赢得比赛。然而,这样的奖励信号对于学习优化策略的智能体来说过于稀疏。因此,我们需要手工制作奖励函数,以鼓励在不同比赛场景下的相对行为。由于足球比赛不同进攻阶段的目标不同(即非稳态策略),我们的奖励工程方法在不同阶段应用了不同的奖励函数,目的是将比赛的战术特点纳入其设计中。根据 Opta 控球框架将每次控球分成几个比赛阶段(见下图),根据事件在场上的位置以及前后发生的情况对事件进行标记。
我们对成功的行动(即保持控球的行动)给予正奖励,对不成功的行动(即导致失去控球的行动)给予负奖励。对于不成功的行动,我们使用对手射门的预期进球值(xG)的负值作为奖励函数,对于成功的行动,我们为四个不同的控球阶段分别使用一个定制的正奖励函数:
1. Transition phase: 从控球开始(即从防守转入进攻)到球员完成第一次成功传球或丢失控球(对手三次及以上控球)。
目标: 将球远离身体接触,改变channel区域 (即在防守、中场和进攻之间形成的区域)。
奖励函数: 首先,我们根据对手的位置和速度,使用 K-Means 算法将其聚类为三个压力线。然后,我们将更高的奖励分配给使球远离聚类中心点的动作,以及成功概率较高的位置(𝑃𝑠𝑢𝑐𝑐𝑒𝑠𝑠)。

2. Build-up play phase:从本方半场(包括守门员和后卫)开始,直到球到达对方半场。
目标: 寻找机会突破对方中场线。
奖励函数: 取决于比赛特定时刻的比分差距。如果进攻方的比分小于或等于防守方的比分,目标就是尽快移动到进攻阶段,创造得分机会。因此,将球转移到球场上成功概率最大且更靠近中场线的位置,应该会得到更好的回报。
在进攻方得分高于防守方的情况下,他们倾向于尽可能长时间地控球,而得分并不是最优先考虑的事情。因此,我们只考虑将成功概率作为这些行动的奖励。

3. Established possession phase: 从对方半场的第一次传球开始,直到在进攻三区有连续两次以上的动作。
目标: 保留控球权(即避免控球权丢失)。
奖励功能: 我们为将球移动到球场上成功概率最高的位置的动作分配更大的奖励。

4. Attacking play phase: 在进攻三区控制球权。
目标:创造机会和进球。
奖励功能: 我们为将球移动到球场上成功概率更高、预期进球价值更大的位置的行为分配更大的奖励。
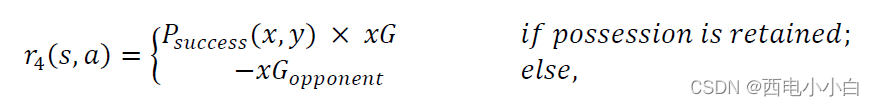
其中,xG是给定当前射门位置和场上所有球员位置时,评估射门质量的攻击队的预期进球值。为了估算球场上每个位置的xG,我们通过数据集中所有射门的输入通道及其标签(即是否进球),定制策略网络的最后一层,可以计算出任意比赛状态下的𝑥𝐺(?如何实现)。
5.2 预期控球结果(EPO)
到目前为止,我们已经根据数据集中每个动作在控球过程中出现的阶段为其分配了奖励。然而,奖励最高的动作并不一定是球员可以执行的最佳动作,因为分配的奖励只估计了短期的成功,而没有考虑控球结束时会发生什么(即进球或失去控球权)。为了解决这个问题,我们引入了 "预期控球结果"(EPO)的概念,我们从 RL 算法中的discounted rewards中获得了灵感。
EPO 是归一化后的实数值,取值范围为 (-1,1)。我们将该值解释为各次控球最终导致进攻队进球(1)或对方进球(-1)的可能性。
假设数据集包含𝑁个控球片段,,以及一个H步控球片段(由 H 个行动组成的持球),
,其中的行动遵循策略网络估计的策略𝜋,则 EPO 可表述为:
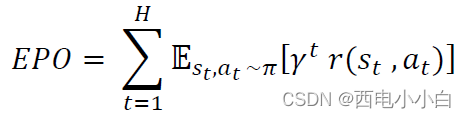
其中,𝑟(𝑠𝑡 ,𝑎𝑡)是连续动作𝑎𝑡(即球在场上的目标位置)的指定奖励,该奖励是根据上一节所述的发生阶段给定状态𝑠𝑡的;𝛾是折扣因子,将其设为 0.99。EPO 可以解释为:通过控球之后的奖励加权总和鼓励行动样本的力度。如果持球一直持续到attacking phase,则最后一次行动的奖励与xG相关联。因此,EPO 显示了控球最终进球的可能性,可视为我们的优化框架要最大化的目标函数。
5.3 策略梯度:在球场上如何做才能最大限度地增加进球数?
为了能使控球导致进球尽可能地多,我们需要为数据集中的所有比赛确定能使4.3中EPO最大化的行动。由于在现实世界中进行实验来寻找最优策略几乎是不可能的,因此 RL 可以帮助我们寻找最优解。为此,我们利用了策略梯度(PG)算法。由于我们的目标是估计最优策略(选择平面),因此 PG 算法是优化的最佳选择:我们的足球分析问题正好属于off-policy PG方法。在这种方法中,代理只从历史数据中学习,而不与环境进行在线交互。
策略网络可以稳健地估计选择概率平面,我们称之为行为策略,表示为𝜋𝜃,其中𝜃是产生行为策略的网络参数向量。现在,我们的目标是使用off-policy PG算法来调整网络参数,以产生最优选择概率面,表示为𝜋𝜃∗,其中𝜃∗是在当前状态下产生最优选择概率面的调整网络参数向量。网络的梯度告诉我们,如果我们想鼓励未来的任何决策(行动),网络应该如何修改参数。我们会根据每个行动的最终结果来调节每个行动的损失,因为我们的目标是提高成功行动(奖励更高)的概率,而降低失败行动的概率。我们借助梯度向量来训练策略网络,梯度向量会鼓励网络略微提高获得大量正奖励的行动的可能性,降低负奖励的可能性。在非策略 PG 算法中,梯度的定义如下式所示:
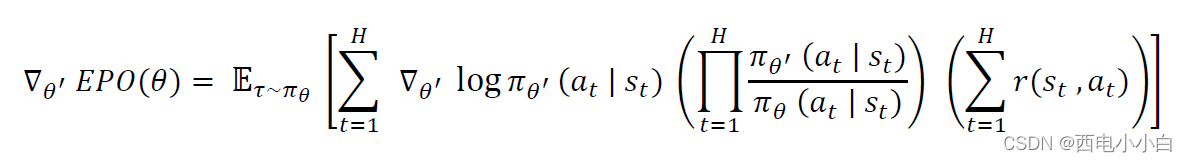
其中,𝜃 是行为策略网络的参数向量(产生行为概率曲面),𝜃′ 是修正策略网络的参数向量,必须经过训练才能产生最优概率曲面。梯度向量是计算参数空间方向的梯度,它能改变场上每个位置的选择概率。因此,奖励高的行动比奖励低的行动对概率密度的影响更大。因此,off-policy PG 算法有助于概率密度向高回报行动的方向移动,使其更有可能发生。策略梯度算法伪代码如下:

这篇关于Beyond action valuation:基于DRL的足球比赛进攻场景评估和决策优化——1.训练过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




