drl专题

【王树森】深度强化学习(DRL)学习笔记
目录 第一部分:基础知识1.机器学习基础2.蒙特卡洛估计3.强化学习基础知识3.1 马尔科夫决策过程马尔可夫决策过程(Markov decision process,MDP)智能体环境状态状态空间动作动作空间奖励状态转移状态转移概率 3.2 策略策略定义 3.3 随机性的来源随机性的两个来源马尔科夫性质(无后效性)轨迹 3.4 回报与折扣汇报回报折扣回报回报中的随机性 3.5 价值函数动作-
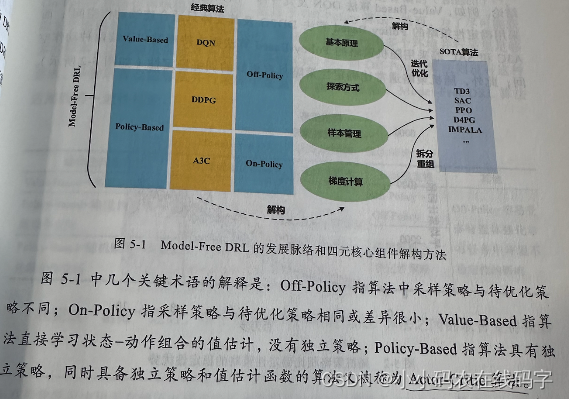
【强化学习-Mode-Free DRL】深度强化学习如何选择合适的算法?DQN、DDPG、A3C等经典算法Mode-Free DRL算法的四个核心改进方向
【强化学习-DRL】深度强化学习如何选择合适的算法? 引言:本文第一节先对DRL的脉络进行简要介绍,引出Mode-Free DRL。第二节对Mode-Free DRL的两种分类进行简要介绍,并对三种经典的DQL算法给出其交叉分类情况;第三节对Mode-Free DRL的四个核心(改进方向)进行说明。第四节对DQN的四个核心进行介绍。 DRL的发展脉络 DRL沿着Mode-Based和Mode
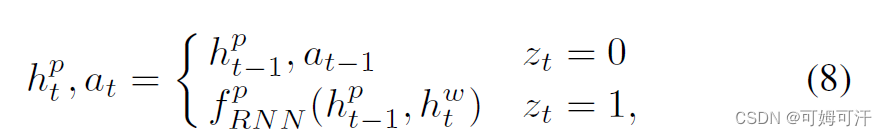
Paper Note | Efficient DRL-Based Congestion Control With Ultra-Low Overhead
文章目录 IntroductionDesignRL AgentCC ExecutorHierarchical Recurrent Architecture Introduction 深度强化学习能够用于网络拥塞控制决策中,但是之前的DRL方案耗时且占用了很多CPU资源。这篇文章提出了一种低开销的DRL方案,实现细粒度的包级别控制。 SPINE采用了层次控制架构,包含一个轻量级

20180509-Allegro16.6 drl钻孔文件导入CAM350报No header % found,load stoppd错误
1.如果在drl文件导入CAM350进行查看的过程出现如下错误,说明PCB板内包含槽孔。Allegro16.6生成的rou文件,包含1个%,引起的这个错误。 2.打开unamed.rou文件,可以在第6行看到有一个%,将其删除,即可解决该问题。

深度强化学习(DRL)算法系列文章合集
1. 深度强化学习(DRL)算法 1 —— REINFORCE 2. 深度强化学习(DRL)算法 2 —— PPO 之 Clipped Surrogate Objective 篇 3. 深度强化学习(DRL)算法 2 —— PPO 之 GAE 篇 4. 深度强化学习(DRL)算法 3 —— Deep Q-learning(DQN) 5. 深度强化学习(DRL)算法 4 —— Deep De

Drools入门-----------环境搭建,分析Helloworld Drools5.0的xls文件转drl文件提升解析效率 使用BRMS的Tomcat6.0配置
http://justsee.iteye.com/blog/1198259 Drools官网:http://www.jboss.org/drools Drools and jBPM consist out of several projects:(Drools软件包提供的几个部分的功能) Drools Guvnor (Business Rules Manager) (规则集管理器)
基于CLIP4Clip的DRL的WTI模块实现
关于DRL的WTI模块: Weighted Token-wise Interaction: 直觉上,并非所有的单词和视频帧都同等重要。我们提供一种自适应方法,来调整每个标记的权重大小: 注:其中两个f函数都是MLP和softmax构成。 WTI的算法流程图: 输入video和text之后分别通过encoder,得到representation之后使用fusion weights网络计算权
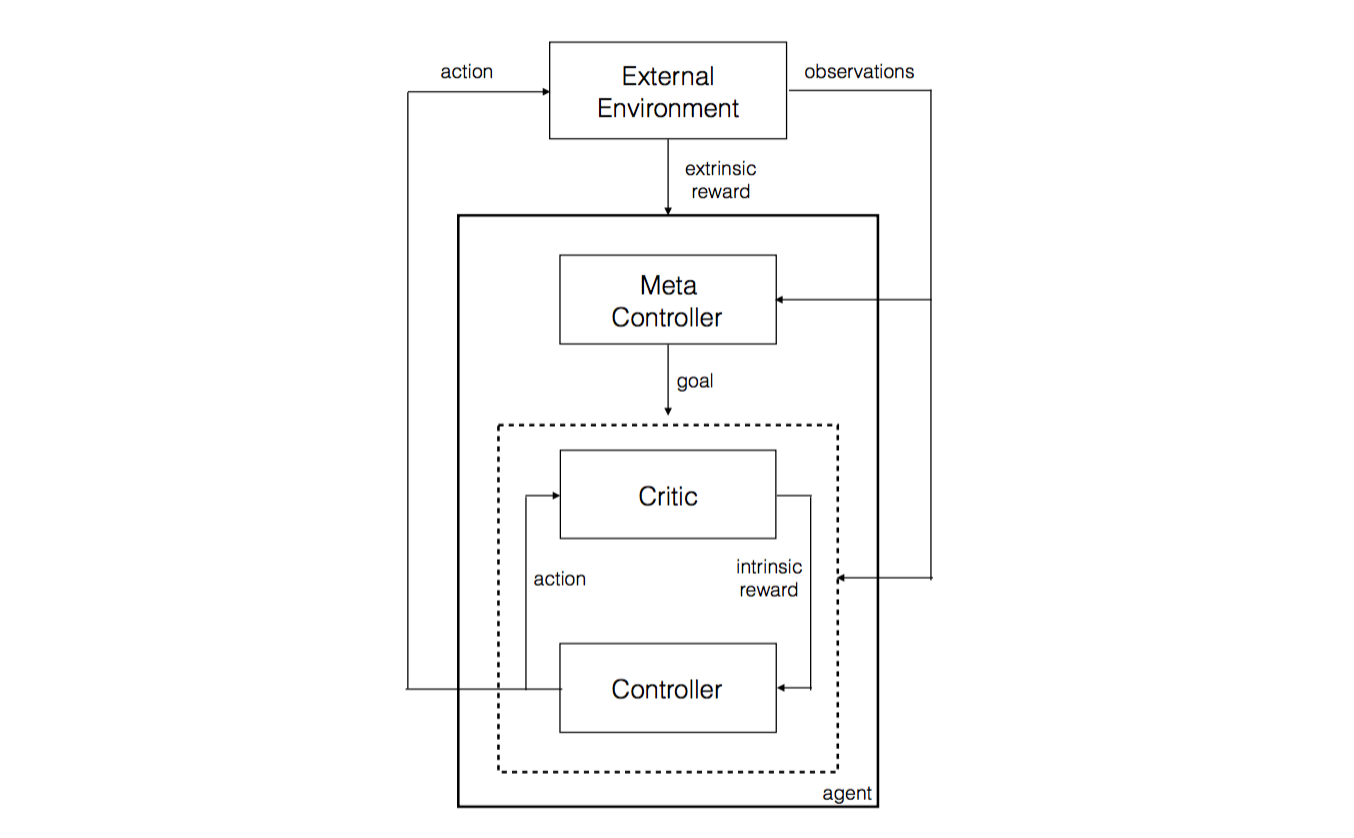
DRL前沿之:Hierarchical Deep Reinforcement Learning
1 前言 如果大家已经对DQN有所了解,那么大家就会知道,DeepMind测试的40多款游戏中,有那么几款游戏无论怎么训练,结果都是0的游戏,也就是DQN完全无效的游戏,有什么游戏呢? 比如上图这款游戏,叫做Montezuma’s Revenge。这种游戏类似超级玛丽,难在哪里呢?需要高级的策略。比如图中要拿到钥匙,然后去开门。这对我们而言是通过先验知识得到的。但是很难想象计算机如何仅仅通
使用DrlParser 检测drl文件是否有错误
为避免运行时候错误,drools 7 可以使用DrlParser预先检测 drl文件是否正常。 parser 过程通常不会返回异常ruleDescr = parser.parse(resource); 为空代表有异常 具体测试代码如下: public class DrlParserTest {public static void main(String[] args) {// 定义规则文件内

DRL应用实战(一)——开发德州扑克RL智能体【附代码】
1 pettingzoo德州扑克-无限制版 游戏规则 观测空间:一个54维的向量,每一维取值为0或1,1表示出现,0表示没出现。 索引含义取值0~12黑桃A~K[0,1]13~25红心A~K[0,1]26~38方块A~K[0,1]39~51梅花A~K[0,1]52玩家1下注的总筹码1~10053玩家2下注的总筹码1~100 动作空间:一个6维的向量,每一维取值为0或1,1表示选择该动作
DRL基础(一)——强化学习发展历史简述
【摘要】介绍强化学习的起源、发展、主要流派、以及应用。强化学习理论和技术很早就被提出和研究了,属于人工智能三大流派中的行为主义。强化学习一度成为人工智能研究的主流,而最近十年多年随着以深度学习为基础的联结主义的兴起,强化学习与之结合后在感知和表达能力上得到了巨大提升,在解决某些领域的问题中达到或者超过了人类水平。在围棋领域,基于强化学习和蒙特卡洛树搜索的AlphaGo打败了世界顶级专业棋手;在视

Beyond action valuation:基于DRL的足球比赛进攻场景评估和决策优化——1.训练过程
1.数据集 采用某联赛(e.g. 英超联赛)的某一赛季(e.g.2022-2023赛季)的全部比赛,将从联赛层面和球队层面分别训练以给出针对化的建议。 数据由追踪数据(记录了每帧内22名球员和球的[x,y]坐标,每秒记录10次)和事件数据(记录了传球、射门、进球、带球等重要事件,并标注了其它特征(球员、时间戳、球开始位置、球结束位置、事件成功/失败等))组成,需要说明的是,追踪数据的一帧画面被