本文主要是介绍DRL前沿之:Hierarchical Deep Reinforcement Learning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 前言
如果大家已经对DQN有所了解,那么大家就会知道,DeepMind测试的40多款游戏中,有那么几款游戏无论怎么训练,结果都是0的游戏,也就是DQN完全无效的游戏,有什么游戏呢?

比如上图这款游戏,叫做Montezuma’s Revenge。这种游戏类似超级玛丽,难在哪里呢?需要高级的策略。比如图中要拿到钥匙,然后去开门。这对我们而言是通过先验知识得到的。但是很难想象计算机如何仅仅通过图像感知这些内容。感知不到,那么这种游戏也就无从解决。
那么这篇文章:
Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
时间:2016年4月20号
来源: arXiv.org
尝试解决这种问题。
2 文章思路
它的思路很简单,就是弄一个两个层级的神经网络,顶层用于决策,确定下一步的目标,底层用于具体行为。
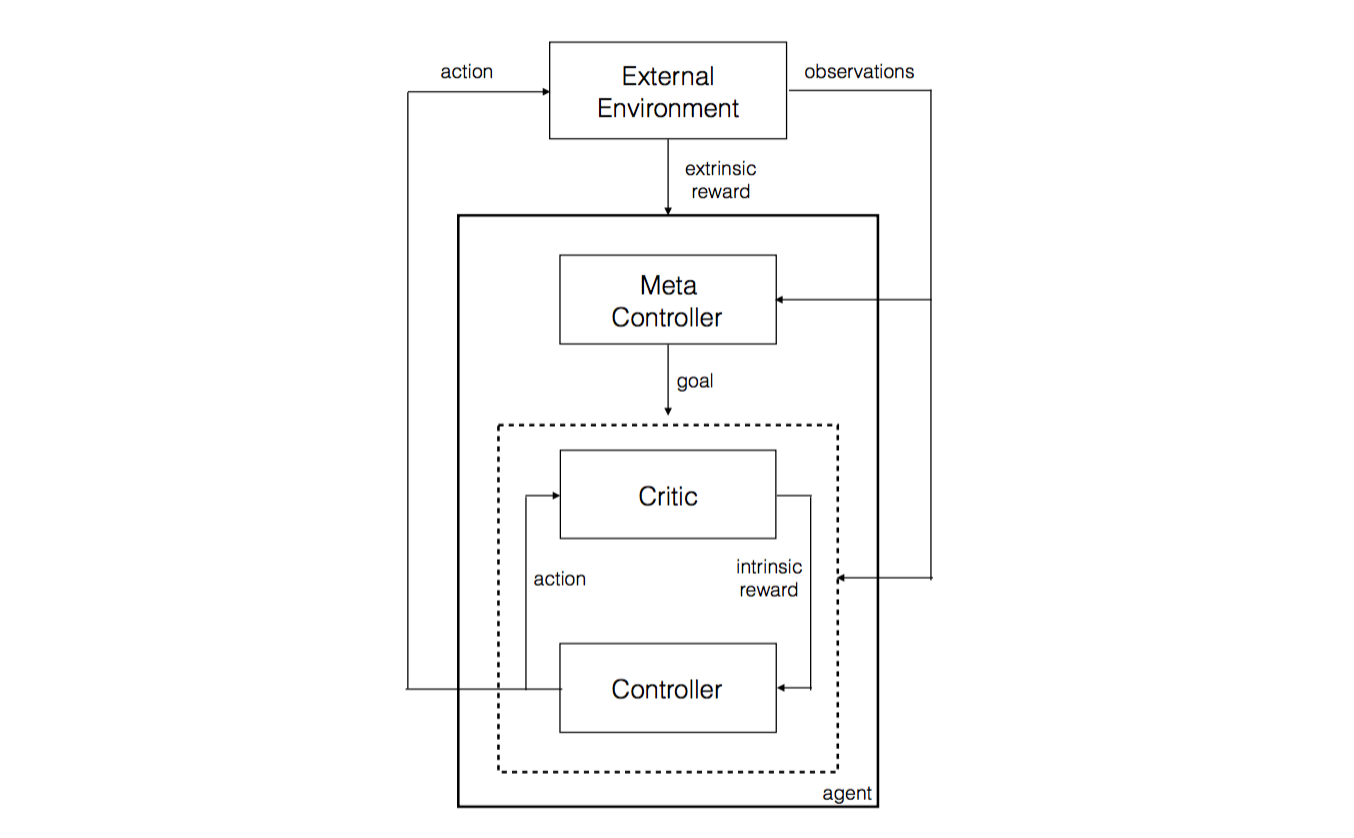
不得不说,这个想法显而易见(本人也想过啦)但是,问题的关键是
如何确定内在的目标??&
这篇关于DRL前沿之:Hierarchical Deep Reinforcement Learning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








