本文主要是介绍【deepspeed】 gpt模型训练报错run_clm_no_trainer.py: error: unrecognized arguments: --local-rank=0,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
测试场景:使用deepspeed框架训练gpt模型
问题:
报错torch.distributed.elastic.multiprocessing.errors.ChildFailedError
具体见截图:
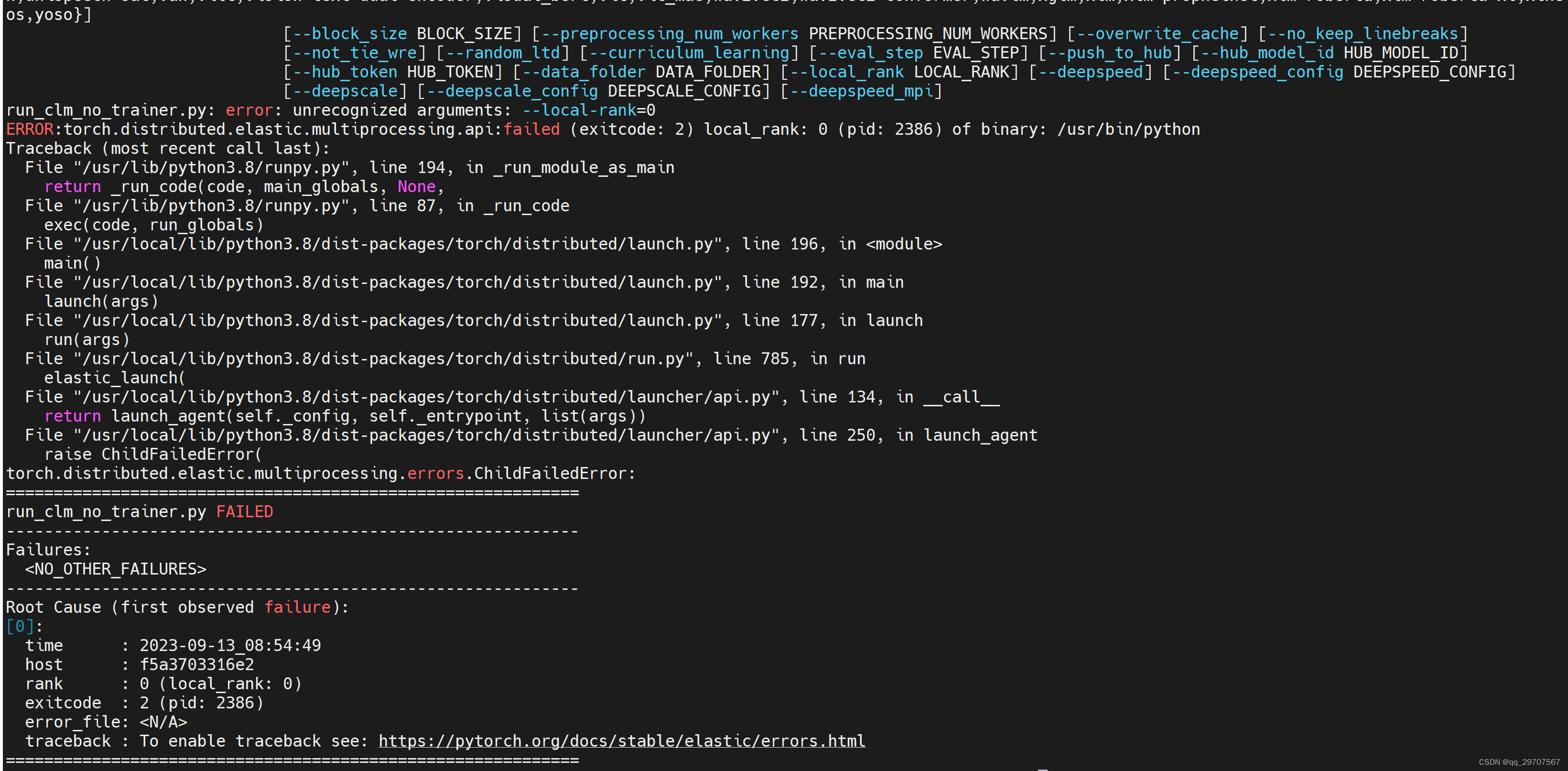
解决办法:
含义:表明在运行 train.py 脚本时,传递了一个未被识别的参数 --local-rank=1
这里我在train.py脚本文件中果然没有找到–local-rank参数,在很多的parser.add_argument后添加一行parser.add_argument(“–local-rank”, type=int),注意在最后添加而不是刚开始,如果刚开始添加会导致传入参数不匹配而报错。
添加的代码参考: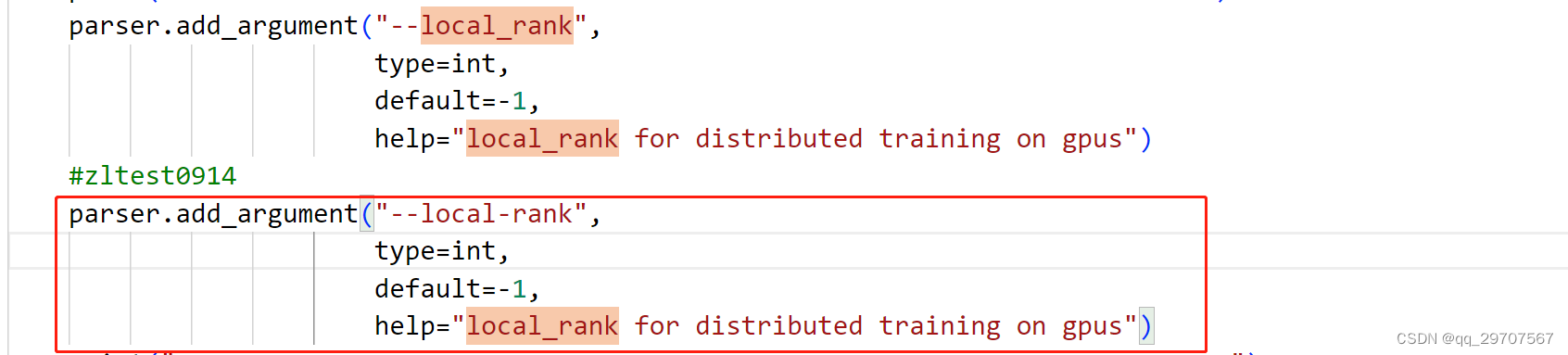
参考文章:
干些这位网友热心分享:unrecognized arguments: --local-rank=1报错解决_幸运的悦子的博客-CSDN博客
这篇关于【deepspeed】 gpt模型训练报错run_clm_no_trainer.py: error: unrecognized arguments: --local-rank=0的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








