本文主要是介绍mantranet:manipulation tracing network for detection and localization of image forgeries,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
[论文笔记] 篡改检测:ManTra-Net - 知乎[论文笔记] ManTra-Net: Manipulation Tracing Network For Detection And Localization of Image Forgeries With Anomalous Features说在前面个人心得: Manipulation其实就是意味着对图像进行篡改或者说操作 讲…![]() https://zhuanlan.zhihu.com/p/266157561这篇文章是比较细的,对影响篡改检的的clue进行了比较细的讨论,clue其实和篡改类型还是相关的。写的其实挺好的,有两个点
https://zhuanlan.zhihu.com/p/266157561这篇文章是比较细的,对影响篡改检的的clue进行了比较细的讨论,clue其实和篡改类型还是相关的。写的其实挺好的,有两个点
1.篡改类型
JPEG compression,edge inconsistences,noise pattern,color consistency,visual similarity,exif consistency and camera model.

2.网络结构
mantranet核心是把篡改检测问题当成局部异常检测问题来做,设计一个z分数特征来捕获异常,并提出一种新的lstm来评估异常区域。
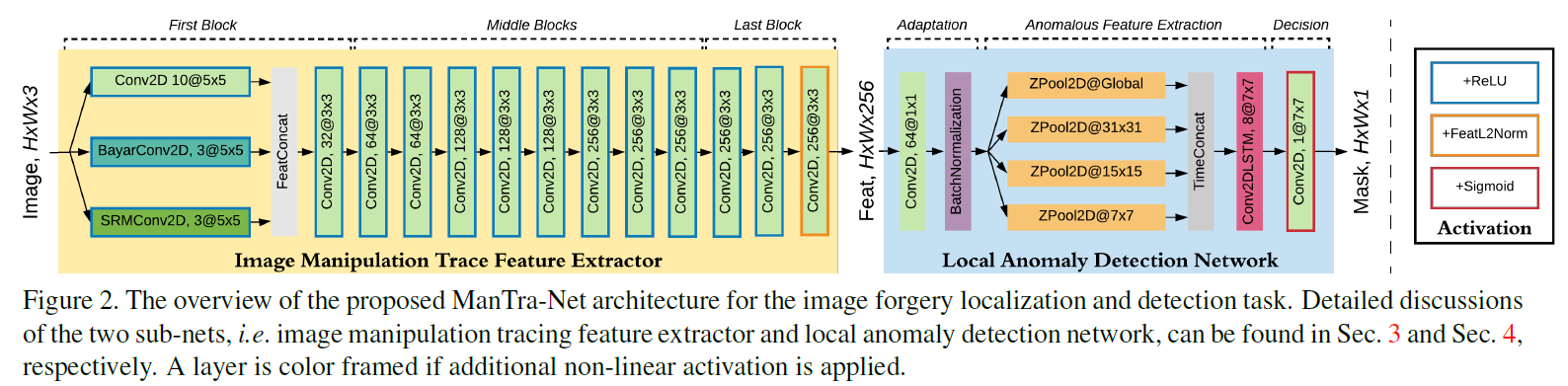
文中有关于这么设计的思路,首先特征提取层是一个vgg16,后面接一个local anomaly detection network,最后还是bce loss,算是标准的语义分割问题,不过也讨论了BayerConv2d是一种约束卷积层的方式,可以抑制图像痕迹的影响,自适应提取图像的篡改特征。SRMConv2D是隐写分析的滤波器,利用srm层提取的噪声特征来发现真实和篡改区域之间的噪声不一致。这些属于在结构上的优化设计,在后续的天池的篡改比赛中,在文档场景也有提出了这些clue设计的滤波器其实是效果不太好的,并不能针对特定场景有比较好的效果。其次,mvssnet中也说了把篡改检测问题单纯建模成语义分割问题是次优,需要有针对性的设计网络。
核心来讲一下local anomaly detection network,首先由一个并行的zpool2d模块,这块的设计思路是:1.什么是主要特征如何计算,2.如何量化局部特征和参考知己难得差异。
class Zpool2D_Window(nn.Module):def __init__(self, inputChannels, window_size_list, min_value=1e-5) -> None:super().__init__()self.min_value = min_valueself.window_size_list = window_size_listself.maxWinSize = np.max(window_size_list)self.TinyWeight = nn.Parameter(torch.full([1,1,inputChannels,1,1], min_value, dtype=torch.float32) ,requires_grad= True)self.TinyWeight.data.clamp(min=0)def _init_padding_buff(self, x): # include Cumulate sumpaddingLayer = nn.ZeroPad2d(self.maxWinSize//2 + 1)x_pad = paddingLayer(x)x_cum = torch.cumsum(x_pad, 2)x_cum = torch.cumsum(x_cum, 3)return x_cumdef _compute_a_window_avg(self, x, winSize):# --left top Big square block-- coordinatetop = self.maxWinSize // 2 - winSize // 2bottom = top + winSizeleft = self.maxWinSize // 2 - winSize // 2right = left + winSize Ax, Ay = (left, top)Bx, By = (right, top)Cx, Cy = (right, bottom)Dx, Dy = (left, bottom)# negative number , but can be parse to a positve when using fomula like this -> [:-1]# --right bottom Big square block-- coordinatetop0 = -self.maxWinSize // 2 - winSize // 2 - 1bottom0 = top0 + winSize left0 = -self.maxWinSize // 2 - winSize // 2 - 1 right0 = left0 + winSizeAx0, Ay0 = (left0, top0)Bx0, By0 = (right0, top0)Cx0, Cy0 = (right0, bottom0)Dx0, Dy0 = (left0, bottom0)counts = torch.ones_like(x)# print(counts)counts_pading = self._init_padding_buff(counts)# print(counts_pading)x_padding = self._init_padding_buff(x)counts_2d = counts_pading[:,:,Ay:Ay0, Ax:Ax0] \+ counts_pading[:,:,Cy:Cy0, Cx:Cx0] \- counts_pading[:,:,By:By0, Bx:Bx0] \- counts_pading[:,:,Dy:Dy0, Dx:Dx0]sum_x_2d = x_padding[:,:,Ay:Ay0, Ax:Ax0] \+ x_padding[:,:,Cy:Cy0, Cx:Cx0] \- x_padding[:,:,By:By0, Bx:Bx0] \- x_padding[:,:,Dy:Dy0, Dx:Dx0]avg_x_2d = sum_x_2d / counts_2dreturn avg_x_2ddef forward(self, x):outputFeature = []# 1. windowfor win in self.window_size_list:avg_x_2d = self._compute_a_window_avg(x, win)D_x = x - avg_x_2doutputFeature.append(D_x)# 2. globalmu_f = torch.mean(x, dim=(2,3), keepdim=True)D_f = x - mu_foutputFeature.append(D_f)# 5 Dim Tensor arrange : (Batch, Diff_Windows, channel, width, height )outputFeature = torch.stack(outputFeature,1) std_x = torch.std(outputFeature, dim=(3,4),keepdim=True)std_x = torch.maximum(std_x, self.TinyWeight + self.min_value / 10.)x = torch.stack([x for i in range(len(self.window_size_list)+ 1) ], dim=1)Z_f = x / std_xreturn Z_fzpool2d的世界遵循了一下的公式:

尽管可以将特征沿着维度串联起来,生成一个3d特征来表示差异特征,但是这并不能模拟人类的决策分析,如果看不清就会靠近一点,因此使用conlstm2d层,异常检测网络按顺序分析属于不同窗口大小的z-score偏差。
3.总结
本文其实还讨论了385中篡改特征数据,但是大部分还是合成数据,比较粗糙,核心就是将篡改检测转成局部异常检测去做,包在一个标准的语义分割的框架中。
这篇关于mantranet:manipulation tracing network for detection and localization of image forgeries的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!