本文主要是介绍深度学习论文: Evaluating You Only Hear Once on noisy audios in the VOICe Dataset及其PyTorch实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深度学习论文: Evaluating You Only Hear Once on noisy audios in the VOICe Dataset及其PyTorch实现
Evaluating robustness of You Only Hear Once (YOHO) Algorithm on noisy audios in the VOICe Dataset
PDF: https://arxiv.org/pdf/2111.01205.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
将YOHO推广应用到 VOICe Dataset
2 VOICe Dataset
- 三种声音类别: “baby crying”, “glass breaking” and “gunshot”
- 两种不同的信噪比: -3dB 和 -9dB
3 YOHO
YOHO的输入是 log-mel spectrograms, 每个声音文件,切割为有重叠区域的长度为2.56s片段,跳长为1.96s. 对于VOICe dataset,模型输入为(40, 257) ,其中 40为mel bins的数量 ,257 为 time steps。
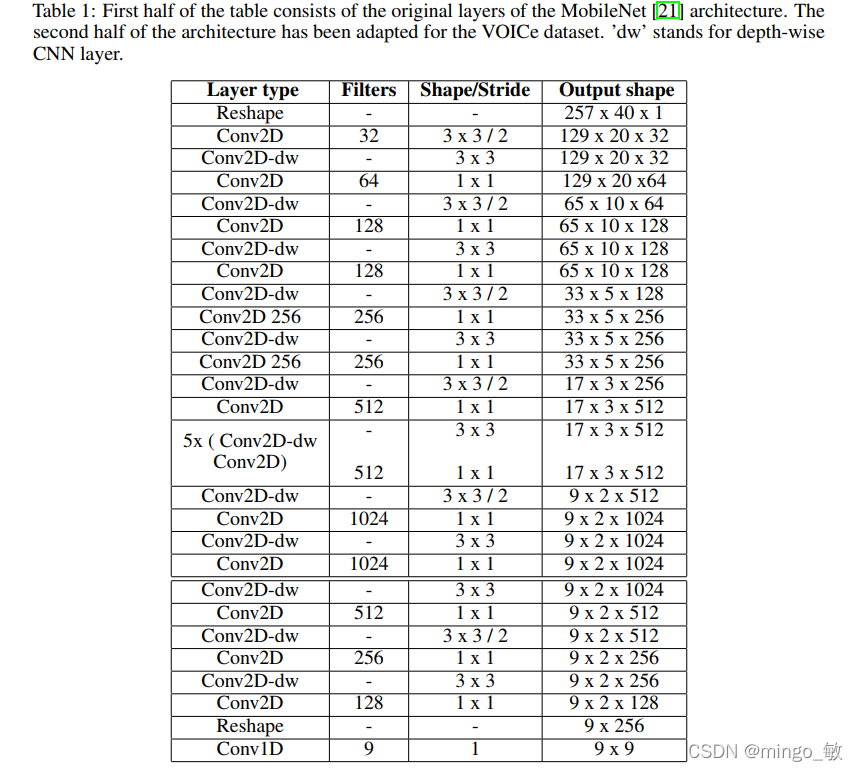
网络的输出尺寸为9x9, 第一维对应时间轴(time axis),第二维对应VOICe数据集的3个类别的3个神经元。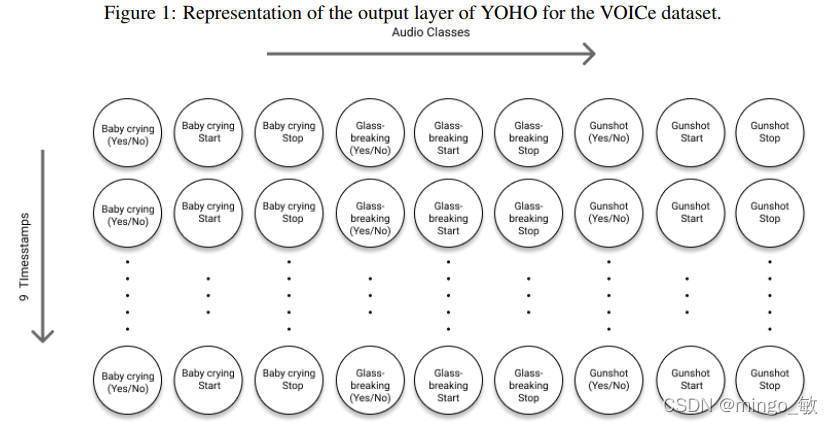
4 Results
Ds 和 Dt 分别表示源(source )和目标(target )域的数据,V. 表示 “vehicle”, O. 表示 “outdoor”, I. 表示 “indoor” , Ce. 表示 “clean” data.


这篇关于深度学习论文: Evaluating You Only Hear Once on noisy audios in the VOICe Dataset及其PyTorch实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


