hear专题

AI在医学领域:谷歌的HeAR生物声学模型
声学非语义属性的语音可以使机器学习模型执行诸如情绪识别、说话者识别和痴呆检测等副语言任务。脑卒中、帕金森病、阿尔茨海默病、脑瘫和肌萎缩侧索硬化症(ALS)等脑血管和神经退行性疾病也可以使用非语义语音模式,如发音、共鸣和发声等来检测和监测。与健康相关的非语义声学信号不仅限于对话语音数据。来自呼吸系统气流的健康相关声学线索,包括咳嗽声和呼吸模式等声音,可以用于健康监测。例如,临床医生使用

Do You Hear What I Hear? Fingerprinting Smart Devices Through Embedded Acoustic Components
摘要 本文研究了使用嵌入在智能手机中的麦克风和扬声器来对单个设备进行唯一指纹识别的可行性。在制造过程中,设备麦克风和扬声器中会出现细微的缺陷,导致产生和接收的声音出现异常。本文利用这一观察结果通过播放和录制音频样本来对智能手机进行指纹识别。 1 介绍 距观察,即使移动设备上的软件得到加强,麦克风和扬声器中的硬件级别特性也可以用来识别物理设备的指纹。在制造过程中,这些组件的模拟电路中会引入缺陷

Hear大数据项目——推荐系统架构与数据模型设计
摘要 第1章项目体系架构设计 1.1 项目系统架构 项目以推荐系统建设领域知名的经过修改过的 MovieLens 数据集作为依托,以某科技公司电影网站真实业务数据架构为基础,构建了符合教学体系的一体化的电影推荐系统,包含了离线推荐与实时推荐体系,综合利用了协同过滤算法以及基于内容的推荐方法来提供混合推荐。提供了从前端应用、后台服务、算法设计实现、平台部署等多方位的闭环的业务实现。 用户可视

攻防世界 Misc Hear-with-your-Eyes
攻防世界 Misc Hear-with-your-Eyes 1.解压压缩包winhex打开 2.Audacity打开切换到频谱图 1.解压压缩包 发现一个无后缀文件 winhex打开 可以看到是一个wav文件直接修改后缀试试发现并不能打开猜测是一个压缩包修改后缀为.zip再试试 2.Audacity打开 切换到频谱图 得到falg
攻防世界Hear-with-your-Eyes
附件下载下来解压是一个wav后缀文件 wav文件介绍 WAV是最常见的声音文件格式之一,是微软公司专门为Windows开发的一种标准数字音频文件,该文件能记录各种单声道或立体声的声音信息,并能保证声音不失真。但WAV文件有一个致命的缺点,就是它所占用的磁盘空间太大(每分钟的音乐大约需要12兆磁盘空间)。它符合资源互换文件格式(RIFF)规范,用于保存Windows平台的音频信息资源,被Wind
xctf攻防世界 MISC高手进阶区 Hear-with-your-Eyes
1. 进入环境,下载附件 是个音频文件,打开听听,妈的差点给我送走了! 2. 题目分析 题目提示用眼睛听这段音频,说的真好,看了看wp,说白是要将音频波形图转成频谱图,在此下载Audacity软件,打开如图: 我们转成频谱图: 得到最终结果 e5353bb7b57578bd4da1c898a8e2d767 3. 还可尝试用AU来转换 传送门:https://www.bilibili

【愚公系列】2021年11月 攻防世界-进阶题-MISC-026(Hear-with-your-Eyes)
文章目录 一、Hear-with-your-Eyes二、答题步骤1.Audacity 总结 一、Hear-with-your-Eyes 文件:攻防世界下载对应文件 二、答题步骤 1.Audacity 附件解压后,是一个无后缀的文件,用winhex打开,发现提示“sound.mav” 猜测这是个压缩文件,要解压,将后缀改为.zip(.rar也行),进行解压后得到wav文
论文-See, Hear and Read: Deep Aligned Representations
See, Hear and Read: Deep Aligned Representations 本paper提出了可以在三种自然模态(视觉,声音,语言)下进行学习的深度判断特征表达,使用Deep Conv Network来进行对齐式的表达学习。 本paper使用的dataset: Cross-Modal Network 目标是对image X 和sound Y学习其对齐之后

攻防世界-Hear-with-your-Eyes
原题 解题思路 是一个没有后缀的文件,题目提示要用眼睛看这段音频,notepad++打开文件,没什么东西。 加后缀zip再解压看看。 使用Audacity打开音频文件

Learning opencv中的一个基于级联的Hear分类器的人脸检测
这是opencv中的一个源程序,基于级联的Hear分类器的 检测效果图: 如果是很多人的话,检测的就不是特别好,会漏检,误检 稍微修改注释后的源代码: #include "stdafx.h"#include "cv.h"#include "highgui.h"#include <stdio.h>#include <stdlib.h>#include <stri

深度学习论文: Evaluating You Only Hear Once on noisy audios in the VOICe Dataset及其PyTorch实现
深度学习论文: Evaluating You Only Hear Once on noisy audios in the VOICe Dataset及其PyTorch实现 Evaluating robustness of You Only Hear Once (YOHO) Algorithm on noisy audios in the VOICe Dataset PDF: https://arx

行为树插件学习--一些问题的解决--can see/hear_02
can see obj检测不到 排查: 1.两个collider和一个rigidbody都有,满足基本碰撞条件 2.树的执行优先级正确(运行时任务由圆圈圈住,表示一直在监测任务) 3.再次运行场景尝试,发现玩家角色起跳时候,can see 返回true,这就可能是投放出来的射线有问题(玩家太矮,看不到?),调整一下can see obj里的offset结果就能正常看到了。 can hear ob

攻防世界--Hear-with-your-Eyes
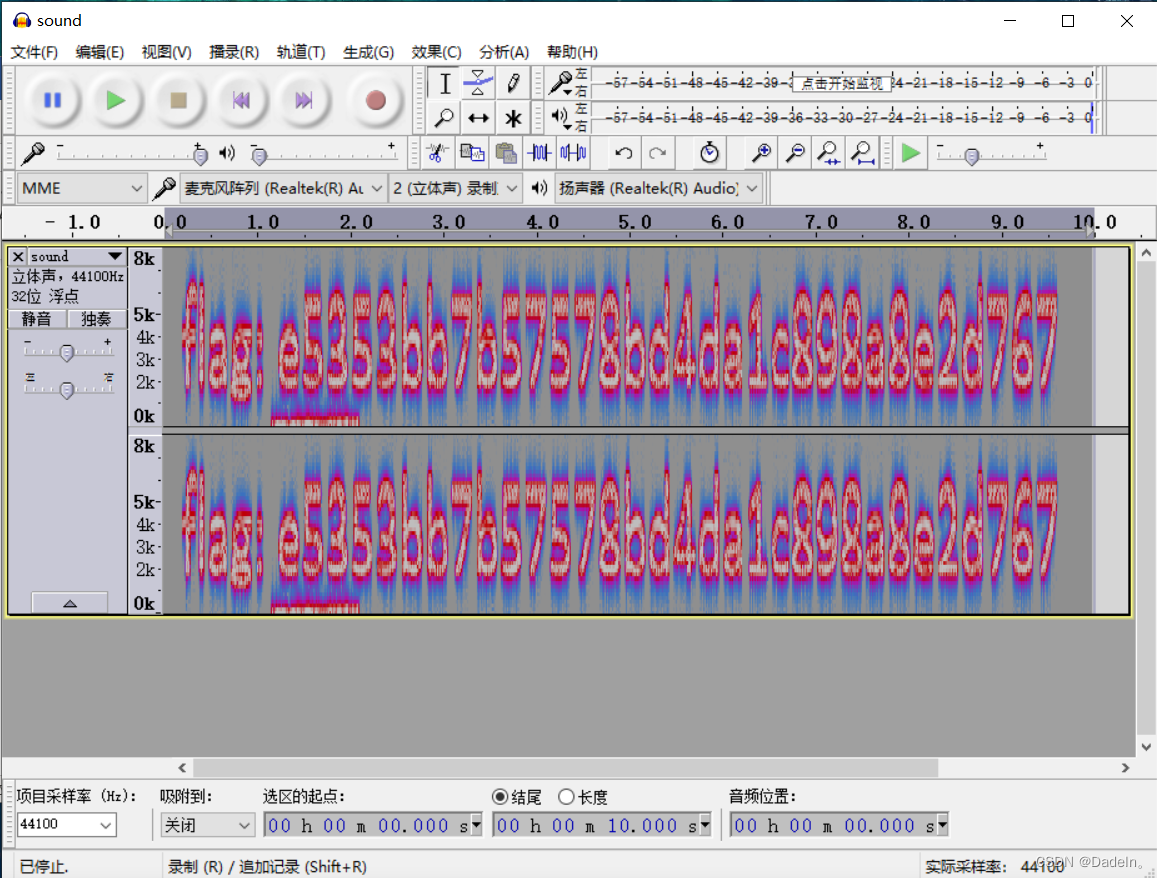
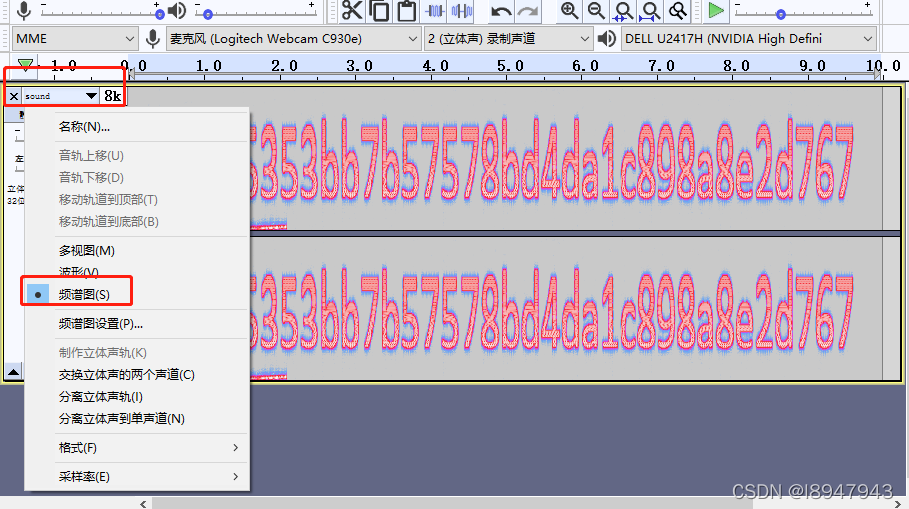
Hear-with-your-Eyes 题目来源: su-ctf-quals-2014 题目描述:用眼睛听这段音频 附件解压后,是一个无后缀的文件,用winhex打开,发现提示“sound.mav” 猜测这是个压缩文件,要解压,将后缀改为.zip(.rar也行),进行解压 用Audacity打开这个mav文件,切换到频谱图(PS:文件名sound旁边有个倒三角形,点一下,再选中频谱图)

攻防世界 Misc高手进阶区 2分题 Hear-with-your-Eyes
前言 继续ctf的旅程 攻防世界Misc高手进阶区的2分题 本篇是Hear-with-your-Eyes的writeup 发现攻防世界的题目分数是动态的 就仅以做题时的分数为准了 解题过程 下下来一个无后缀文件 扔进winhex看看 意思是里面有个sound.wav 修改后缀为zip 解压 得到wav文件 扔进Audacity 切换到频谱图 得到flag 结语 音频


攻防世界MISC进阶区之Hear-with-your-Eyes
下载所给附件,用winhex打开,发现是个wav文件,果然修改文件扩展名为.rar 会发现有一个音频文件,我们用audacity打开,选择左上方的sound选项,找到其中的频谱图,就会得出答案直接输入flag后边的内容就完成了。