evaluating专题

关于undefined is not an object(evaluating 'HotUpdate.downloadRootDir')错误的解决办法
讨论,这是react-native中文网的官网的回答,我再次补充一点。 有很多开发者用了下面的命令成功了发现运行还是不行 $ npm install -g react-native-update-cli$ npm install --save react-native-update$ react-native link react-native-update 也有的说link了也还是没用

On evaluating adversarial robustness of large vision language models - 论文翻译
论文链接:https://arxiv.org/pdf/2305.16934 项目代码:https://github.com/yunqing-me/AttackVLM On evaluating adversarial robustness of large vision language models Abstract1 Introduction2 Related work3 Method
uva 327 Evaluating Simple C Expressions
原题: The task in this problem is to evaluate a sequence of simple C expressions, buy you need not know C to solve the problem! Each of the expressions will appear on a line by itself and will contain n
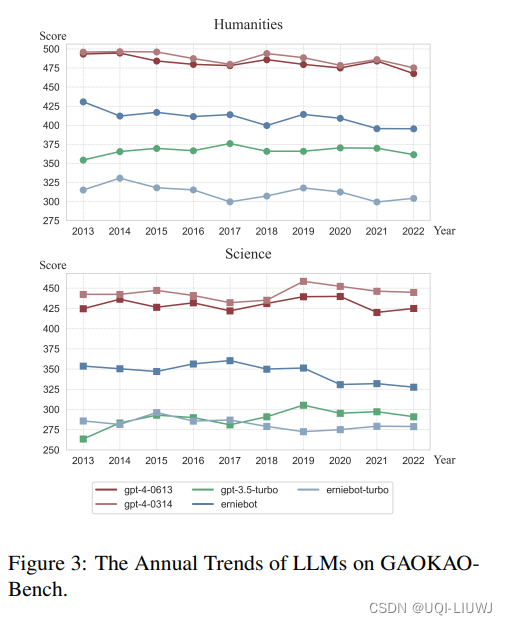
论文笔记:Evaluating the Performance of Large Language Models on GAOKAO Benchmark
1 论文思路 采用zero-shot prompting的方式,将试题转化为ChatGPT的输入 对于数学题,将公式转化为latex输入 主观题由专业教师打分 2 数据 2010~2022年,一共13年间的全国A卷和全国B卷 3 结论 3.1 不同模型的zeroshot 高考总分 3.2 各科主观题&客观题得分 3.3 不同年份的得分

Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference 相关链接:arxiv 关键字:Large Language Models、LLMs、Human Preference、Chatbot Arena、Benchmark Platform 摘要 随着大型语言模型(LLMs)解锁新功能和应用,评估它们

TypeError: undefined is not an object (evaluating '_react.default.defaultProps.object') - RN
TypeError: undefined is not an object (evaluating '_react.default.defaultProps.object') 在 ReactNative 项目开发中,起初对组件属性进行检测的时候使用了 defaultProps 属性,但抛出了如上的异常提示 解决办法 将如上 defaultProps 属性替换为 React 中的 pro
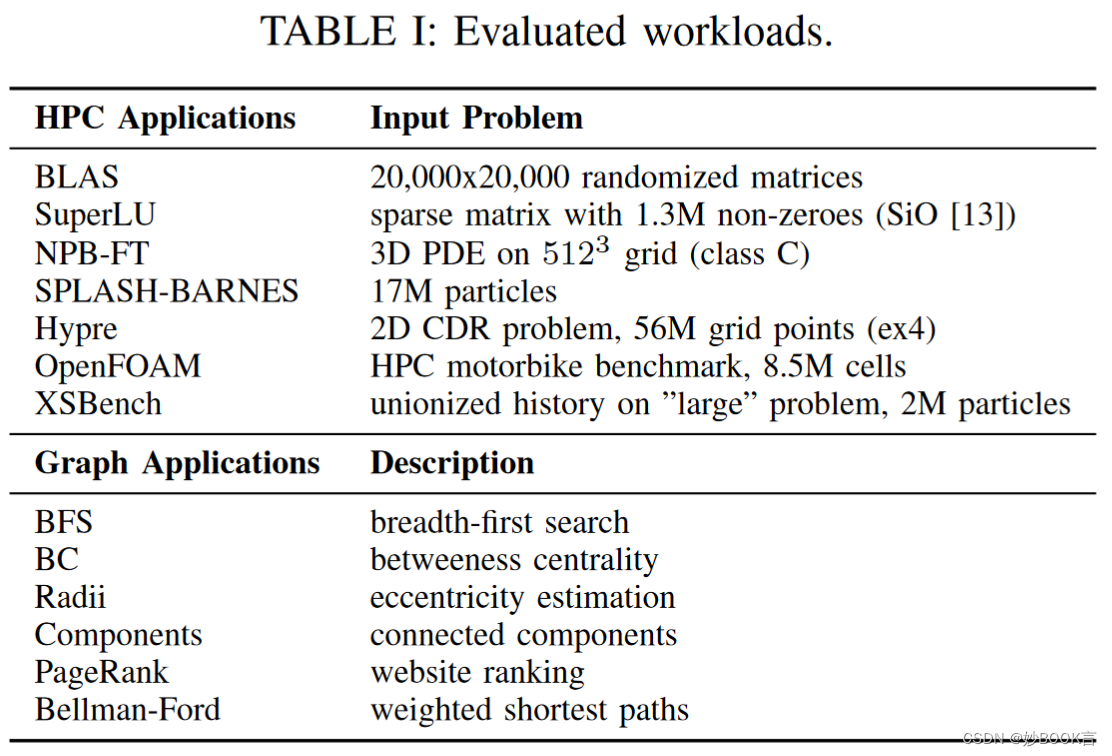
Evaluating Emerging CXL-enabled Memory Pooling for HPC Systems——论文泛读
MCHPC@SC 2022 Paper CXL论文阅读汇总 问题 当前的高性能计算(HPC)系统提供的内存资源是静态配置的,并与计算节点紧密耦合。然而,HPC系统上的工作负载正在演变。多样化的工作负载导致对可配置内存资源的需求,以实现高性能和高利用率。 现有方法局限性 CXL是用于互连处理器、加速器和内存的开放标准。符合CXL标准的硬件提供了对应用程序代码透明的低延迟、高带宽数据访问。一些

TUM VIO数据集介绍与尝试 The TUM VI Benchmark for Evaluating Visual-Inertial Odometry论文翻译
前言 做SLAM或是CV方向的应该大都接触过TUM提供的各种数据集,如RGBD数据集、单目数据集等。最近TUM发布了关于VIO即视觉惯性状态估计的对应数据集,成为了继飞行数据集EuRoc、MAV、车辆数据集Kitti等之后的又一个常用大型数据集。 本博客将就其数据集的论文《The TUM VI Benchmark for Evaluating Visual-Inertial Odometry》对

Towards Understanding and Evaluating Structural Node (Survey)
Towards Understanding and Evaluating Structural Node 基本信息 博客创建者 金蝉子 作者 JUNCHEN JIN, University of Michigan, USA MARK HEIMANN, University of Michigan, USA DI JIN, University of Michigan, USA DANAI

evaluating a learning algorithm
在这篇文章中,主要介绍了多项式的次数d和过拟合以及欠拟合之间的关系, 图1 如上图所示,我们可以得到如下结论 1.高偏差(欠拟合) 训练误差和验证误差都很高, 2.高方差(过拟合)训练误差很小,验证误差远大于训练误差 从图中我们可以得到如下结论: 1. 训练数据量少:训练误差很小,验证误差大 2.训练数据量大:验证误差和训练误差都很大,两者差不多相等 3.如

论文阅读——Guided Adversarial Attack for Evaluating and Enhancing Adversarial Defenses
白盒攻击 Guided Adversarial Attack for Evaluating and Enhancing Adversarial Defenses 文章连接 https://papers.nips.cc/paper/2020/file/ea3ed20b6b101a09085ef09c97da1597-Paper.pdf 代码连接 Guided Adversarial Att

深度学习论文: Evaluating You Only Hear Once on noisy audios in the VOICe Dataset及其PyTorch实现
深度学习论文: Evaluating You Only Hear Once on noisy audios in the VOICe Dataset及其PyTorch实现 Evaluating robustness of You Only Hear Once (YOHO) Algorithm on noisy audios in the VOICe Dataset PDF: https://arx
Evaluating Open-Domain Question Answering in the Era of Large Language Models
本文是LLM系列文章,针对《Evaluating Open-Domain Question Answering in the Era of Large Language Models》的翻译。 大语言模型时代的开放域问答评价 摘要1 引言2 相关工作3 开放域QA评估4 评估开放域QA模型的策略5 正确答案的语言分析6 CuratedTREC上的正则表达式匹配7 结论 摘要 词汇