本文主要是介绍2023华为杯数学建模D题-域碳排放量以及经济、人口、能源消费量的现状分析(如何建立指标和指标体系1,碳排放影响因素详细建模过程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
可能建立的指标如下:
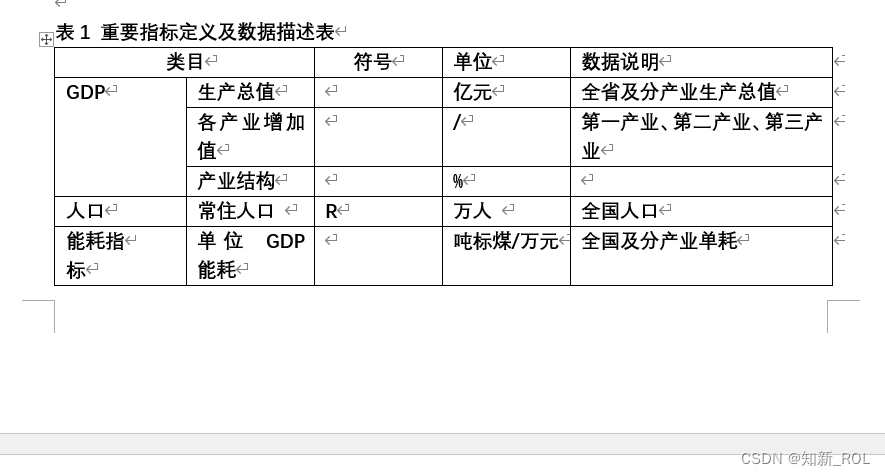
经济指标:
地区生产总值(GDP)人均GDP;第一产业(农林部门)产值;第二产业(能源供应和工业部门)产值;第三产业(建筑和交通部门)产值;居民生活消费总额。
人口指标: 总人口 ;人口增长率
能源消耗指标:
总能源消耗量;人均能源消耗量;非化石能源消费比重;各部门(农林、能源供应、工业、建筑、交通、居民生活)的能源消耗量;单位GDP能耗;人均GDP与人均能耗的比值
碳排放指标:总碳排放量;人均碳排放量;各部门(农林、能源供应、工业、建筑、交通、居民生活)的碳排放量;生态碳汇与工程碳汇的比值;间接碳排放量
详细的解题过程可以参考
指标体系:
描述经济发展、人口增长、能源消耗和碳排放之间的关系。
描述各部门在经济发展、能源消耗和碳排放中的角色和贡献。
描述非化石能源消费、单位GDP能耗、人均GDP与人均能耗的比值、生态碳汇与工程碳汇的比值、间接碳排放等指标对碳排放的影响。
碳排放预测:用经济增长率、人口增长率、能源消耗增长率、碳排放增长率等指标的历史数据,通过统计模型结合kaya模型预测未来的碳排放量。
当我们确定了具体的指标后,就可以开始使用熵权法(Entropy Method)来确定每个指标的权重,或者采用遍历系数法来确定每个指标的权重。这个过程通常需要专家的评分和参与(这个评分指的是我们根据,我们对各个指标进行排序(按照其和碳排放的关系(第一次给的代码中有很多结果图,需要你们自己去分析)),给他一个分数,进行)。
公式表述:
指标的权重确定方法:变异系数法
![]() 表示
表示![]() 因素的
因素的![]() 项指标的值,
项指标的值, ![]() 项指标的平均值为:
项指标的平均值为:
![]()
其中,![]() 表示体系数量,
表示体系数量,![]() 表示指标数量,
表示指标数量,![]() 表示
表示![]() 项指标的平均值
项指标的平均值
![]() 项指标的标准差为:
项指标的标准差为:
![]()
![]() 表示
表示![]() 项指标的标准差,然后,我们需要对指标进行无量纲处理,本文通过数据标准化方式对数据进行处理,具体公式如下:
项指标的标准差,然后,我们需要对指标进行无量纲处理,本文通过数据标准化方式对数据进行处理,具体公式如下:
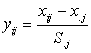
经过标准化处理后的指标![]() 的平均值为:
的平均值为:
![]()
经过标准化处理后的指标![]() 的标准差为
的标准差为
![]()
那么,指标![]() 的变异系数为:
的变异系数为:

其中,![]() 表示指标
表示指标![]() 的变异系数,也成为标准差系数。那么,各项指标的权重为:
的变异系数,也成为标准差系数。那么,各项指标的权重为:

![]() 表示指标
表示指标![]() 的权重系数
的权重系数
本题中已经有了这些年份的碳排放数据,所以不需要一个复杂的指标体系。可以直接比较和分析这些数据,以了解碳排放量随时间的变化情况。
通过计算每年碳排放量的平均值、中位数、最大值、最小值等统计量,以了解碳排放量的分布情况。
通过绘制折线图、柱状图等图形,直观地展示碳排放量随时间的变化情况(第一问给出了很多图,其实就是直接得到他们之间的关系,那么你需要多分析几个参量)
我们通过这种方式
我们选取地区生产总值、人口及能源消费量、产业能耗结构及能耗品种结构等因素,其中地区生产总值以GDP来衡量,人口以人口数量来衡量,能源消费量以碳排放总量来衡量,产业能耗结构是以产业碳排放比重大的产业消耗量为依据即以第一二三产业占比来衡量,本题中以第二产业占比来衡量。能耗品种结构以煤和油品消耗为主。
上述指标中生产总值、人口及能源消费量为第一梯度指标,而产业能耗结构及能耗品种结构等为第二梯度指标,第二梯度指标与第一梯度指标相关,如能源消费量与产业能耗结构及能耗品种结构等有很大关系,下面将建模进行分析。
模型的构建kaya和LMD1
构建碳排放量影响因素分析模型:LMDL模型
对数平均迪氏指数(Logarithmic Mean Divisia Index)法是指数分解法的一种,简称LMDI。LMDI的基本思想是把一个目标变量的变化分解成若干个影响因素变化的组合。
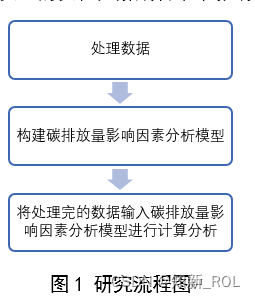
图1 研究流程图

其中,ct为年份t的总碳排放量,I为不同的能源大类集合,包括煤炭、油品、天然气、热力、电力、其他能源;J为各产业部门的集合,包括第一产业、第二产业、第三产业等;ei,j,t
为第t年j类型产业对i类型能源的消费量;αi,t为第t年i类型能源的碳排放因子。
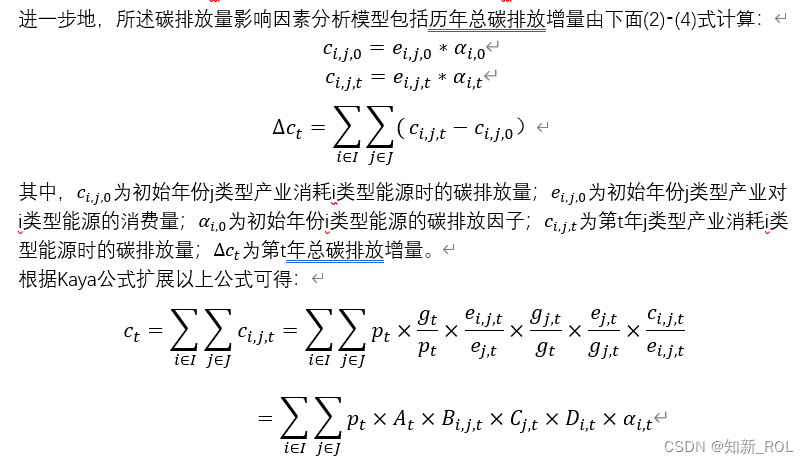

(三)人口、经济增长、能源结构、产业结构、能耗强度和碳排放系数等因素对碳排放增量影响的分析
进一步地,所述碳排放量影响因素分析模型包括由(5)‑(10)式分析人口、经济增长、能源结构、产业结构、能耗强度(单位GDP能耗)以及碳排放系数对碳排放增量的影响:
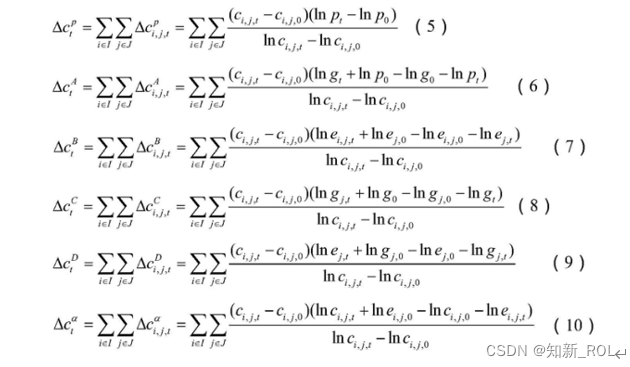

人口数据、产业结构数据、各产业GDP数据、各产业对各类型能源的消耗数据以及各类型能源的碳排放系数输入预先构建的碳排放量影响因素分析模型进行数据分析,并将分析结果绘制成条形图。
参考图1:
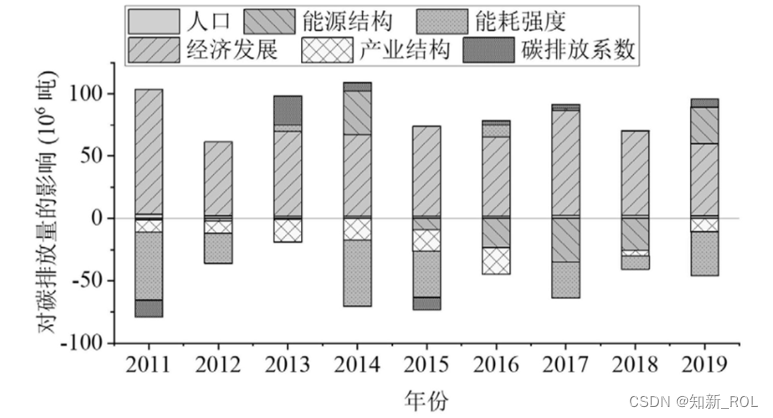
人口、经济增长、能源结构、产业结构、能耗强度和碳排放系数等六个因素对碳排放量的总贡献量分别为20 .86、637 .79、‑108 . 36、‑299 .21和21 .05百万吨。首先,人口对碳排放增长起着促进作用,占碳排放总增长量的6 .72%,由此可见,由于人口增长导致的碳排放增量仍在合理范围内。其次,经济增长是碳排放增长的主要驱动因素,占碳排放总增长量的205 .60%。每年中的该因素导致的碳排放增长量皆为正值,这说明经济增长仍然是以大量消耗高碳排放的能源为代价的。
这篇关于2023华为杯数学建模D题-域碳排放量以及经济、人口、能源消费量的现状分析(如何建立指标和指标体系1,碳排放影响因素详细建模过程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





