建立专题

【内网】ICMP出网ew+pingtunnel组合建立socks5隧道
❤️博客主页: iknow181 🔥系列专栏: 网络安全、 Python、JavaSE、JavaWeb、CCNP 🎉欢迎大家点赞👍收藏⭐评论✍ 通过环境搭建,满足以下条件: 攻击机模拟公网vps地址,WEB边界服务器(Windows Server 2008)模拟公司对外提供Web服务的机器,该机器可以通内网,同时向公网提供服务。内网同网段存在一台Windows内网服务

【IDEA】建立多个子模块依赖于一个父模块(maven)
第一步,建立父模块(在IDEA中就是工程) 第二步,选中父模块(也就是工程)右键New Module建立子模块 勾选创建模板原型并一般选择 maven-archetype-quickstart,当创建web模块时选择 maven-archetype-webapp 其他子模块都是类似这样创建~ packaging打包类型有: jar,默认类型warejbea

【2024全国大学生数学建模竞赛】B题 模型建立与求解(含代码与论文)
目录 1问题重述1.1问题背景1.2研究意义1.3具体问题 2总体分析3模型假设4符号说明(等四问全部更新完再写)5模型的建立与求解5.1问题一模型的建立与求解5.1.1问题的具体分析5.1.2模型的准备 目前B题第一问的详细求解过程以及对应论文部分已经完成! - 晚上7-8点之前第二问完成 - 明天中文之前全部写完 按照提交论文的格式进行撰写!完整版请看文章最后!

【UE4源代码观察】手动建立一个使用UBT进行编译的空白工程
我想观察UE4是怎么编译的,于是查阅官方文档,了解到UE4有一套自己的编译工具:UnrealBuildTool,简称UBT。关于UBT的官方文档参阅:虚幻编译工具。我想尝试自己手动建立一个使用UBT进行编译的空白工程。不过首先,先了解下UBT的编译流程中一些文件所扮演的角色 UBT的编译流程中一些文件所扮演的角色 模块 每个模块都由一个 .build.cs 文件声明,它存储在 Source

Linux - Tcp连接建立和释放的三次握手四次挥手
一、TCP报文段首部格式 源端口/目的端口:各占2个字节,分别写入源端口和目的端口,端口是传输层与应用层的服务接口 序号:占4个字节,TCP连接中传送的数据流中每一个字节都有一个序号,序号字段指本报文段所发送的数据的第一个字节的序号 确认号:占4个字节,是期望收到对方下一个报文的第一个数据字节的序号 数据偏移:占4个字节,它指出TCP报文的数据距离TCP

【2024高教社杯全国大学生数学建模竞赛】ABCDEF题 问题分析、模型建立、参考文献及实现代码
【2024高教社杯全国大学生数学建模竞赛】ABCDEF题 问题分析、模型建立、参考文献及实现代码 1 比赛时间 北京时间:2024年9月5日 18:00-2024年9月8日20:00 2 思路内容 2.1 往届比赛资料 【2022高教社杯数学建模】C题:古代玻璃制品的成分分析与鉴别方案及代码实现(已经更新完毕) 【2022高教社杯数学建模】C题:古代玻璃制品的成分分析与鉴别 赛后总

如何把文件夹里的所有文件每个建立一个文件夹,并且以文件的名字命名
如何把文件夹里的所有文件每个建立一个文件夹,并且以文件的名字命名?TOC 你可以把文件归类,然后同类型的文件放在相应的文件夹内,你一定要这样做,那你就不停的按那个新建文件夹快捷菜单,新建n个文件夹,然后按顺序选择文件按F2再按Ctrl+C然后把该文件拉进新建文件夹1然后选择新建文件夹1按F2再按Ctrl+v,其余以此类推。这样做很繁琐的。 新的方法 新建一个空白的txt文件,输入: @ec

LLAMA3.1 8B 本地部署并配合Obsidian建立本地AI知识管理系统
目前,LLAMA3.1模型分为8B、70B、405B三个版本,其中70B和405B对于显存的要求均已超过了一般家用电脑的配置(或者换个说法,用一张4090也是带不起来的),所以运行8B即可。LLAMA3.1 8B的性能约相当于ChatGPT3.5。 经过我的测试4080、2080、intel ultra 9 185H(无独立显卡,其能力约相当于1060)都是可以带得动8B模型的,当然显卡越好,响

UI自动化如何建立+如何进行元素定位
下载驱动 mac下载驱动的方法 selenium macOS chromedriver macOS 安装 Selenium 配置 ChromeDriver_selenium ide 谷歌浏览器驱动下载 mac系统-CSDN博客 win下载驱动的方法 Chromedriver安装教程(简洁版)-CSDN博客 驱动-浏览器更新的链接 https://www.cnblogs.com/aiyablog

liferay中站点的建立及封装一个Util类用于站点模板的引用
写这篇文章主要是记录一下在项目开发中遇到问题,分析问题,解决问题的过程. 由于项目需求,需要把创建站点,站点模板引用单独从控制面板中拿出来,于是去开始着手源码的阅读,这篇文章重点不在这,所以略去. 首先说一下组织和站点的关系 1.Organization和Group 每创建一个Organization 就会有一个对应的Group 表group_的classPK存的就是organizati

鹏程万里-----python环境建立
如果用win10的话,一定要用管理员权限的账户,也就是用administrator 然后安装pycharm,这里非常有讲究 首先是要配置工程的interpreter 然后是创建 这两个东西 C:\Program Files\Python36\Lib\site-packages\pyqt5_tools\designer.exe 然后是 C:\Program F
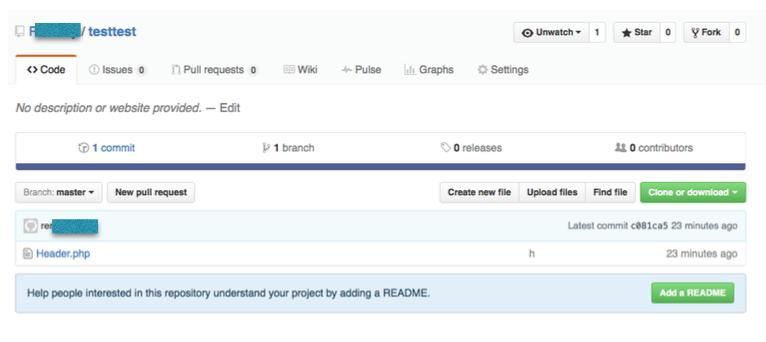
在SourceTree建立GitHub远程Remote文件
1: 在GitHub新建⼀個newPository,可以取任何名字(有严格项目规定的要建成private!) 2: 在Source Tree找到Setting, 點擊進⼊ 3:在Remotes裏點Add 4: 添個名字任意的如test或後⾯面的origin,然後點RL/ path後的地球icon 5: 搜索在github裏建⽴的名字,選中點OK 6:一直點擊OK

Simulink代码生成:数据字典的建立、关联模型
本文介绍如何建立Simulink数据字典,并关联模型。 文章目录 1 数据字典的作用2 数据对象的简单概念3 数据对象的管理方式3.1 mat文件或m文件3.2 Excel表格&m脚本3.3 Simulink自带的数据字典文件 4 建立和关联Simulink数据字典文件5 sldd数据字典的一些说明6 总结 1 数据字典的作用 简单来说,数据字典的作用就是把一个模型用到的所有数据

堆的建立、插入、出堆、堆化、topk问题、堆排序(C语言实现)
堆的建立、插入、出堆、堆化、topk问题、堆排序 使用数组来存储堆 堆顶为序号0,堆底为序号 size - 1 假设树为完全二叉树,当前节点和双亲节点的关系可以通过公式表达 // 小顶堆: 对 heaptifyUp 和 heaptifyDown 函数的逻辑进行一些调整。void initHeap(float **arr, int *size) { *arr = (float *)malloc

链表建立,插入,删除,输出
自己的弱项 = =要好研究一下链表的问题= = Description 编写一个函数creatlink,用来建立一个动态链表。(包含学号和成绩) 编写一个函数printlink,用来输出一个链表。 编写一个函数dellink,用来删除动态链表中一个指定的结点(由实参指定某一学号,表示要删除该学生结点)。 编写一个函数insertlink,用来向动态链表插入一个结点。 编写一个函数fr
![[Linux网络]TCP三次握手和四次挥手的连接建立和断开](https://i-blog.csdnimg.cn/direct/8e4a8f5a56ac421ab75a1fb443070135.png)
[Linux网络]TCP三次握手和四次挥手的连接建立和断开
TCP的三次握手 第一次握手:客户端发送网络包,服务器端收到,证明客户端的发送能力、服务器的接收能力是正常的。第二次握手:服务器发送网络包,客户端收到,证明服务器端的发送能力是正常的,不过此时并不能确定,客户端的接收能力是正常的。第三次握手:客户端发包,服务器端收到,服务器端可以得出结论,客户端的发送,接收能力是正常的。服务器端的接收,发送能力是正常的。 什么是半连接队列? 服务器端第一次
tensorflow:超简单易懂 tensor list的使用 张量数组的使用 扩增 建立 append
构造张量数组: 最简单的方式: tensor_list=[tensor1,tensor2] 常用的方式(这个方式可以用于for循环) tensor_list=[]tensor_list.append(tensor1)tensor_list.append(tensor2) 张量数组的使用 批量处理张量数组里面的张量,之后将其存储到一个新的张量数组中 new_tensor_list

【综合小项目】—— 爬取数据、数据处理、建立模型训练、自定义数据进行测试
文章目录 一、项目内容二、各步骤的代码实现1、爬取数据2、数据处理3、建立模型训练4、自定义数据进行预测 一、项目内容 1、爬取数据 本次项目的数据是某购物平台中某个产品的优质评价内容和差评内容采用爬虫的 selenium 方法进行爬取数据内容,并将爬取的内容分别存放在两个文本文件中 2、数据处理 分别读取存放数据的两个文本文件分别对优质评价和差评的内容进行分词导入停用词库,对
git中的分支是什么?分支有哪些好处?如何建立分支?
git中的分支是什么? 在Git中,分支是版本库中记录版本位置(支线)的一种方式。分支可以被视为一条时间线,每次提交都会在这条时间线上形成一个新的版本。通过分支,开发者可以在不影响主线(通常是主分支master或main)的情况下,进行另外的操作,如新功能开发、bug修复等。当分支上的工作完成后,可以选择将其合并回主线,或者根据需要进行其他处理。 分支有哪些好处? Git分支带来了许多好处,
https建立连接原理笔记
建立https连接 TCP协议–通信双方通过三次握手建立tcp连接TLS(transport layer security)协议–通信双方通过四次握手建立TLS连接HTTP协议–client向server发起request,server发挥response PS:以下笔记只针对tls1.2 TCP tcp三次握手建立连接 客户端向服务端发送带有 SYN 的数据段以及客户端开始发送数据段(S

python 天气与股票的关系--第3部分,建立模型
起因(目的): 继续瞎折腾。 过程: 假设有下面这些规则: 天气中的温度, 如果最高温度大于 36, 那么就是坏天气。如果最低温度小于 5, 那么也是坏天气。如果下雨, 下雪, 那么也是坏天气。其他情况为 好天气 import pandas as pddef calculate_comfort(row, initial_comfort=17):# confy = initial_comf
国赛论文写作教学指南——模型的建立与求解
模型的建立与求解是论文中最关键的部分,是整篇文章的核心内容,因此必须给予高度重视。接下来,我们将探讨这一部分的写作流程及其要点。 一、内容含义 1、模型的建立 模型的建立是将问题抽象成数学语言的表达式,它一定是在先前的问题分析和模型假设的基础上得来的。因为比赛时间很紧,大多数时候我们都是使用别人已经建立好的模型。这一部分需要将题目问的问题和模型紧密结合起来切记随
记录一次两台虚拟机Oracle rac 心跳不能建立的排查
场景:两台云主机,均有子网IP和虚IP,目前子网IP和虚IP都能互相ping通。而且延迟很小,同时traceroute发现,有带* 的结果,与网络同事沟通后得知,带*并不能影响网络的连通性。 解决方案:使用tcpdump 抓udp包,指定虚拟网卡和虚IP的地址发现,发现没有包过来。然后检查了安全组,发现安全组是全部放通的状态,另外也有同事提出,同一个vpc里面的两个主机不能建立心跳,应该给还不到