本文主要是介绍CoAtGIN: Marrying Convolution and Attentionfor Graph-based Molecule Property Prediction,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
摘要
1 介绍
2 方法
A. 预赛(Preliminaries)
B.局部卷积
C.全局卷积
摘要
基于计算策略的分子性质预测在药物发现和设计过程中起着关键作用,如DFT。然而,这些传统的方法耗时长,劳动强度大,不能满足生物医学的需要。由于深度学习的发展,出现了许多用于分子表示学习的图神经网络(GNN)变体。然而,现有的性能良好的基于图的方法具有大量的参数或轻模型,不能在各种任务上取得很好的成绩。为了管理效率和性能之间的权衡,我们提出了一种新的模型架构,CoAtGIN,同时使用卷积和注意力。在局部级别,k-hop卷积被设计用于捕获远程邻居信息。在全局层面,除了使用虚拟节点传递相同的消息外,我们还根据每个节点和边的重要性对聚合全局图表示使用线性关注。在最近的Open Graph Benchmark (OGB) Large-Scale Benchmark中,CoAtGIN仅使用6.4 M个模型参数就在大规模数据集PCQM4Mv2上实现了0.0901的Mean Absolute Error (MAE)。此外,使用线性注意力块有助于捕获全局表征,从而提高了性能。
1 介绍
纵观人类对抗疾病治疗的历史,小分子药物作为最可靠的方法发挥了至关重要的作用[1-4]。然而,小分子药物的研究面临着诸多挑战。据估计,一种新药在发现阶段必须鉴定和验证5000 - 10000个分子[5]。考虑到这一漫长而艰苦的时期,研究人员总结了各种指导方针,以加速基于药物样特征的药物发现过程。例如,吸收、分布、代谢、排泄和毒性(ADMET)与酸碱性质高度相关[6]。此外,HUMO-LUMO隙作为一种量子化学性质,可能会影响反应性、光激发和电荷输运[7]。考虑到数千种候选化合物,对每种化合物进行化学或生物实验既耗时又费力。
随着化学和计算机科学的发展,研究表明,力场法可以高精度地估计分子的某些性质。例如,预测分子内部和分子之间的力是可行的。此外,密度泛函理论(density functional theory, DFT)在物理、化学、材料等许多领域已经成为一种有价值和有用的工具[8]。该方法通过精确计算分子形状、反应性和能隙等各种分子性质,有助于药物的发现[9]。尽管DFT取得了卓越的成功,但是对于成千上万的候选分子来说,该方法的运行时间仍然是昂贵的,因为计算单个分子的性质需要几个小时。
近年来,人工智能对生物制药的发展做出了重大贡献。一些深度学习框架已经被开发出来,并在小分子药物发现的应用中表现良好[10],如基于变压器的BERT[11]和GPT[12]。小分子通常使用SMILES(简化分子输入线规范)格式表示。因此,一些研究已经使用这些经过验证的预训练语言模型来预测分子性质。例如,SMILES- bert[13]使用掩蔽语言学习直接将bert风格的训练策略应用于SMILES序列。为了克服数据稀缺性,Chem-BERTa[14]使用了多个等效的SMILES作为输入。此外,TokenGT[15]使用香草Transformer[16]通过将原子和键视为独立的令牌来处理分子图。
基于字符串的表示主要关注序列特征,这使得难以捕获分子拓扑的重要信息。如果我们将原子和键视为图的节点和边,使用图神经网络(graph neural network, GNN)可以帮助获取拓扑结构信息,如GIN[17]、GA T[18]、GIN- virtual[19]、DeeperGCN[20]。这些基于图的方法将每个节点的消息传播到相邻节点,消息传递体系结构可以表示分子拓扑知识。然而,更深入和更广泛的基于gnn的模型需要更多的GPU内存。例如,edge -augmented Graph Transformer (EGT)使用一个普通的Transformer来处理节点嵌入,并为每个节点对引入边缘通道。但是这些新颖的图架构有很多模型参数(图1)。

图1所示。模型在Open Graph Benchmark (OGB)上的性能。左上角区域的节点表示性能不够好但参数较少的模型。右下区域包含性能良好的具有大量参数的模型。作为交叉口区域,CoAtGIN在只需要几个参数的情况下取得了很好的效果。
从上面的讨论中,我们可以观察到(a)基于字符串的方法不能直接编码重要的拓扑信息。GNN结构适合处理小分子药物数据。(b)虚拟节点向每个节点传递相同的消息,缺乏全局表示能力。(c)这些方法的规模不断增加,以提高预测精度(图1),这提出了管理效率和性能之间权衡的挑战。受这些观察结果的启发,我们提出了一种新的基于图的架构,称为CoAtGIN,它可以概括如下:
1)我们提出了图卷积网络中的k-hop卷积,以便在一次迭代内更快地聚合消息。
2)提出了一种利用线性变压器实现全局消息在图中传递的新方法。
3)如图1所示,我们开发了一个轻量级但性能良好的模型CoAtGIN,该模型只有6.4万个参数,在大规模图数据集(PCQM4Mv2)的回归任务中达到了0.0901的平均绝对误差(MAE)。
2 方法
如图2 (a)所示,CoAtGIN的每一层由一个局部卷积块和一个全局卷积块组成。与传统的图神经网络(GNN)一样,局部卷积块负责聚合每个节点的邻居节点特征。全局卷积块使节点能够直接与全图交互。有两种类型的全局卷积块:1)虚拟节点和2)线性变压器。虚拟节点块向每个节点广播聚合的特性。线性变压器允许每个节点与一个代表性特征交互,以获得不同的知识。后面的小节将详细介绍这两个块。此外,每一层以节点嵌入(NE)和图嵌入(GE)作为输入,这两个嵌入分别表示图的基本信息和聚合的全局特征。
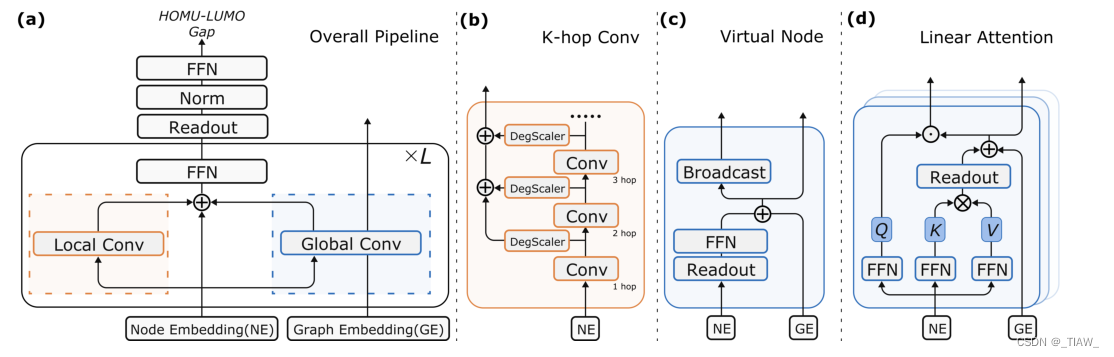
图2所示。(a)预测HUMO-LUMO间隙模型的整体流水线,由L个重复层组成。每一层可以大致分为两个块,分别是Local Convolution和Global Convolution,这里使用的是经典残差。(b)局部卷积块。新的图局部卷积块k-hop卷积对邻居信息进行k次重复聚合,使学习到的特征能够学习到更多的分子知识。不同k-hop卷积特征的权值由度尺度控制,用DegScale表示。(c)全局卷积块。虚拟节点示意图,它分别使用reduce和broadcast操作对原始图中的每个节点进行读写操作。并将快捷路径应用于通过前馈网络的特征。(d)全局卷积块。与大多数线性变压器一样,K, V矩阵首先与Q矩阵结合,对全局KV进行点积。此外,利用Readout函数对KV矩阵进行聚合,形成节点智能Q的全局交互媒体。此外,将剩余信道应用于聚合的KV矩阵。
A. 预赛(Preliminaries)
图同构网络(GIN)[17]架构由Xu等人提出,是一种简单但功能强大的图学习方法。说明并证明了GIN可以有效地区分不同的图表示。此外,GIN的判别能力与1-Weisfeiler-Lehman(1-WL)同构检验一样强。利用多层感知(MLPs)对多集函数建模,GIN的传播过程可以描述为:
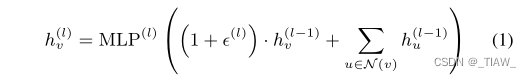
其中h(l)v是节点v在第l层的特征向量,MLP(l)表示第l层的多层感知,λ (k)表示一个可学习的参数,N (v)是包含节点v所有邻居的节点集。
B.局部卷积
然而,聚合函数表明,在传统的图神经网络(GNN)中,只有邻居才能查询和传递消息。直观地说,通过远程节点对的消息将是嘈杂和缓慢的,因为一个节点的特征需要多次迭代才能到达另一个节点。另外,相邻的电子对仅仅保留了键的信息,这对分子来说是不够的。仅用键信息不能准确地描述分子的构象。键信息、键角和二面角构成了精确定义一个分子的最小集。
K-hop Convolution:在eq.(1)所示的普通节点聚合操作中,只捕获1跳距离内的特征。众所周知,1-hop特征最多包括bond特征。学习键角和二面角信息分别需要至少2跳和3跳特征。为了使神经网络能够捕获必要的信息,CoAtGIN扩展了原始的GIN聚合过程以获得k-hop特征,我们将其称为k-hop卷积。k-hop卷积表示为:
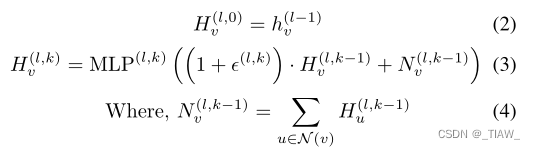
其中H(l,k)v表示节点v在第l层的k-hop特征。如式(2)所示,我们将节点v的初始k-hop值设为每层节点嵌入h(l−1)v。Eq 3和4说明重复传播k次以获得k跳距离信息。
度尺度:k-hop特征计算完成后,对不同k值的特征进行汇总。在聚合过程中考虑了度差,因为第III-B节的实验表明,度信息在此回归任务中也很重要。基于这一观察,我们选择使用分程度的尺度来管理聚合过程,其过程可以表示为
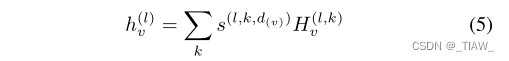
其中s(l.k,d(v))是控制第l层中这K个特征权重的尺度,d(v)表示节点v的程度。第l层中每个节点h(l)v的节点嵌入根据这些K -hop特征的加权和进行更新。
C.全局卷积
在全局卷积块中,有两个子模块:虚拟节点和线性注意块。线性注意块和虚拟块分别生成注意图嵌入(AGE)和虚拟节点图嵌入(VGE),两者加在一起作为全局卷积块的输出。
虽然k-hop卷积将最大相互作用距离扩大了几倍,但对于长距离对来说仍然是不可达的。因此,Gilmer等[19]开发了一种变体GIN-VN,它在图中添加一个具有特定边类型的虚拟节点,该节点连接到所有其他节点。在消息传递的每一步中,图上的每个原始节点都对该节点进行读写。添加虚拟节点表明,该方法在广泛的图级预测数据集上有效工作[21]。
虚拟节点:虚拟节点块的整体流程与GIN-VN类似。如图2 (c)所示,节点嵌入通过READOUT函数(求和操作)进行约简。将所有嵌入的节点相加,形成汇总信息。将聚合节点特征传递到前馈网络中,得到对整个网络的解释,我们称之为虚拟节点图嵌入(Virtualnode Graph Embedding, VGE)。将上一层的旧VGE添加到最新的虚拟节点图嵌入(VGE)中,并将更新后的虚拟节点嵌入广播到原始图中的每个节点。
但值得注意的是,图2 (c)所示的原图中每个节点的广播嵌入是相同的。虽然Xu等[17]已经证明,将SUM操作作为图级READOUT函数可以获得很好的判别能力。然而,图中的每个节点也需要接受不同的特征表示来优化其表示。不同的原子在各种化学性质中起着不同的作用,这就要求网络提供不同类型的信息。
线性转换器:为了完成这项任务,注意机制是跨整个图读取和发送信息的另一种方式。与添加虚拟节点不同,注意块返回的聚合特征因节点而异。因此,我们使用Transformer作为全局卷积块来保证节点的多样性。然而,普通转换器的时间复杂度与节点数的平方有关。为了开发一个高效和轻量级的模型,我们选择使用线性变压器来完成注意力机制,以弥补昂贵的计算成本。
为了使局部节点特征与全局分子特征相互作用,我们在cosFormer的基础上,在虚拟节点块中添加了相同的READOUT函数(求和运算)来聚合全局KV[22]。除了使用聚合KV更新图嵌入以获得线性关注外,该矩阵还用于响应节点智Q矩阵,如图2 (d)所示。聚合KV矩阵是实现与节点智Q交互的全局媒体。该过程完成了为每个节点分配节点智能全局特征的任务。变压器的结果是由节点驱动的图嵌入,我们称之为注意图嵌入(AGE)。
这篇关于CoAtGIN: Marrying Convolution and Attentionfor Graph-based Molecule Property Prediction的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




