本文主要是介绍LLM+KGs综述:Unifying Large Language Models and Knowledeg Graphs: A Roadmap,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
统一大语言模型和知识图谱综述
Unifying Large Language Models and Knowledeg Graphs: A Roadmap
githb:https://github.com/zjukg/KG-LLM-Papers
介绍了大语言模型的知识图谱结合的一些东西。

introduction
LLM在一些NLP任务上发展很好。最近,模型参数规模的大幅度增加进一步增强LLM能力,为LLM作为人工通用智能(Artificial General Intelligence, AGI)的应用铺平了道路。
LLM存在一些问题:
- 幻觉问题
具体来说,LLM记忆训练语料库中包含的事实和知识。然而,进一步的研究表明,LLM无法回忆事实,并且经常通过生成事实不正确的陈述来产生幻觉。
幻觉问题相关文章:【Survey of Hallucination in Natural Language Generation】【A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity】
- 缺乏可解释性
作为黑盒模型,LLM也因其缺乏可解释性而受到批评。LLM在其参数中隐含地表示知识。很难解释或验证LLM获得的知识。此外,LLM通过概率模型进行推理,这是一个优柔寡断 indecisive 的过程。LLM用于实现预测或决策的特定模式和功能对人类来说是无法直接访问或解释的。尽管一些LLM能够通过应用思维链chain-of-thought来解释他们的预测,但他们的推理解释也存在幻觉问题。
【Self-Consistency Improves Chain of Thought Reasoning in Language Models】
这个文章设计了一种改善 思维链+LLM 的方法
- 受训练数据限制的泛化问题
由于缺乏特定领域的知识或新的训练数据,在一般语料库上训练的LLM可能无法很好地推广到特定领域或新知识。
知识图谱
解决上述问题的一种方法是引入知识图谱Knowledge Graphs(KGs)。然而KGs具有难构建、不足以处理真实世界知识、文本信息被忽略、知识不够普遍等问题,因此也需要LLMs来解决KGs面临的问题。


LLM和知识图谱优缺点

LLM+KGs方法类别划分
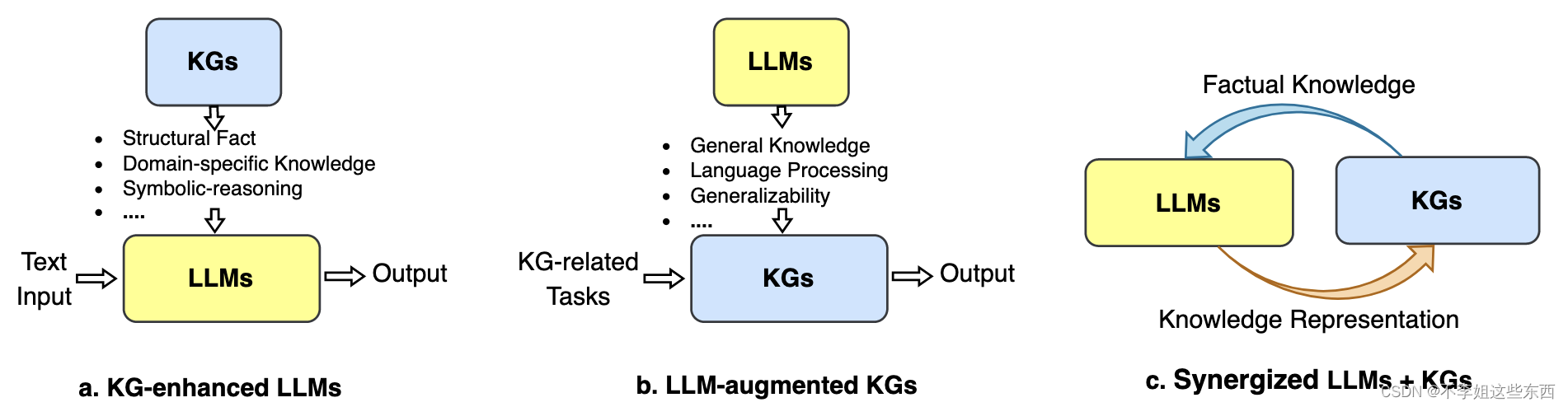
- KGs-enhanced LLM : 在KG增强的LLM中,KG不仅可以被纳入LLM的预训练和推理阶段,以提供外部知识,还可以用于分析LLM和提供可解释性。
- LLM-augmented KGs : 在LLM增强的KG中,LLM已被用于各种与KG相关的任务,例如,KG embedding ,KG completion,KG construction ,KG-to-text generation and KGQA ,以提高性能并促进KG的应用。
- Synergized LLMs + KGs : 在协同LLM+KG中,研究人员将LLM和KG的优点结合起来,共同提高知识表示和推理的性能。
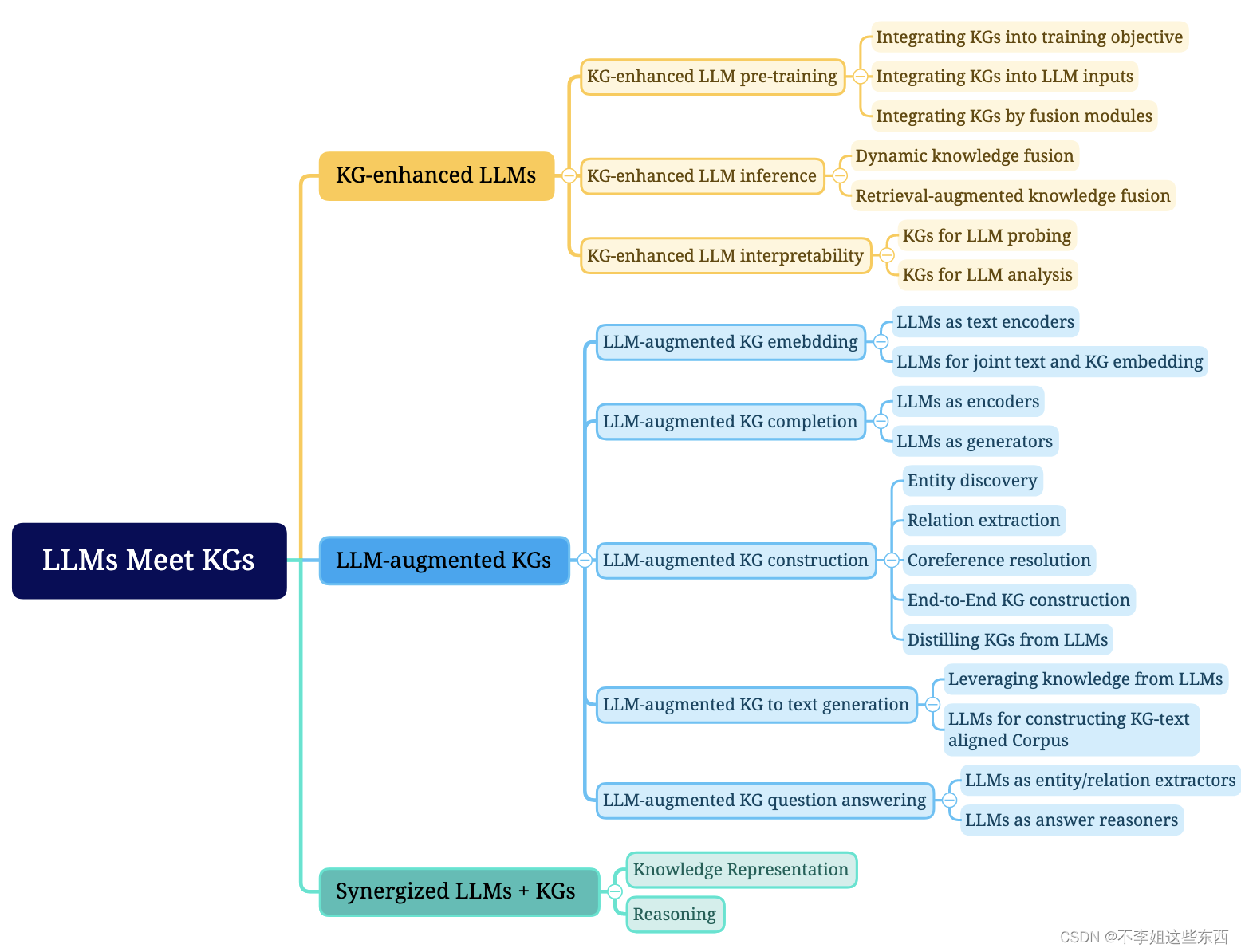
知识图谱增强大语言模型
预训练阶段
- 将KGs引入训练目标,设计知识导向的训练目标
- 将KGs整合到LLM输入中
- 将KGs纳入到额外的融合模块中,设计单独处理KGs的模块。
预训练阶段引入知识需要重新训练LLM
推断阶段:保持知识空间和文本空间的分离,在推理时注入知识。
- 动态知识融合
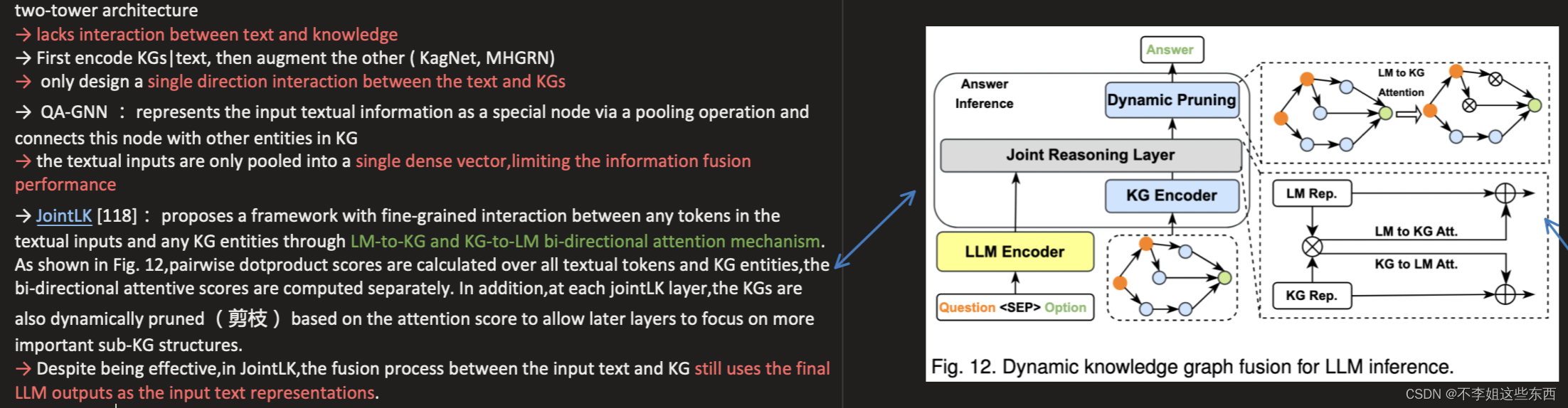
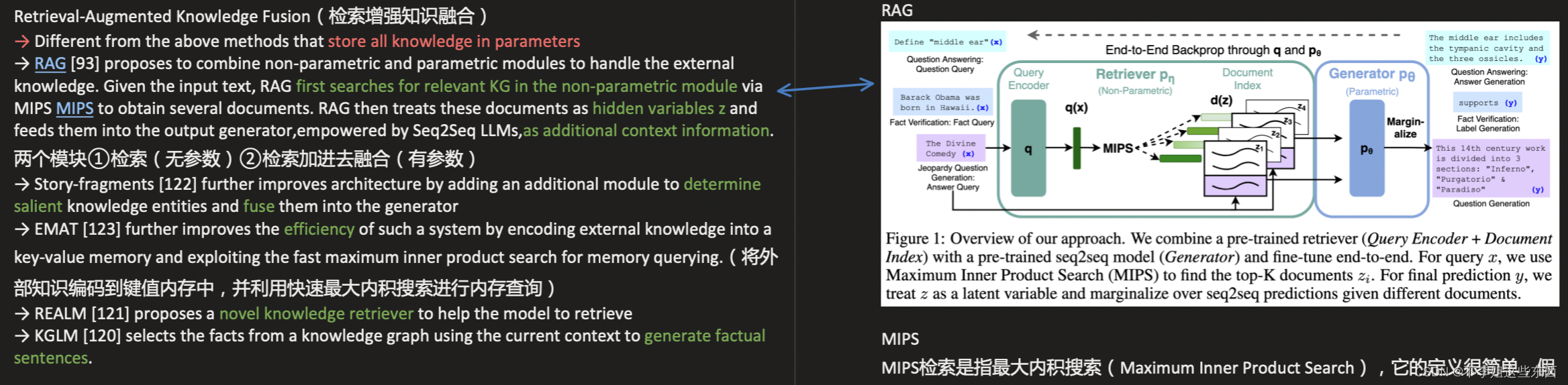
- 检索增强知识融合
动态知识融合将知识储存在参数中,而该方法采用两个模块①检索模块(无参数)②融合模块(有参数)
可解释性
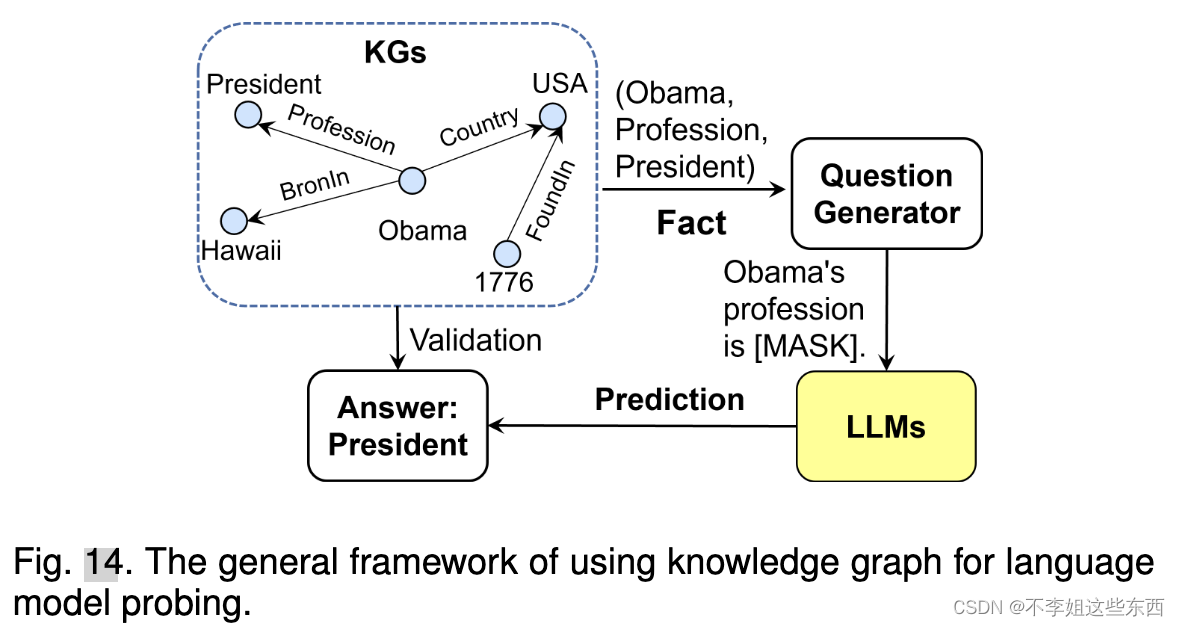
- 用知识图谱进行LLM探索
LAMA首先通过预定义的提示模板将KGs中的事实转换为完形填空语句,然后使用LLMs来预测缺失的实体。
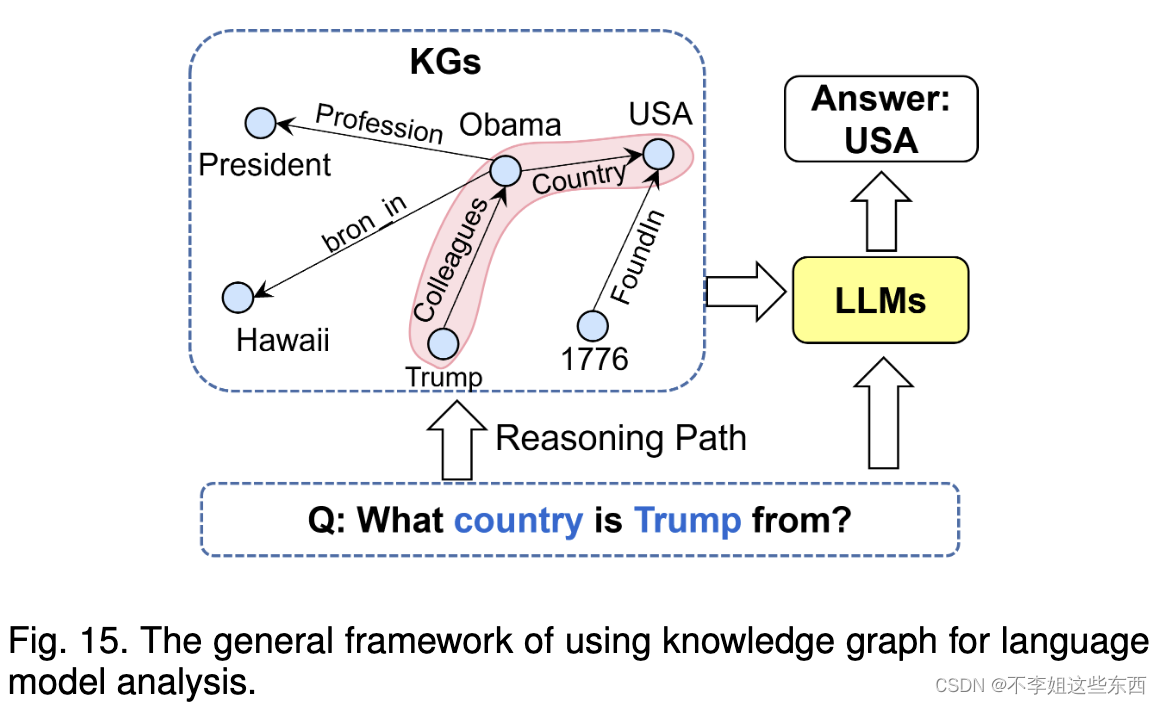
- 用知识图谱进行LLM分析
让LLM生成内容的每一步过程都在知识图谱的指导下进行。
大语言模型增强知识图谱
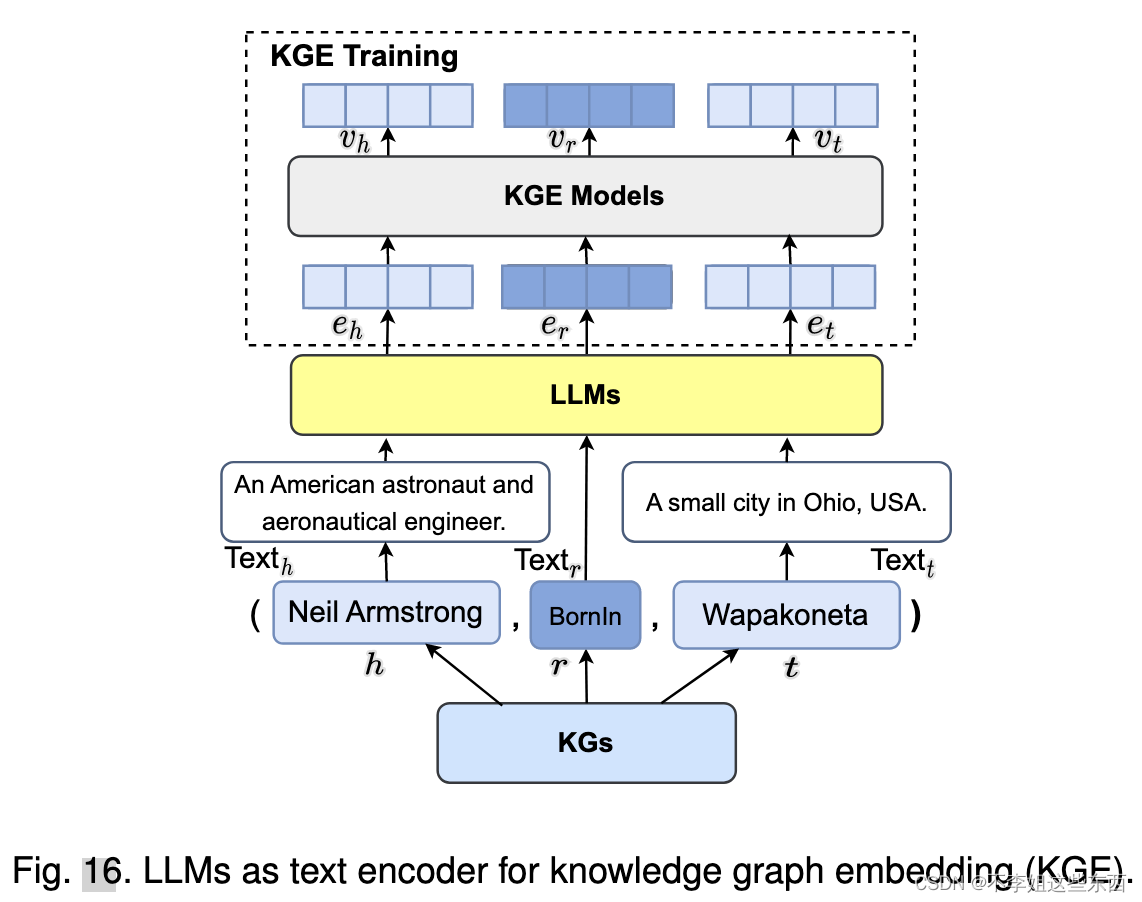
KG embedding
- LLMs as Text Encoders
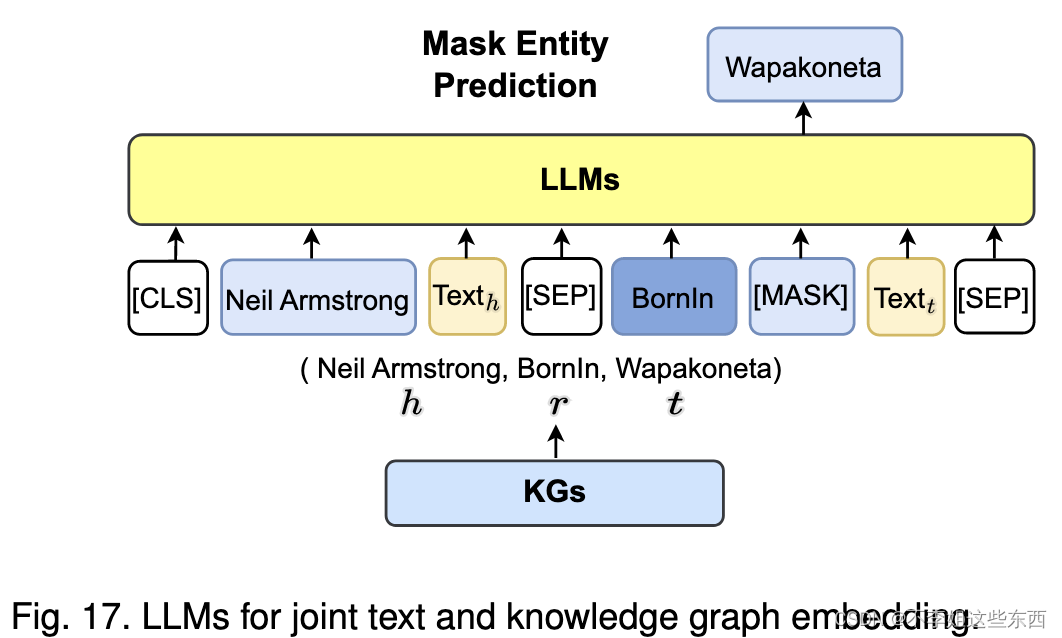
- LLMs for Joint Text and KG Embedding
直接采用LLMs将图结构和文本信息同时纳入嵌入空间
知识图谱补全(KG completion,KGC)
利用LLMs对文本进行编码或生成事实,以提高KGC的性能
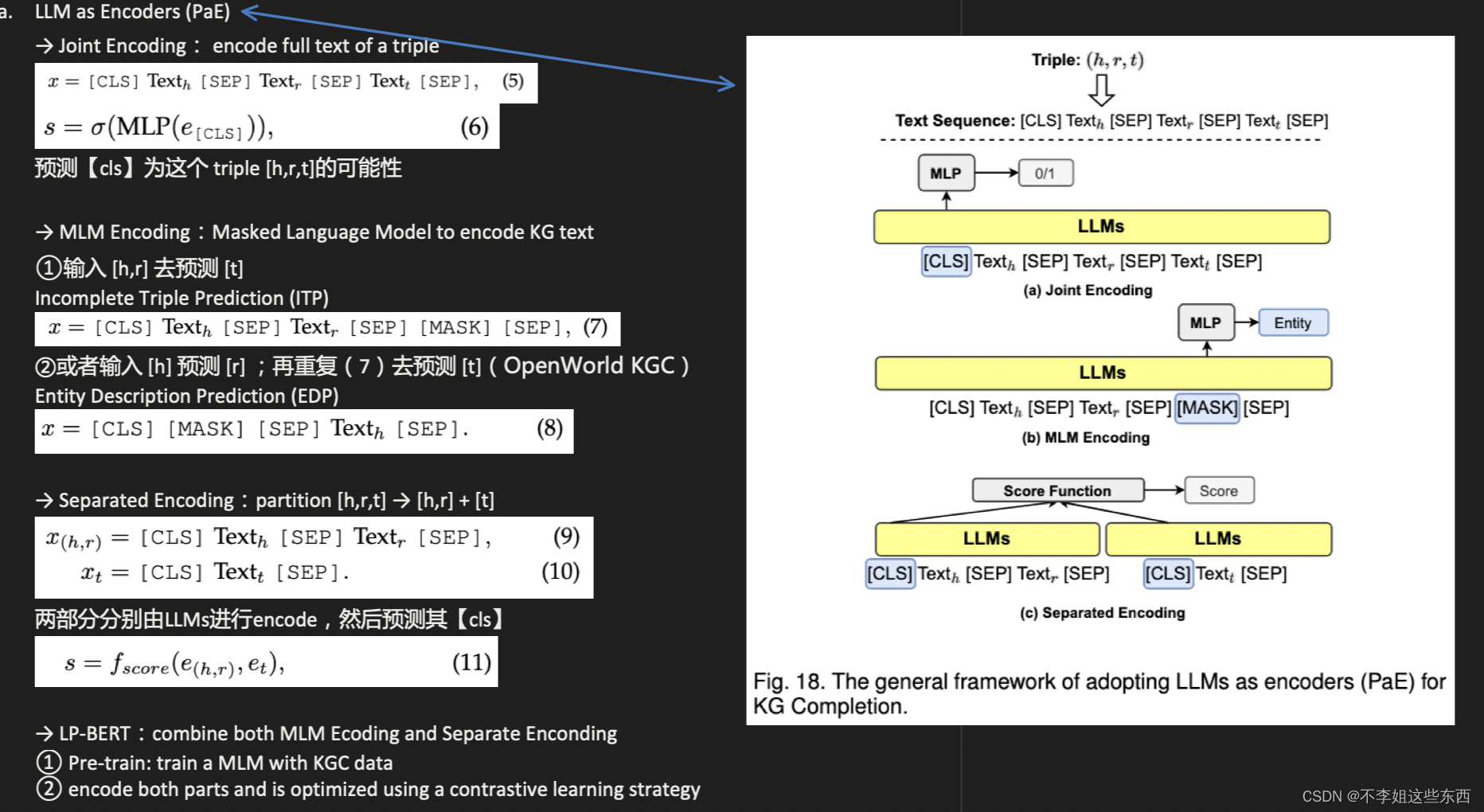
- LLM as Encoders (PaE)
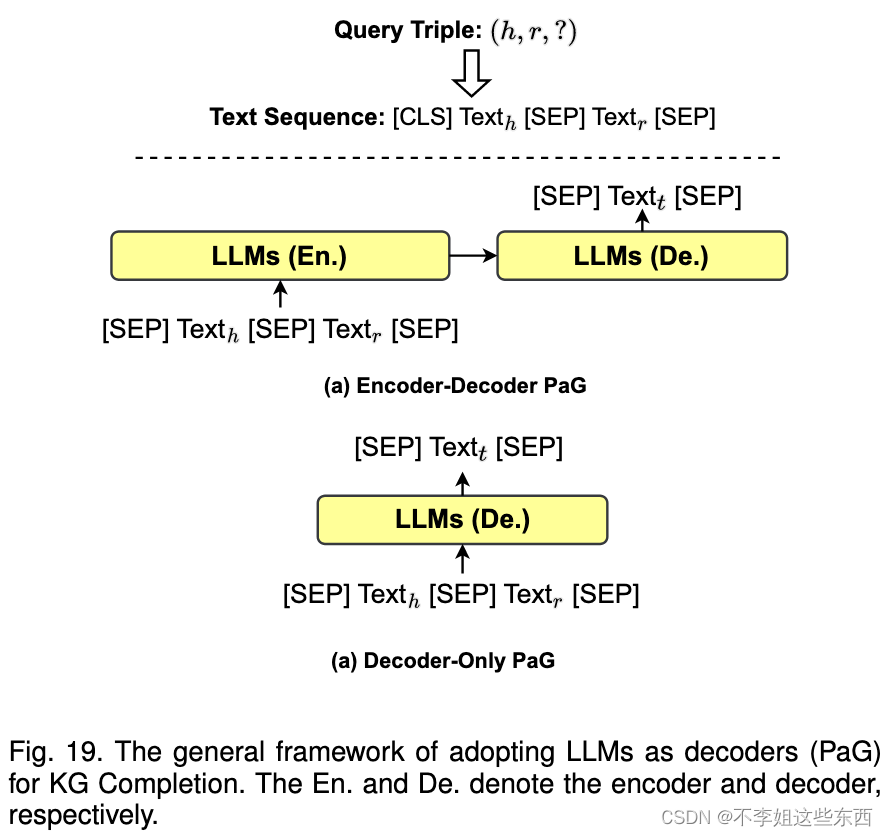
- LLM as Generators (PaG)
采用encoder-decoder or decoder-only LLMs,输入 [h,r,?] 生成尾部实体[t]
对于不开源代码的LLM(chatGPT 、GPT-4)使用prompt engineering去做
知识图谱构建
知识图构建涉及在特定领域内创建知识的结构化表示。这包括识别实体及其彼此之间的关系。
知识图谱文本生成
目标是生成准确、一致地描述输入知识图信息的高质量文本
知识图谱问答(KGQA)
协同大语言模型和知识图谱
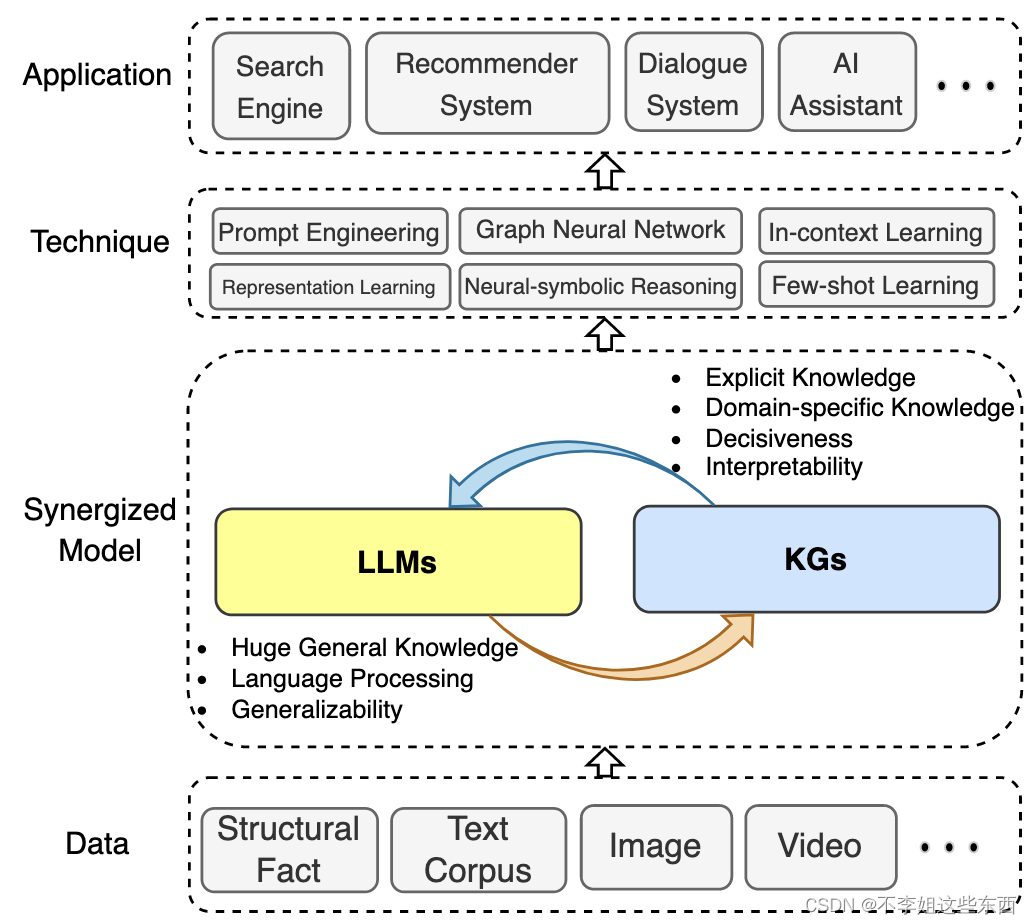
-
knowledge representation
文本语料和知识图谱都包含大量的知识,然而文本预料中的知识是隐性和无结构的;知识图谱中的是显性和结构性的。 -
reasoning
未来研究方向
-
利用知识图谱解决LLMs面临的幻觉问题
进一步的研究将LLM和KGs结合起来,实现了一个通用的事实核查模型(generalized fact-checking model),可以跨领域检测幻觉。 -
用知识图谱更新LLMs中的知识
LLM无法像现实世界一样快速更新存储的知识。有些人研究了不重新训练LLM的情况下去更新其知识,但是表现不好并且开销大。用人研究的用KGs更新LLM知识,但仅限于处理KGs中基于元组的简单知识
挑战:灾难性遗忘和错误的知识编辑(catastrophic forgetting and incorrect knowledge editing ) -
知识图谱注入黑盒LLM
上述方法需要更新网络结构和模型参数从而更新LLM,然而有一些LLM(ChatGPT)无法这样。因此要转化知识为不同的文本prompt,问题在于不清楚这些prompt能否推广到新LLM中,并且受到LLM输入的tokens数量的限制。
探索如何为black-box LLM实施有效的知识注入。 -
多模态LLM强化知识图谱
利用多模态LLM对模态对齐(modality alignment) -
理解图结构的大模型
LLM由文本数据训练,不理解知识图谱中的结构数据。简单解决方法是将结构化数据转化为LLM可以理解的句子。然而KG结构不一定能全部转化为句子,并且转化过程会损失一部分信息。
开发能够直接理解KG结构的LLM -
用于二元推理的协同LLM和知识图谱(Synergized LLMs and KGs for Birectional Reasoning)
这篇关于LLM+KGs综述:Unifying Large Language Models and Knowledeg Graphs: A Roadmap的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)