本文主要是介绍Action Recognition with an Inflated 3D CNN | TF Hub,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
action_recognition_with_tf_hub
recognizing actions in video data using the tfhub.dev/deepmind/i3d-kinetics-400/1 module
More models to detect actions in videos can be found here
解读: 用 tfhub.dev/deepmind/i3d-kinetics-400/1 模块去识别视频数据里的动作
The underlying model is described in the paper Action Recognition? A New Model and the Kinetics Dataset, CVPR 2017 conference paper. The source code is publicly available on github
解读: 论文和代码自取
the inflated 3D Convnet or I3D, video classification
This architecture achieved state-of-the-art results on the UCF101 and HMDB51 datasets from fine-tuning these models
The original module was trained on the kinetics-400 dataset and knows about 400 different actions. Labels for these actions can be found in the label map file
recognize activites in videos from a UCF101 dataset
解读: 用在 Kinetics-400 Dataset 上训练的模型去识别 UCF101 数据集上的 Video
# TensorFlow and TF-Hub modules.
from absl import loggingimport tensorflow as tf
import tensorflow_hub as hub
from tensorflow_docs.vis import embedlogging.set_verbosity(logging.ERROR)# Some modules to help with reading the UCF101 dataset.
import random
import re
import os
import tempfile
import ssl
import cv2
import numpy as np# Some modules to display an animation using imageio.
import imageio
from IPython import displayfrom urllib import request # requires python3# Utilities to fetch videos from UCF101 dataset
UCF_ROOT = "https://www.crcv.ucf.edu/THUMOS14/UCF101/UCF101/"
_VIDEO_LIST = None
_CACHE_DIR = tempfile.mkdtemp()
# As of July 2020, crcv.ucf.edu doesn't use a certificate accepted by the
# default Colab environment anymore.
unverified_context = ssl._create_unverified_context()if not _VIDEO_LIST:index = request.urlopen(UCF_ROOT, context=unverified_context).read().decode("utf-8")videos = re.findall("(v_[\w_]+\.avi)", index)_VIDEO_LIST = sorted(set(videos))

一共有 13320 个视频

def list_ucf_videos():"""Lists videos available in UCF101 dataset."""global _VIDEO_LISTif not _VIDEO_LIST:index = request.urlopen(UCF_ROOT, context=unverified_context).read().decode("utf-8")videos = re.findall("(v_[\w_]+\.avi)", index)_VIDEO_LIST = sorted(set(videos))return list(_VIDEO_LIST)def fetch_ucf_video(video):"""Fetchs a video and cache into local filesystem."""cache_path = os.path.join(_CACHE_DIR, video)if not os.path.exists(cache_path):urlpath = request.urljoin(UCF_ROOT, video)print("Fetching %s => %s" % (urlpath, cache_path))data = request.urlopen(urlpath, context=unverified_context).read()open(cache_path, "wb").write(data)return cache_path# Utilities to open video files using CV2
def crop_center_square(frame):y, x = frame.shape[0:2]min_dim = min(y, x)start_x = (x // 2) - (min_dim // 2)start_y = (y // 2) - (min_dim // 2)return frame[start_y:start_y + min_dim, start_x:start_x + min_dim]def load_video(path, max_frames=0, resize=(224, 224)):cap = cv2.VideoCapture(path)frames = []try:while True:ret, frame = cap.read()if not ret:breakframe = crop_center_square(frame)frame = cv2.resize(frame, resize)frame = frame[:, :, [2, 1, 0]]frames.append(frame)if len(frames) == max_frames:breakfinally:cap.release()return np.array(frames) / 255.0def to_gif(images):converted_images = np.clip(images * 255, 0, 255).astype(np.uint8)imageio.mimsave('./animation.gif', converted_images, fps=25)return embed.embed_file('./animation.gif')# Get a sample cricket video.
video_path = fetch_ucf_video("v_CricketShot_g04_c02.avi")
sample_video = load_video(video_path)
to_gif(sample_video)

video_list = list_ucf_videos()[:2]
# Get a sample cricket video.
for video in video_list:fetch_ucf_video(video)# Get the kinetics-400 action labels from the GitHub repository.
KINETICS_URL = "https://raw.githubusercontent.com/deepmind/kinetics-i3d/master/data/label_map.txt"
with request.urlopen(KINETICS_URL) as obj:labels = [line.decode("utf-8").strip() for line in obj.readlines()]
print("Found %d labels." % len(labels))# Get the list of videos in the dataset.
ucf_videos = list_ucf_videos()categories = {}
for video in ucf_videos:category = video[2:-12]if category not in categories:categories[category] = []categories[category].append(video)
print("Found %d videos in %d categories." % (len(ucf_videos), len(categories)))for category, sequences in categories.items():summary = ", ".join(sequences[:2])print("%-20s %4d videos (%s, ...)" % (category, len(sequences), summary))

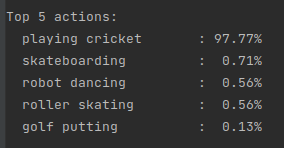
i3d = hub.load("https://tfhub.dev/deepmind/i3d-kinetics-400/1").signatures['default']def predict(sample_video):# Add a batch axis to the to the sample video.model_input = tf.constant(sample_video, dtype=tf.float32)[tf.newaxis, ...]logits = i3d(model_input)['default'][0]probabilities = tf.nn.softmax(logits)print("Top 5 actions:")for i in np.argsort(probabilities)[::-1][:5]:print(f" {labels[i]:22}: {probabilities[i] * 100:5.2f}%")predict(sample_video)
下面是预测输出
这篇关于Action Recognition with an Inflated 3D CNN | TF Hub的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








