本文主要是介绍83 票房线性回归 Linear regression of film box office,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 数据统计与预览
library(raster)
a = read.csv("film.csv", header = T) ##读入数据,不要将字符串视为factor
summary(a) ##查看数据基本情况,检查缺失情况
a = na.omit(a) ##将数据集里全部NA所在行删除
film_high = a[which.max(a$boxoffice),] ##查看票房最高纪录
film_low = a[which.min(a$boxoffice),] ##查看票房最低纪录

2 数据预览
library(wordcloud)
col<-brewer.pal(8,"Accent")
h<-hist(a$boxoffice,breaks=12,col=col)
xfit <-seq(min(a$boxoffice),max(a$boxoffice),length=40)
yfit <-dnorm(xfit,mean=mean(a$boxoffice),sd=sd(a$boxoffice)) #dnorm返回的是正态分布概率函数值
yfit <- yfit*diff(h$mids[1:2]) *length(a$boxoffice)
lines(xfit,yfit,col='red',lwd=2)
summary(a$boxoffice)
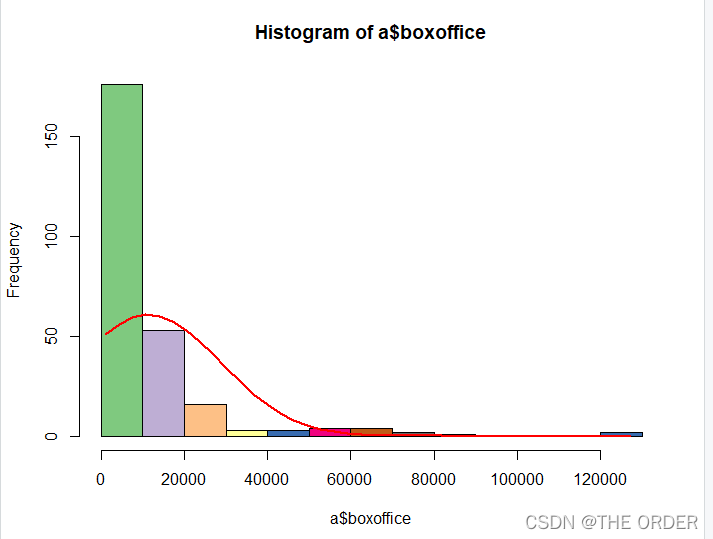
数据右偏分布数据,对y取对数处理
3 分箱处理数据与预览
##票房直方图
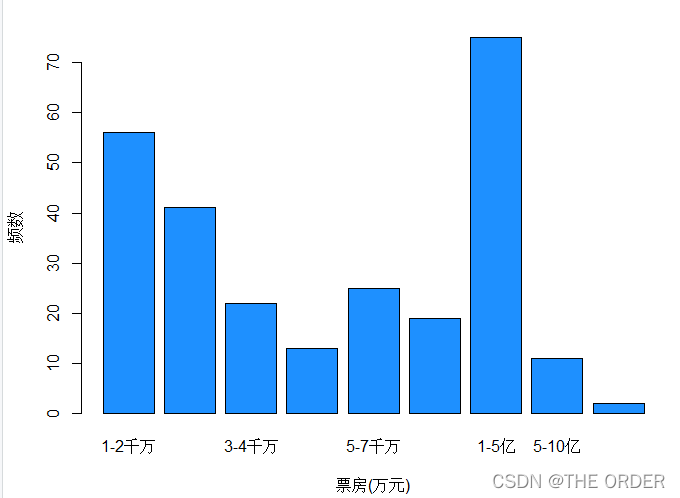
boxbar<-as.data.frame(table(cut(a$boxoffice,breaks=c(1000*(1:5),7000,10000,50000,100000,130000),labels=c('1-2千万','2-3千万','3-4千万','4-5千万','5-7千万','7千万-1亿','1-5亿','5-10亿','大于10亿'))))
barplot(boxbar$Freq,names.arg=boxbar$Var1,col="dodgerblue",xlab="票房(万元)",ylab="频数")as.data.frame(table(a$genre))
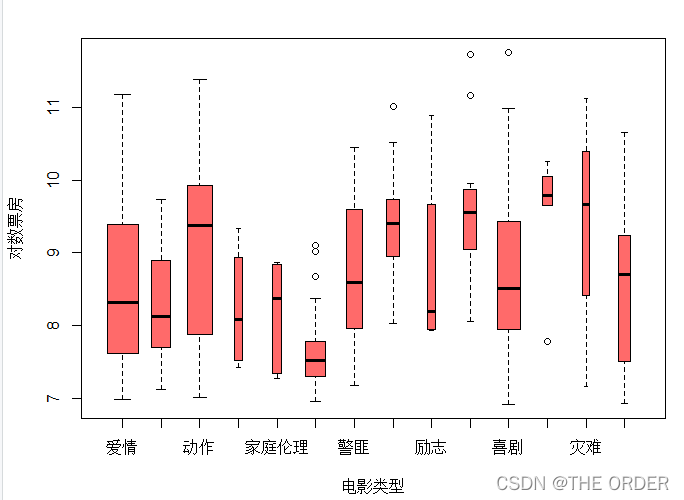
boxplot(log(boxoffice)~genre,xlab="电影类型",data=a,col="indianred1",ylab="对数票房",varwidth=T) ##电影类型箱线图
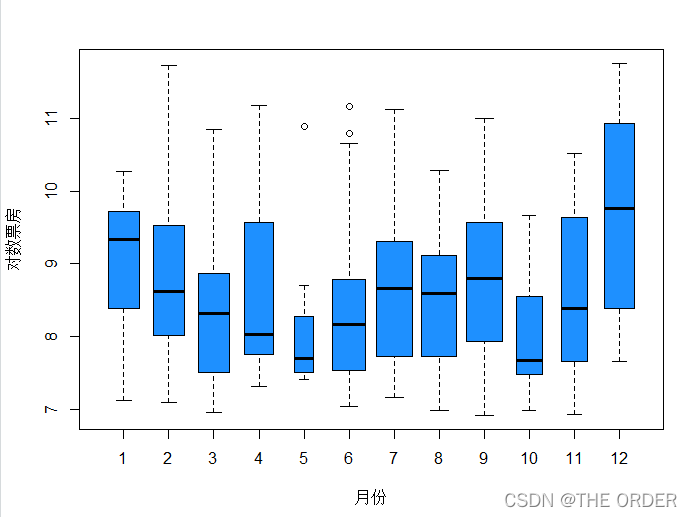
as.data.frame(table(a$month)) ##上映月份统计
boxplot(log(boxoffice)~month,xlab="月份",data=a,col="dodgerblue",ylab="对数票房",varwidth=T) ```
4 完成数据清理函数
dataclean<-function(a){a$dangqi<-cut(a$month,breaks=c(0,2,4,6,9,11),labels=c('贺岁档','普通档','黄金1档','暑期档','黄金2档'))a$dangqi[is.na(a$dangqi)]<-'贺岁档'a$distribute<-factor(a$distribute,levels=c('C','G','L','S'),labels=c('联合发行','国有宣发','小私营公司','明星私企'))a$reality<-factor(a$reality,levels=c(0,1),labels=c('否','是'))a$story<-factor(a$story,levels=c('N','S'),labels=c('原创','虚构'))a$remake<-factor(a$remake,levels=c(0,1),labels=c('否','是'))a$sequel<-factor(a$sequel,levels=c(0,1),labels=c('否','是'))a$导演得奖情况<-factor(a$导演得奖情况,levels=c(0,1),labels=c('否','是'))a$导演是否转型<-factor(a$导演是否转型,levels=c(0,1),labels=c('否','是'))a$导演年代[a$导演年代<50]="50以下" ##将30和40年代合并为50以下a$导演年代=factor(a$导演年代,c("50以下","50","60","70","80")) ##更改因子水平顺序return(a)a<-dataclean(a)
table(a$dangqi) ##上映档期统计
boxplot(log(boxoffice)~dangqi,xlab="档期",data=a,col="yellow",ylab="对数票房",varwidth=T) ##上映档期箱线图table(a$distribute) ##宣发公司统计
boxplot(log(boxoffice)~distribute,xlab="宣发公司",data=a,col="dodgerblue",ylab="对数票房",varwidth=T) ##宣发公司箱线图par(mfrow=c(2,2)) ##输出2行2列图形
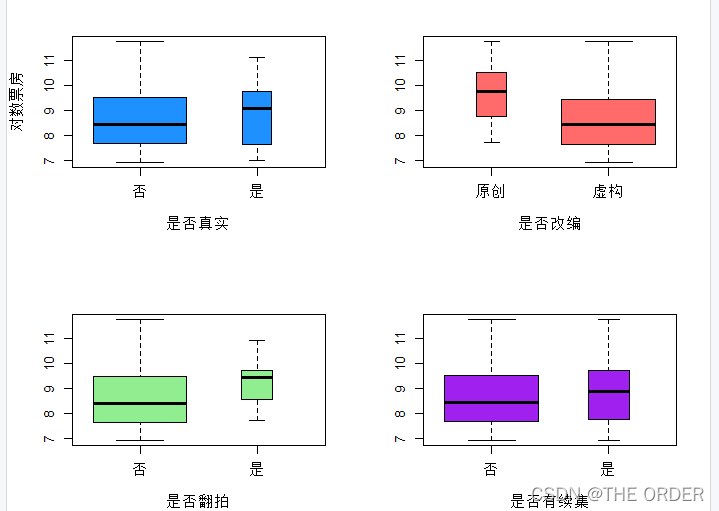
boxplot(log(boxoffice)~reality,data=a,col=c("dodgerblue"),ylab="对数票房",xlab="是否真实",varwidth=T) ##是否真实
boxplot(log(boxoffice)~story,data=a,col=c("indianred1"),ylab="",xlab="是否改编",varwidth=T) ##是否原创
boxplot(log(boxoffice)~remake,data=a,col=c("lightgreen"),ylab="",xlab="是否翻拍",varwidth=T) ##是否翻拍
boxplot(log(boxoffice)~sequel,data=a,col=c("purple"),ylab="",xlab="是否有续集",varwidth=T) ##是否续集par(mfrow=c(1,2)) ##输出1行2列图形
boxplot(log(boxoffice)~导演得奖情况,data=a,col=c("indianred1"),ylab="对数票房",xlab="",main="导演获奖 vs 票房",varwidth=T) ##导演是否获奖
boxplot(log(boxoffice)~导演是否转型,data=a,col=c("purple"),ylab="",xlab="",main="导演转型 vs 票房",varwidth=T) ##导演是否转型
par(mfrow=c(1,1))
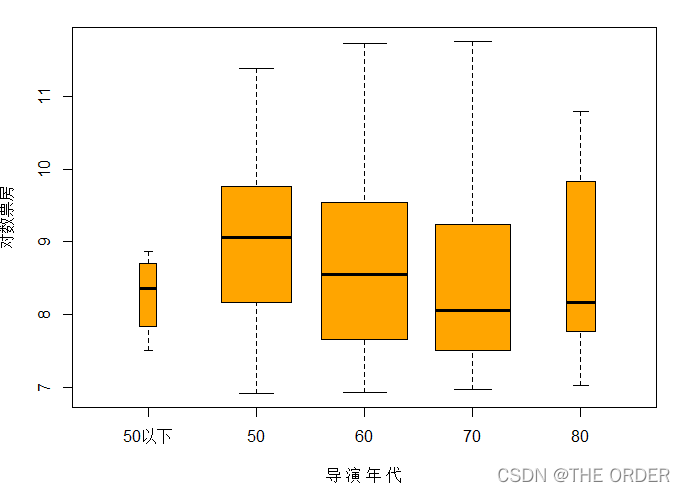
## 在比较导演年代时,我建议把30和40的统计归为50年代以下,这样不需要删样本
boxplot(log(boxoffice)~导演年代,data=a,col=c("orange"), ##不同年代导演的区别ylab="对数票房",xlab="导 演 年 代",varwidth=T)
table(a$导演年代)
summary(a$boxoffice)
lm=lm(log(boxoffice)~genre+as.factor(year)+runtime+dangqi+distribute+reality+story+remake+sequel+导演得奖情况+导演是否转型,data=a) ##拟合线性模型
summary(lm) ##给出估计结果
lm_s<-step(lm,direction="both")
summary(lm_s)
plot(resid(lm_s)~predict(lm_s))
abline(h=0)
sum(resid(lm_s)^2)/sum(predict(lm_s))
5 建模与评估
lm=lm(log(boxoffice)~genre+as.factor(year)+runtime+dangqi+distribute+reality+story+remake+sequel+导演得奖情况+导演是否转型,data=a) ##拟合线性模型
summary(lm) ##给出估计结果
lm_s<-step(lm,direction="both")
summary(lm_s)
plot(resid(lm_s)~predict(lm_s))
abline(h=0)
sum(resid(lm_s)^2)/sum(predict(lm_s))

残差占比
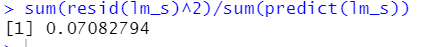
6 残差分析
residplot=function(fit,nbreak=10){z=rstandard(fit)hist(z,breaks=nbreak,freq=F,xlab="Resuduals",main="Distribution of Errors")curve(dt(x,1),add=T,col="blue",lwd=2)curve(dnorm(x,mean =mean(z),sd=sd(z)),add=T,col="green",lwd=2)legend("topright",legend=c("Normal Curve","t curve"),lty=1:2,col=c("green","blue"),cex=0.8)
}qqnorm(lm_s$residuals)
qqline(lm_s$residuals)
residplot(lm_s)
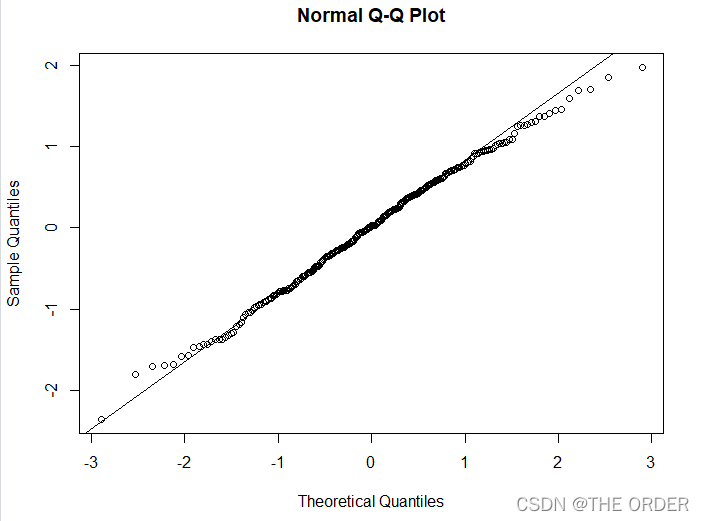
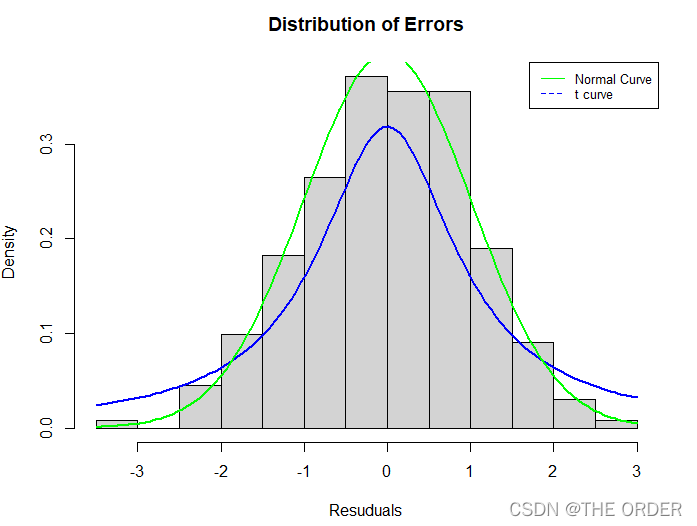
残差的结果符合正态性检验
7预测结果
library(car)
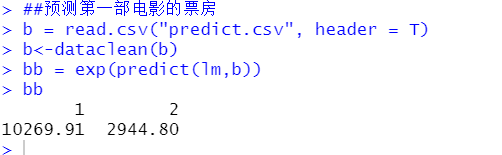
vif(lm_s) #vif##预测第一部电影的票房
b = read.csv("predict.csv", header = T)
b<-dataclean(b)
bb = exp(predict(lm,b))
bb
这篇关于83 票房线性回归 Linear regression of film box office的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






