本文主要是介绍论文解读--L-Shape Model Switching-Based Precise Motion Tracking of Moving Vehicles Using Laser Scanners,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
对移动物体的检测和跟踪是自动驾驶汽车最基本的功能之一。为了准确地估计运动物体的动态信息,激光扫描仪以其高精度的距离数据被广泛应用。然而,这些数据仅表示面对传感器的物体表面,并随着时间的推移改变物体的外观。这种更改会对估计的动态状态产生意外的跟踪错误。为了最小化外观变化引起的跟踪误差,本文提出了一种基于L-Shape模型切换的跟踪算法。该算法在实际交通实验中得到了验证,并通过精确GPS测量了位置、速度和航向误差。L-Shape跟踪算法成功地缓解了外观变化的影响,提高了估计性能。
索引术语-车辆跟踪,L-Shape模型,建模切换滤波器,激光扫描仪。
1.介绍
近年来,开发高度安全、便捷的车辆不仅受到市场客户的关注,也受到政府法规的关注。这些社会关注是开发智能汽车的驱动力,智能汽车为驾驶员提供有关驾驶环境的信息,从而实现辅助安全便捷的驾驶。最后,智能汽车技术的进化将实现无人驾驶汽车,无需人工干预,自动驾驶到目的地,这是智能汽车的最终目标。
为了实现成功的自动驾驶,需要定位、感知、路径规划和控制四个基本系统[1],[2]。各系统按如下顺序运行。首先,定位系统对自动驾驶汽车的当前位置进行高精度估计[3]-[6]。接下来,感知系统识别周围环境[7],[8]。然后规划系统根据感知系统[9],[10]的环境信息生成路径。最后,控制系统控制自动驾驶汽车沿着生成的路径行驶。
在这些系统中,已经研究了使用激光扫描仪识别车辆、行人和摩托车等移动物体的感知系统。一般来说,使用激光扫描仪的目标跟踪方法包括两个步骤;目标检测和目标跟踪。检测过程从分段点组[11],[12]中提取特征,生成以中心点为目标位置的包围框。在此之后,跟踪阶段使用动态状态估计和数据关联滤波器对检测结果进行操作。作为估计方法,卡尔曼滤波器(KF)及其变体(EKF, UKF)[13] -[17]被广泛应用。该方法结合了其中一种数据关联滤波器,如最近邻(NN)[13]、[14]、概率数据关联(PDA)[18]及其变化(联合PDA (JPDA)[13]、[19]、集成PDA (IPDA)[20]和联合IPDA (JIPDA)[21]。列出的跟踪算法通常用于许多跟踪应用程序,但它们在混乱的环境中受到影响。为了提高混沌环境下多目标跟踪性能,提出了多假设跟踪(MHT)[22],[23],粒子滤波(PF)[24],[25]和随机有限集(RFS)[26]。MHT提供了多个假设来跟踪测量的关联,并结合了假设中的所有概率。PF是一个基于名为“粒子”的样本的贝叶斯滤波器,它可以通过自身的概率分布来表示不确定性。RFS使用贝叶斯框架,考虑到与航迹和观测数量相关的概率。该算法在混沌环境下的多目标跟踪问题中表现出强大的估计性能,但需要大量的计算能力才能实现这种性能。
激光扫描仪是一种通过主动光源测量物体距离的光学设备。它产生一个或多个激光束到一个旋转的镜子上,扫描二维平面或三维空间。与雷达不同的是,在雨天和大雾天气,由于激光束的散射和折射,激光扫描仪的性能会下降。尽管激光扫描仪在这些天气条件下表现敏感,但大多数高度自动驾驶汽车都采用激光扫描仪,因为它提供了高分辨率和精度的密集距离信息。
然而,激光扫描仪只提供从面对传感器的物体表面的距离测量。因此,激光扫描仪无法看到物体的整个形状,点云的外观根据视点随时间的变化而变化。这种外观变化问题会在跟踪算法中引起意想不到的运动估计误差。
为了解决这一问题,提出了一种使用模糊线端点[27]的车辆跟踪方法。这种方法基于直线跟踪,但它有一个假设,即直线不能表示精确的大小。因此,行尾具有“模糊”属性,用于反映行长度的不确定性。利用大的纵向位置协方差对这些模糊线端点进行跟踪,以抑制较大的快速运动变化。虽然该方法可以成功地抑制停放车辆的纵向运动误差,但所减少的误差仅限于轨迹的纵向运动。
另一种解决外观变化问题的方法是使用先验知识[28]。在这种方法中,预先定义的形状类型(I形、IS形、L形、C形和E形)应用于具有不同动态模型的跟踪算法。该方法在跟踪具有各种动态类型的运动目标时是有效的。但是,在出现误分类的情况下,应用误分类动态模型是不合适的。此外,跟踪性能可能变得不稳定,因为形状类型的变化可能导致突然的动态模型变化。
另一种补偿外观变化的跟踪算法是基于几何模型的车辆跟踪[8]。2007年,斯坦福大学的Junior在DARPA城市挑战赛中使用了该算法。该算法引入了一个使用锚点的几何模型和一个应用粒子滤波的测量模型。几何模型估计了盒子的长度和宽度以及锚点的相对位置。利用几何模型,通过测量模型对每个点的信息进行评估,从而计算出每个粒子的似然。由于这种计算需要进行多次,因此该方法需要与粒子数量成正比的巨大计算能力。
论文[29],[30]描述了一种利用激光扫描仪数据的L-Shape拟合方法。作者通过对点数据的统计分析,对该方法的计算效率进行了评价。论文[31]提出了一种矩形的最优拟合方法,将车辆表示为有方向的二维包围框。这些方法只关注目标拟合问题,没有考虑目标跟踪问题。
论文[32]提出了一种L-Shape边缘模型,用于将激光扫描仪数据与相机和雷达信息相关联。论文[33]描述了一个具有异构传感器的三维几何模型,而论文[34]提出了一个能够表示非凸物体表面的详细形状模型。然而,这些方法结构复杂,需要大量的计算能力。
在本研究中,我们提出了一种结构简单的基于L-Shape模型切换的形状不变跟踪算法。我们采用L-Shape特征而不是盒型模型和U型特征,原因如下:(1)L-Shape特征和盒型模型一样,可以表示结构简单的形状不变轨迹点。(2) U型与曲面保险杠车辆的实际形状较为接近,但U型的表达和拟合过程比L-Shape特征提取更为复杂。
为了减轻外观变化的影响,所提出的算法跟踪由一个角点和两条线组成的L-Shape特征。为了减少由于外观变化带来的意外误差,所提出的跟踪算法跟踪目标的角点,而不是相对位置模糊的中心点。利用角点,跟踪点的相对位置不受形状变化的影响,可以成功减缓外观变化。角点有两种运动,即平动和旋转运动。因此,采用恒加速度模型作为预测模型。为了获得可靠的跟踪性能,所开发的算法在L-Shape模型切换中提供了一种不确定性传播的角点变化方案。此外,还提出了一种尺寸更新规则来减小尺寸变化带来的位置误差。
本文提出的车辆跟踪算法包括三个部分:L-Shape特征提取、L-Shape跟踪器和L-Shape到盒模型转换(图1)。首先,L-Shape特征提取是一个原始数据提取过程,从点云中提取L-Shape测量值。在特征提取方面,采用了聚类和线特征提取技术。其次,L-Shape跟踪器利用L-Shape测量值,利用动态模型和形状模型估计轨迹的动态状态。为了实现L-Shape跟踪器,采用了卡尔曼滤波器和最近邻算法,因为KF-NN结构简单,可以专注于模型切换框架。这种简单的结构也有潜力改进所提出的方法与先进的跟踪算法,如MHT, PF和RFS。同时,提出了一种L-Shape模型切换方案,用于跟踪角点发生变化时的动态状态检测和补偿。最后,将L-Shape轨迹转换为盒形轨迹,以表示目标的准确位置和速度。在这一步中,消除角点的旋转运动来描述实际的目标运动。
本文组织结构如下。第二节描述了L-Shape特征提取过程。第三节介绍了L-Shape跟踪器,它是一种L-Shape模型切换与跟踪算法。第四节介绍了L-Shape到盒模型的转换。第五节对所提算法的评价结果进行了分析。第六节是结论部分,总结了评价结果和今后的工作。
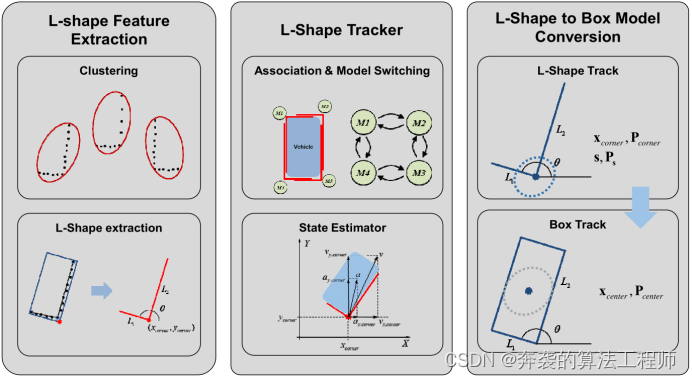
图1:L-Shape跟踪算法的整体结构,包括L-Shape特征提取、L-Shape跟踪器和L-Shape到包围盒模型的转换。
2.L-Shape特征提取
激光扫描仪生成的原始数据是一组表示到障碍物距离的点。为了将这些点转换为有意义的信息,这些点被聚类并抽象为L-Shape特征。然而,驾驶环境中的聚集点云形状各异。该方法主要针对车辆进行检测和跟踪。由于大多数车辆都是盒形的,L-Shape特征对于表示结构简单的车辆是有效的。
从非L-Shape点云中提取L-Shape特征的关键问题是方向误差。从圆形物体中很难提取方向,因为物体缺乏方向。对于车辆来说,由于保险杠是弯曲的,点云一般是U-Shape的。这种弯曲保险杠可以安装一个方向误差,这主要是在10度以内,因为决定方向的最长线是从保险杠的平面上提取出来的。这种水平的方向误差可以被L-Shape跟踪算法抑制。
本研究采用自适应断点检测器对点云进行聚类,并采用迭代端点拟合方法从每个聚类中提取线[12]。然后,根据提取的线确定L-Shape特征。
A.聚类
聚类是用关联点表示对象的分组过程。在这一阶段,为了应用自适应断点检测器,将激光扫描仪的点表示在极坐标系统中。然后,按角度的顺序对点进行排序。如图2所示,如果角度顺序上两个连续点之间的距离在阈值距离(Dth)内,则将这两个点分配到同一个聚类中。自适应断点检测器提供自适应阈值距离
![]() (1)
(1)
这里ri和ri-1是连续点的距离信息,Δθ是两点之间的角度差,λ是确定点是否属于相同类的可接受角度,σr是距离量测的噪声标准差。
(1)式采用不同的阈值距离对近距离的密集点云和远距离的稀疏点云进行聚类。
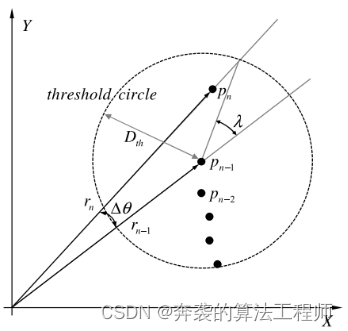
图2:自适应断点检测器在极坐标系统中比较具有阈值距离(描述为阈值圆)的连续两点以分配聚类。
B.线型提取
图3显示了使用迭代端点拟合的直线提取方法。该方法从两个端点开始。在聚类点中,选取角度最小和最大的两个点作为聚类的初始端点(图3 (a),蓝圈点)。由初始端点设置基线,并计算基线到聚类中每个点的距离(图3 (a))。之后,如图3 (b)所示,确定距离最长的点(Dmax)为断点(红圈点)。利用断点将基线划分为两条线,如图3 (c)所示。同样地,每条线都被划分到最大距离小于阈值距离(Dsplit)。然后,应用合并过程,以防止由于换行错误而创建过多的行。为了减少换行错误的数量,在合并过程中,彼此相邻的共线被表示为一行。
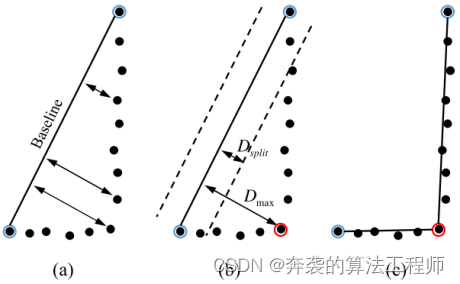
图3:迭代端点拟合法的线分割过程(a)起始终点基线,(b)断点确定,(c)分线结果
C.L-Shape提取
利用提取的直线,对聚类进行有向包围盒拟合。在提取的直线中,选取最长的直线作为代表线,确定包围盒的方向。确定方向后,拟合边界盒的最小面积[35],[36]。利用包围盒提取出距离盒角点最近的L-Shape特征,与角点相连的两条直线如图4所示。
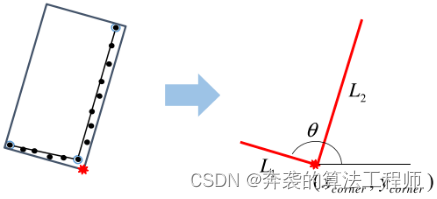
图4:在边界框的四个角点中,选择一个最接近自车的激光扫描仪的角点作为具有连接线的L-Shape特征角点。
因此,L形特征包含了角点的位置(xcorner、ycorner)、两条线的长度(L1、L2)和方向(θ)。L-Shape特征的L1和L2按顺时针方向分配,按L1、直角和L2的顺序排列。方向θ被定义为L1的方向。l形特征提供了两种类型的测量方法;
一个是用于更新动态状态的动态测量(zD),另一个是用于更新L-Shape跟踪器中的形状状态的形状测量(zS)为
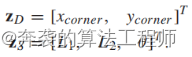 (2)
(2)
3.L-Shape跟踪
L-Shape跟踪器使用带有最近邻数据关联的卡尔曼滤波器[16]来估计轨迹的动态状态和形状状态。为了精确地估计跟踪器的动态状态,L-Shape跟踪器不仅采用了动态模型,而且还采用了形状模型。该估计算法还包括一个L-Shape模型切换方案,以根据外观变化来补偿角点切换。
A.跟踪模型
对于L-Shape跟踪,提出了两种跟踪模型;一种是动态模型,另一种是形状模型。动态模型表示轨迹的运动,形状模型估计了L-Shape形状的大小、方向和偏航率,以补偿外观的变化。
1)动态模型:动态模型包括角点的位置(x、y)、速度、vx、vy )和加速度(ax、ay)等信息,如图5所示。图5中引入的动态信息用图中的向量xD表示
![]() (3)
(3)
由于角点运动是平移运动和旋转运动的结合,因此角点的运动可以用下式中的恒定加速度模型来描述
 (4)
(4)
其中下标k为离散时域的当前时间步长,FD为表示常数加速度的过程矩阵,Ts为采样时间,N(0,QD)为均值为零,协方差矩阵为零的动态模型的高斯噪声。
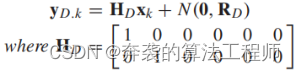 (5)
(5)
传感器的可测量数据为位置信息,动态状态的测量模型为(5),其中HD为测量矩阵,N(0,RD)为测量噪声,表示为均值和协方差矩阵为零的高斯分布RD。
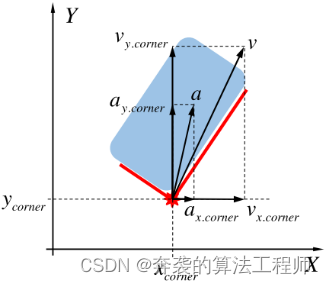
图5:该动态模型描述了角点的运动信息
2)形状模型:形状模型由线长(L1、L2)、L1方向(θ)方向和偏航率(ω)组成,如图6所示。图6中所描述的形状信息反映在向量s中,分别为
![]() (6)
(6)
对于形状信息的估计,将静态模型应用于线长,因为目标大小不会随时间变化。由于偏航率在短时间内也没有很大的变化,因此对方向和偏航率采用了恒定转弯率模型。
 (7)
(7)
其中FS是过程矩阵,其中包含线长的静态模型和方向和偏航率的恒定转弯率模型,Ts是采样时间,N(0,QS)是均值和协方差为零的高斯分布的过程噪声。
在形状模型的状态中,线长和方向是传感器可测量的数据。因此,形状模型的测量模型如下。
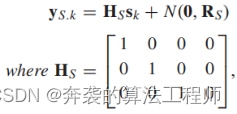 (8)
(8)
其中,HS为形状模型的测量矩阵,N(0,RS)为测量噪声,其中Rs为均值和协方差为零的高斯分布。
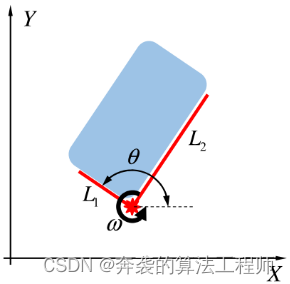
图6:形状模型显示了目标的尺寸、L-Shape的方向和偏航率。
B.预测
根据轨迹模型,利用采样时间预测了估计的轨迹状态。同时,利用卡尔曼滤波器的预测方程来传递轨迹的不确定性。
1)动态状态预测:根据动态模型对角点的动态状态进行预测。从前一个时间步长的后验状态(xk−1|k−1)开始,计算出当前时间步长的先验状态(xk|k−1)
![]() (9)
(9)
前一步的不确定性(PD,k−1|k−1)也被传递到当前的先验不确定性(PD,k|k−1)
![]() (10)
(10)
2)形状预测:轨迹的形状信息也由形状模型进行预测。利用形状模型从先验后验状态(Sk−1|k−1)预测形状信息的先验状态(Sk|k−1)。与动态的不确定性传递类似,先验不确定性(PS,k|k−1)可以从之前的后验不确定性(PS,k−1|k−1)中预测。
![]() (11)
(11)
![]() (12)
(12)
(11)和(12)表示形状信息的预测方程。
C.模型切换和数据关联
L-Shape模型是基于最接近自车的激光扫描仪的角点,可以根据目标车辆的姿态进行改变。所提出的跟踪算法提供了一种补偿角点变化的方案。
图7显示了角点变化场景的一个示例。角点可以更改为相邻的角点,顺时针和逆时针。用第一个检测到的角点初始化的新轨迹开始用一号模型(M1)跟踪目标车辆。然后,根据自车的目标姿态和视点,型号会随着角点的切换而增加或减少。
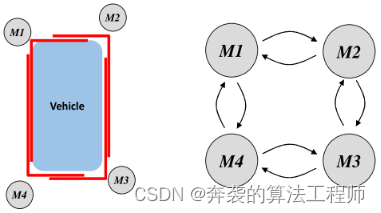
图7:轨迹的每个角点都有一个从M1到M4的型号。当检测到的拐角点被改变时,型号也会被改变。
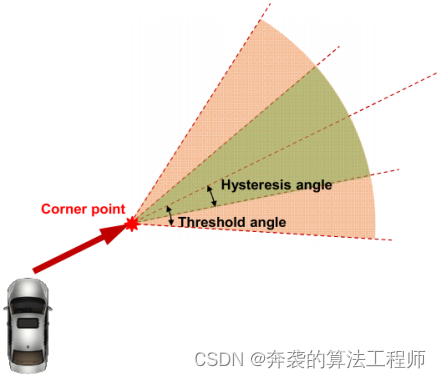
图8:通过比较L-Shape模型的视角和方向,进行了L-Shape模型的过渡检测。
1)模型过渡检测:在模型过渡检测阶段,对L-Shape轨迹进行评估,以检测角点的变化。通过利用L1和L2的视角和方向来进行评估。如图8所示,如果方向在阈值角范围内,则检测到模型的过渡。
但是,如果目标的航向角接近于视角,则经常检测到模型转换。为了防止频繁的过渡,采用了一个滞后角,如图8所示。在滞后角度内,轨迹不会改变模型,而是将测量值转换为匹配轨迹。
a)顺时针测量转换:顺时针测量转换沿线L1切换角点。转换后的角点位置(xcorner,cw、ycorner,cw)计算
 (13)
(13)
然后,切换线的长度(L1,cw、L2,cw),并使用下式根据切换后的L1、cw来旋转方向
 (14)
(14)
b)逆时针测量转换:同样地,逆时针测量转换沿线L2切换拐角点。转换后的角点的位置、线的长度和方向由以下方程式推导出。
![]() (15)
(15)
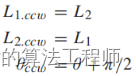 (16)
(16)
2)角点切换:在模型转换检测完成后,当检测到模型转换时,角点应切换到另一个角点。切换动态状态的计算是基于形状模型的。角点切换有两种类型,顺时针切换和逆时针切换。
如图7所示,有4个角点,从M1到M4,每个点都分配一个型号。轨迹初始化后,轨迹型号分配为M1。如果按顺时针方向切换角点,则型号将会增加。否则(逆时针切换),型号就会减少。
a)顺时针切换:切换角点的位置沿L1移动。
 (17)
(17)
式(17)表示角点与先前角点位置的切换位置。上标Mi和Mj分别为切换前和切换后的型号。
通过对旋转运动的补偿,可以得到切换角点的速度和加速度。假设轨迹的旋转运动是一个具有当前横摆率的恒定旋转率模型。在此假设上,可以得到切换后角点的速度和加速度。
 (18)
(18)
 (19)
(19)
b)逆时针切换:与逆时针开关相同,通过逆时针切换由下式计算到的角点的动态信息。
 (20)
(20)
 (21)
(21)
 (22)
(22)
3)不确定性传递:切换的角点位于前一个形状模型的线端。由于线长和方向是具有不确定性的估计值,因此形状的不确定性会影响到切换的角点的动态信息。因此,切换角点的不确定度应反映出形状的不确定度,如图9所示。利用角点切换方程的雅可比矩阵进行线性变换,计算出传递的协方差矩阵。
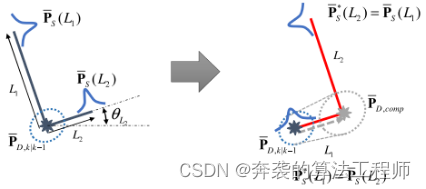
图9:当L-Shpae模型切换时的不确定性传递。
切换角点的每个动态状态都可以用下式表示
![]() (23)
(23)
通过使用(23),我们可以得到一个雅可比矩阵,不确定性传递采用线性变换,如下式所示。
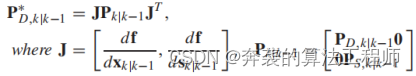 (24)
(24)
4)最近邻关联:在基于卡尔曼滤波的算法中,为了解决多目标跟踪问题,数据关联是航迹与测量匹配的重要组成部分。由于激光扫描仪可以提供精确的点云,且很少产生杂波,因此本研究采用最近邻关联作为数据关联方法。最近邻关联使用马氏距离将测量值与跟踪值匹配。马氏距离(DM)由残差(vD)和残差协方差(SD)决定
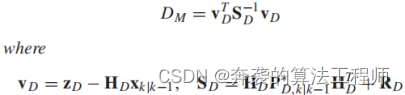 (25)
(25)
对于每个测量值,都要计算马氏距离,并且距离最短的轨迹与测量值相匹配。
D.更新
1)动态状态更新:使用卡尔曼滤波更新方程更新动态状态和不确定度如下。
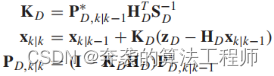 (26)
(26)
其中,KD为动态状态更新的卡尔曼增益。
2)形状更新:对于形状状态更新,一个附加的更新规则被应用于卡尔曼滤波器更新过程。形状状态的线长信息与传感器检测到的外观直接相关。由于传感器总是检测到一个比实际物体的实际尺寸更小的尺寸,所以尺寸增长应该用一个比尺寸缩小更大的权重因子来更新。尺寸更新的权重因子由先前尺寸与当前测量尺寸的比率决定,如下所示
 (27)
(27)
因此,测量噪声协方差(RS)受到加权因子的影响,因为尺寸增长意味着测量值正在接近真实值。
补偿后的测量噪声协方差会影响形状信息的残差协方差(SS),如图所示.
![]() (28)
(28)
这种效应通过剩余协方差(SS)传递到形状KS的卡尔曼增益。
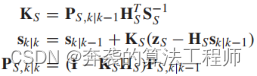 (29)
(29)
4.L-Shape到包围盒模型的转换
角点的动态状态包括目标的旋转运动。L-Shape到箱形模型的转换阶段是计算目标的动态状态的过程。通过消除旋转运动,可以从角点的动态状态中计算出目标的动态状态。
A.动态状态转换
在此阶段中,动态状态从角点运动变为目标运动。该位置可以利用形状模型的几何信息进行转换。角点的速度是目标速度和在角点处旋转运动的切向速度的和。角点的加速度也是目标加速度和旋转加速度到目标几何中心的和。
1)位置转换:利用几何信息可以很容易地计算出包围盒中心的位置。从线的长度和方向上看,中心点的位置由下式获取
![]() (30)
(30)
2)速度转换:角点的速度包括平移速度和旋转速度。假设角点的旋转运动是一个均匀的圆周运动,因为我们已经假设了形状模型有一个恒定的转弯率模型。因此,我们可以利用距离中心的距离作为圆周运动的半径,推导出切向速度的方程。
 (31)
(31)
3)加速度转换:与速度转换类似,可以通过消除旋转加速度来获得加速度信息。旋转加速度也可以由角点的均匀圆周运动得到。
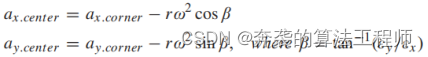 (32)
(32)
B.不确定性转换
不确定度转换过程与模型切换阶段的不确定度传递过程相同。为了找到转换的线性变换关系,利用动态状态转换关系计算了一个雅可比矩阵。因此,我们计算出了转换后的协方差。
![]() (33)
(33)
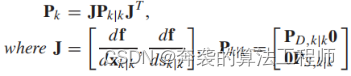 (34)
(34)
5.实验
A.实验环境
所提出的跟踪系统用10 (a)所示的测试车辆进行了评估在前保险杠上,安装了三个激光扫描仪。每个激光扫描仪可以在85°范围内检测到200米以内的障碍物。水平扫描的角分辨率为0.125°,垂直角分辨率为0.8°,扫描频率为12.5 Hz。安装的激光扫描仪可以扫描多层扫描。安装在保险杠中心和左侧的两个激光扫描仪是4线激光扫描仪。在保险杠的右侧,安装了一个8线激光扫描仪来检测道路边界,如路缘。传感器的视场(FOV)如图10 (b)所示。
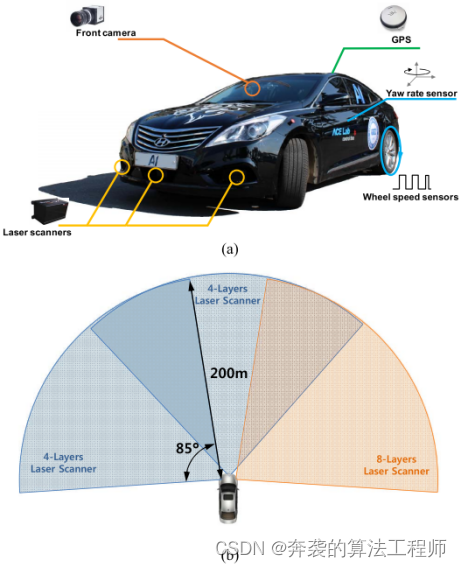
图10:测试车辆的传感器配置和已安装的激光扫描仪的FOV。(a)所提出的算法使用激光扫描仪、偏航率传感器和车轮速度传感器。采用GPS和前置摄像头对算法进行了评价。在(b)激光扫描仪中,在前保险杠的中心和左角安装4线激光扫描仪,在前保险杠的右角安装了8线激光扫描仪。
在本研究中,L-Shape特征为二维信息。然而,所安装的激光扫描仪提供了笛卡尔坐标系中每个点的三维位置信息。为了应用该算法,将三维信息投影到一个x-y平面(基平面)上。然后,将投影点转换为极坐标系,应用自适应断点检测器。该算法每80 ms工作一次,与激光扫描仪的采样时间相同。该跟踪算法提供了多目标跟踪功能,并管理多达150条跟踪。该方法在一台具有i5-4690 CPU和8 GB RAM的机器上进行了测试。该算法在Windows操作系统下使用MS Visual Studio 2013实现。在97.5%的操作时间内,每个时间步的执行时间都在5ms以内。
为了评价所提方法的性能,我们需要目标车辆的地面真实状态作为参考数据。不幸的是,我们无法知道目标的真实状态。因此,我们建立了一个可以精确测量真实状态的系统。
自车和目标车都配备了高精度GPS(RTK-GPS)。利用GPS设备,测量了自车和目标车的位置和速度。利用每个GPS的全局时间戳进行测量信息的同步。测量数据通过后处理更精确地校正,这是应用使用车辆模型的平滑算法。由于RTK-GPS的误差界在10 cm以内,且位置信息通过平滑算法进行校正,因此可以假设后处理后的GPS信息为地面真实值。在此基础上,将该算法与嵌入在Ibeo Lux激光扫描仪中的包围盒跟踪算法进行了比较。Ibeo Lux每80 ms提供一个点云(原始数据)提供对象信息。对象信息包括对象的位置、速度、航向角、大小(长度和宽度)和类别。此外,该传感器还提供了位置和速度的标准偏差,由ID和年龄组成的管理信息,以及与相关的原始数据点相关的轮廓信息。使用该传感器,所提出的算法可以与商业上可获得的激光扫描仪的汽车应用进行比较。
在实验中,应该检查两种类型的信息。一个是关于算法如何减轻外观变化,另一个是关于估计性能。为了检查外观变化问题的缓解情况,我们监测了可以根据外观变化显示角点切换的型号,以及估计轨迹大小的L1和L2。为了评估估计性能,需要监测位置、速度和航向上的误差。这些信息与推断的目标车辆行为直接相关,特别是车道保持和变道。这种推断需要一个精确的位置和时间来穿过车道。当车道宽度为3m~3.6m,且平均客车宽度为2m时,横向位置误差应在0.5 m以下,以确定目标车辆是否在车道内。车道过道时间是确定目标车辆变道运动的有用信息,可以利用车辆的速度和航向角来计算。将该算法的估计性能与嵌入在商用激光扫描仪中的盒跟踪算法进行了比较。
有两种类型的实验场景;一种是圆形转弯场景,另一种是在各种弯曲道路上的驾驶场景。循环转弯场景提供了一个显式的外观变化问题。因此,我们可以通过该方法来分析减轻外观变化问题的性能。在不同曲率道路上的行驶场景,用于在更现实的情况下评估估计性能。在这些场景中,目标车辆在道路环境中被驱动做出各种带有外观变化问题的运动。
B.圆形转弯场景
测试圆转弯场景的测试电路是韩国汽车测试与研究院(KATRI)的圆转弯测试轨道。该电路提供多半径的圆车道,以支持如图11所示的转弯测试。通过使用这些车道,目标车辆可以在一个圆形的路径上成功地驾驶。在这个场景中,我们可以明确地评估目标车辆的外观变化对估计性能的影响。

图11:在KATRI的环形转弯测试电路上测试了环形转弯场景。
图12显示了在圆形转弯场景下,每个目标车辆位置点云的不同分布情况。在图12 (a)和(e)的位置,只检测到目标车辆的侧面。从图12 (b)和(h)可以看出,目标车辆仅被保险杠检测到。图12 (c)和图(g)描述了对整个L-Shape目标的检测,这是跟踪算法的最佳情况。图12 (d)和(f)也显示了检测到一个L-Shape,而不是整个目标。在每个位置,点云显示不同的形状,表示传感器和目标车辆之间的相对位置。根据这种外观变化,提取不同的L-Shape特征,L-Shape跟踪算法利用模型切换方案适应这些差异。通过这种场景,可以评估L-Shape跟踪算法如何缓解外观变化效应。
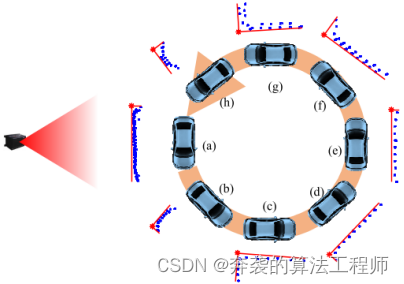
图12:在圆形转弯场景中,目标车辆的外观变化和L-Shape提取。
图13为圆形转弯场景下的模型编号切换和尺寸估计结果。当角点切换时,目标车辆每转一圈,型号从1变化到4。在图13中,红色的垂直虚线表示型号发生变化的时间。此时,L1和L2的长度信息被切换到另一个位置。洋红色和红色的水平虚线分别为目标车辆的长度和宽度。
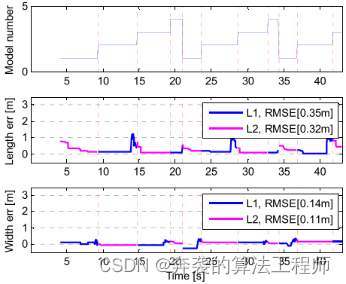
图13:圆形转弯场景下型号和L1、L2长度的估计结果。
图14描述了本文算法和包围盒跟踪算法对位置、速度和航向的估计误差。红色垂直虚线表示模型切换的时间,如图13所示。此时,目标车辆的外观发生了巨大的变化。
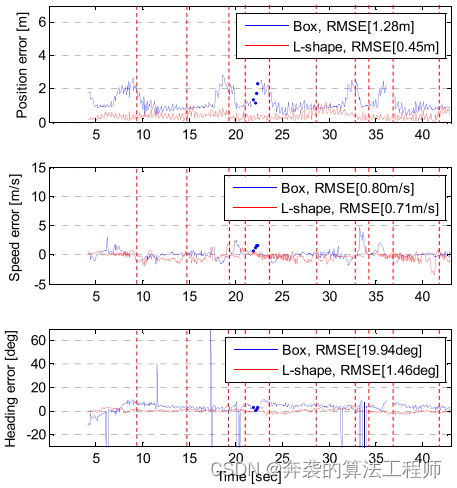
图14:在圆形转弯场景中,L-Shape和包围盒跟踪算法的位置、速度和航向的估计误差。
包围盒跟踪系统中的位置和速度误差受到外观变化的显著影响。当型号从1变为2,3变为4时,位置误差增加。在这些时刻,目标外观的变化反映了目标长度信息的收缩,如图12 (b)和(h)所示。在这些情况下,位置误差增加了2.2 m,并通过恢复长度信息恢复到1m的水平。在其他情况下(模型从2到3和4到1),目标宽度信息被抑制,如图12 (a)和(e)所示,但与之前的情况相比,它造成的误差相对较小。位置误差的每一次显著增加都反映在速度误差上。虽然速度误差的变化很小,但速度误差波动,位置误差较大。包围盒跟踪系统的朝向估计也提供了较大的误差和较高的峰值误差,当整个L-Shape出现小的外观改变就会发生。然而,该算法的估计性能不受外观变化的影响。该算法的误差不随模型切换而改变,如图14所示。
减轻外观变化的性能清楚地反映在位置、速度和航向的RMS误差值中。该算法的均方根误差值为:位置为0.45 m,速度为0.71 m/s,航向为1.46°。对于位置、速度和航向,盒形跟踪算法的RMS误差值分别为1.28 m、0.8 m/s和19.94°。结果表明,该方法将RMS值的位置误差降低了0.83 m(64.8%),速度误差降低了0.09 m/s(12.7%),航向误差降低了18.48°(92.7%)。该算法成功地减少了由于外观变化问题而造成的误差,误差分析清楚地反映了该方法对外观变化的缓解。
C. 在各种曲率道路上的驾驶场景
道路驾驶场景的测试电路是KATRI的转向性能测试轨道。该电路由各种曲率道路组成,模拟各种真实道路,如图15所示。在不同曲率道路上的测试场景由四个场景组成。目标车辆沿不同动态运动路径(红线)行驶,如图15所示。图16描述了各场景下目标车辆的速度和转向。为了模拟车辆真实的动态运动,目标车辆的运动是两种横向行为和两种纵向行为的组合:匀速保持车道、匀速变道、加减速保持车道、加减速变道。

图15:在不同曲率的测试道路上进行实验,以评估L-Shape跟踪算法的性能。
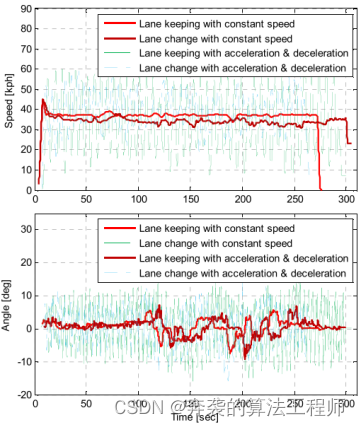
图16:在不同曲率道路上的驾驶场景中,目标车速和转向角度。
1)车道内保持恒定速度:在这种情况下,目标车辆以40公里每小时的速度行驶,并保持在车道内。图17描述了该场景中的模型编号和尺寸估计。型号在1和2之间更改,因为在该场景中只跟踪后保险杠上的两个角点。模型切换不经常发生,因为角点切换很少与车道保持运动一起进行。估计的线长信息与目标的长度和宽度相饱和。
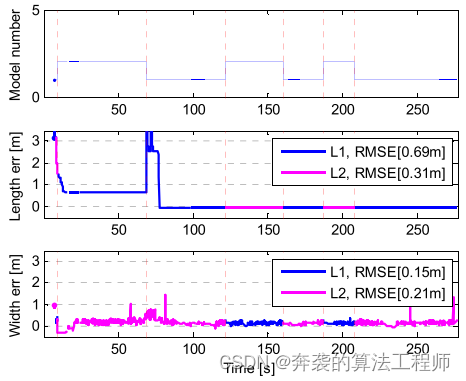
图17:在恒速车道保持情况下,型号和L1、L2长度的估计结果。
图18给出了本文算法与包围盒跟踪算法的估计误差。包围盒跟踪算法的位置误差保持在2 m左右,而本文算法在这种情况下大部分时间估计的位置误差都在1 m以内。由于在此场景下主要检测目标车辆的后保险杠,包围盒跟踪算法由于没有对目标长度进行补偿的能力,误差较大。然而,该算法补偿了长度信息,可以在弯曲道路上检测到。由于目标车辆在匀速运动下是稳定的,因此两种算法的速度误差相似。当模型改变时,包围盒跟踪的航向误差出现峰值误差,但该算法将误差控制在10°以内。包围盒跟踪的RMS位置误差为2.19 m,速度误差为0.24 m/s,航向误差为4.58°。另一方面,该方法的RMS位置误差为0.55 m,速度误差为0.23 m/s,航向误差为2.52°。该方法将位置误差、速度误差和航向误差分别降低了1.65 m(75%)、-0.01 m/s(-4.5%)和2.06°(45%)。位置误差和航向误差大大减小,但速度误差增大。然而,差异只有1厘米/秒,这意味着这种情况下的速度估计性能几乎相同。
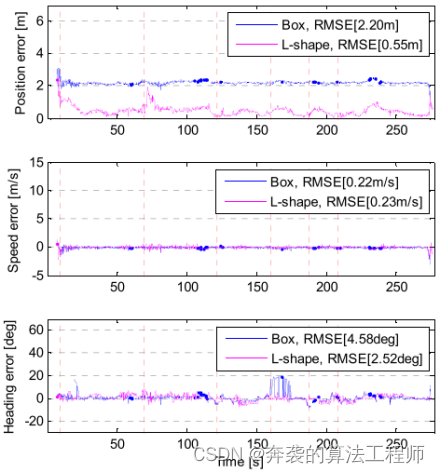
图18:车道内恒速的情况下,L-Shape和包围盒跟踪算法的位置、速度和航向的估计误差。
2)恒速变道:在恒速变道场景中,目标车辆进行恒速(40kph)变道行驶。在这种情况下,L-Shape模型频繁切换,因为变道机动导致目标后保险杠两个角之间的角点频繁变化。
图19为该场景下频繁的模型变化和线长信息切换。线长信息成功估计了目标宽度,但较目标长度短。由于目标侧貌频繁自遮挡,导致目标长度估计较短。尽管模型频繁切换,该算法仍能使目标长度信息接近真实值。
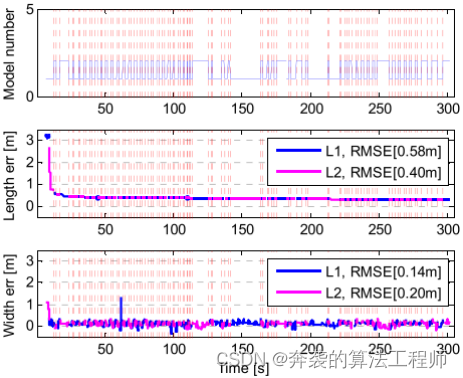
图19:在恒速变道情况下,型号和L1、L2长度的估计结果。
图20给出了两种跟踪系统在恒速变道情况下的估计性能。由于后保险杠频繁自遮挡目标侧外观,包围盒跟踪算法的位置误差振荡,这种误差振荡体现在速度误差上。这些误差是由于外观变化引起的包围盒跟踪方法的意外运动估计误差。由于该场景可以描述真实道路上前车的变道情况,包围盒跟踪算法可能会导致自动驾驶汽车在这种场景下做出错误的决策。由于变道运动,包围盒跟踪方法的航向角误差也会出现较大的波动。相比之下,该算法估计位置、速度和航向的误差要小得多。
包围盒跟踪算法的RMS位置误差为2.02 m,速度误差为0.68 m/s,航向误差为7.65°。该算法将位置误差减小到0.48 m,速度误差减小到0.32 m/s,航向误差减小到3.45°。位置误差减小为1.54 m(76.2%),速度误差减小为0.36 m/s(52.9%),航向误差减小为4.2°(54.9%)。
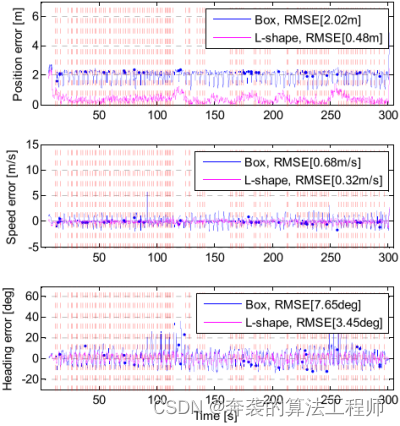
图20:在恒速变道情况下,L-Shape和包围盒跟踪算法的位置、速度和航向的估计误差。
3)加速和减速保持车道:该场景包括目标车辆保持车道的加速和制动动作。图21描述了L1和L2估计下的模型切换。类似于车道保持匀速的场景,型号不会频繁变化,L1, L2也能成功估计出目标的长度和宽度。
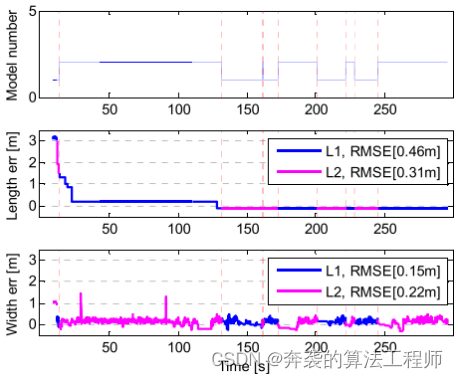
图21:在加速或减速保持车道情况下,型号和L1、L2长度的估计结果。
图22描述了两种算法的估计误差。由于该场景下目标车辆纵向运动变化极大,跟踪算法的位置和速度误差较之前的道路行驶场景增大。随着加速和减速的重复,位置和速度误差波动。但是,与其他场景一样,由于采用了尺寸估计,所提算法的误差波动和位置误差远小于包围盒跟踪方法。
包围盒跟踪算法的位置RMS误差值为2.2 m,速度为1.73 m/s,航向为3.33°。L-Shape跟踪算法对位置、速度和航向的RMS误差分别为0.7m、1.34 m/s和1.99°。位置误差减少了1.5 m(68.1%),速度减少了0.39 m/s(22.5%),航向减少了1.34°(40.2%)。
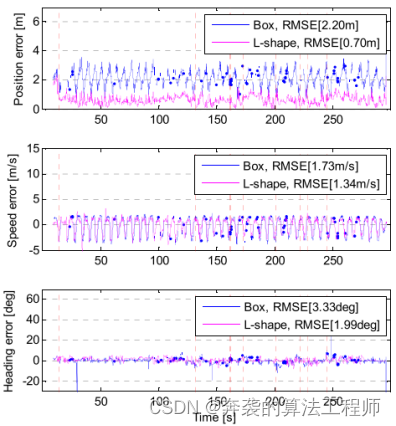
图22:在加速或减速保持车道情况下,L-Shape和包围盒跟踪算法的位置、速度和航向的估计误差。
4)加速减速变道:在这种情况下,目标车辆表现出最复杂的纵向和横向运动。与匀速变道场景一样,由于目标的变道运动,轨迹模型频繁切换。图23为模型数随目标尺寸估计的变化情况。作为另一种变道场景,模型号变化频繁,估计目标尺寸略小。
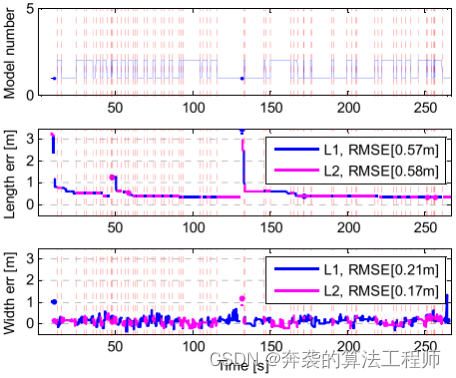
图23:在加速或减速变道情况下,型号和L1、L2长度的估计结果。
两种方法的估计误差如图24所示。在这种情况下,估计误差既反映了变道特征,又反映了前几种情况下极端动态的纵向运动特征。首先,与其他变道场景一样,由于目标侧自遮挡导致的频繁外观变化降低了包围盒跟踪算法的性能。其次,由于速度变化频繁,两种算法都存在波动速度误差。然而,尽管存在这些条件,该方法仍然比包围盒跟踪算法具有更好的估计性能。
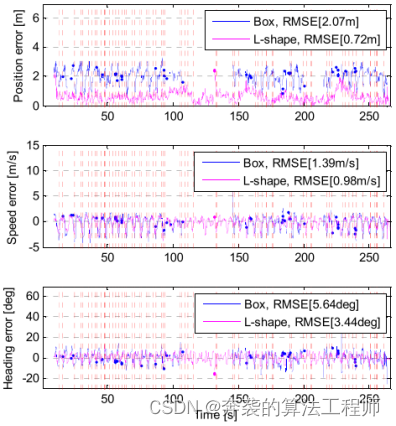
图24:在加速或减速变道情况下,L-Shape和包围盒跟踪算法的位置、速度和航向的估计误差。
该算法对位置、速度和航向的RMS误差分别为2.07 m、1.39 m/s和5.64°。该算法的RMS误差分别为:位置误差0.72 m,速度误差0.98 m/s,航向误差3.44°。结果表明,该算法的位置误差减小了1.35 m(65.2%),速度误差减小了0.41 m/s(29.5%),航向误差减小了2.2°(39%)。
6.结论
提出了一种基于L-Shape模型切换的车辆跟踪算法来克服外观变化问题。该算法独立估计L-Shape特征的角点和形状信息的动态状态。由于角点的位置不随轨迹的大小变化而变化,该算法可以通过外观变化成功消除意外的位置和运动误差。提出的方法在几个实验场景中进行了评估,这些场景提供了明确的外观变化问题和真实的道路情况。实验结果表明,与包围盒跟踪算法相比,该方法可以显著减小位置、速度和航向角的误差,并缓解外观变化问题。特别是,通过将RMS误差减小约60 ~ 70%,位置估计性能得到了显著提高。在RMS误差中,速度误差的减小相对较小,但在变道场景中,由于外观变化引起的意外误差被成功地缓解了。
然而,该算法的性能直接关系到特征提取结果,很像其他基于激光扫描仪的跟踪算法。为了使该方法的性能达到最佳,需要精确的角点位置和航向角提取。不幸的是,l型模型假设车辆的形状是矩形的,但车辆的实际角是平滑弯曲的。因此,在未来的工作中,需要研究一种平滑弯角的精确角点检测算法,以提高所提算法的性能。
这篇关于论文解读--L-Shape Model Switching-Based Precise Motion Tracking of Moving Vehicles Using Laser Scanners的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








