本文主要是介绍论文阅读Consistent Two-Flow Network for Tele-Registration of Point Clouds,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
出自:出自深圳大学计算机科学与软件工程学院
期刊:未知
摘要
局部观测值的刚性配准是各个应用领域的一个基本问题。在计算机图形学中,特别注意由扫描设备产生的两个局部点云之间的配准。当两个点云之间的重叠区域很小时,最先进的配准技术很难实现配准,而当扫描对之间没有重叠时,则完全失败。在本文中,我们提出了一种基于学习的技术来缓解这一问题,点云以任意姿态呈现,很少或甚至没有重叠,这种设置被称为tele-registration。我们的技术是基于一种新的神经网络设计,它学习一类形状的先验,并能够补全部分形状。其关键思想是将配准和补全任务以一种相互强化的方式结合起来。特别地,我们同时使用两个耦合流训练配准网络和补全网络,一个是配准-补全,一个是补全-配准,并鼓励这两个流产生一致的结果。我们发现,与每个单独的流程相比,这种双流程训练可以实现稳健可靠的tele-registration,从而实现更好的点云预测,从而完成配准。值得一提的是,我们的神经网络中的每个组件在补全和配准方面都优于最先进的方法。我们通过几个消融实验进一步分析了我们的网络,并在大量的局部点云(合成的和真实的)上展示了它的性能,这些点云只有很小或没有重叠。代码:https://github.com/Salingo/CTF-Net
方法示意图:
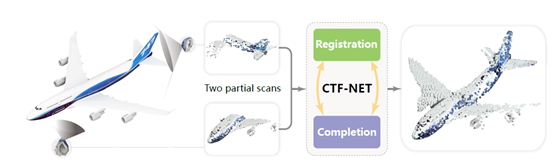
方法流程图:
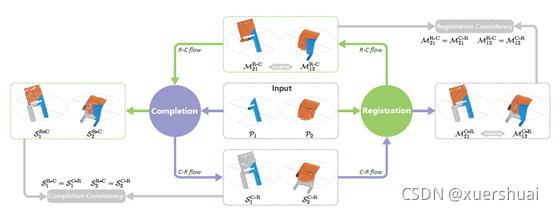
CTF-Net的架构。给出一对局部扫描,CTF-Net同时预测配准变换参数和补全点的坐标。预测遵循一种镜像方式,在一个流中执行配准和补全(R-C),在另一个流中执行补全和配准(C-R)。R-C流和C-R流分别用绿色线和紫色线表示。这两个流程通过提高其输出的一致性而相互加强,用灰色线表示。
将点云配准和点云补全任务结合在一起,使用深度学习方法紧耦合两个任务,视图突破单一方法的极限。
注:个人学习记录,欢迎转载,转载注明出处!
这篇关于论文阅读Consistent Two-Flow Network for Tele-Registration of Point Clouds的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








