本文主要是介绍Course1-week2-foundation of neural network,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Week 2
Basics of Neural Network Programming
2.1 binary classification
m m training example:
X.shape = (n_x, m), Y.shape = (1, m)
2.2 logistic regression
This is a learning algorithm you use when the output label y in a supervised learning problem are all either 0 or 1, so for binary classification problem.
Given an input feature vector x x maybe corresponding to the image that you want to recognize either a cat picture or not a cat picture, you want the algorithm that can output a prediction, which we’ll call , which is your estimate of y y , you want the to be the probability of the chance P(y=1|x) P ( y = 1 | x ) , you want y^ y ^ to tell you, what is the chance than this is a cat picture. you want y^ y ^ to be the chance the y equal to 1
When you implement your logistic regression, your job is try to learn the paramenter W W and so that y^ y ^ becomes a good estimator of the chance of y y equal to . In order to train the W W and , you need to defined a cost function.
2.3 logistic regression cost funciton
Let’s see what loss function or error function we can use to measure how well our algorithm is doing.
One thing we can do is following:
It turn out that you could do this, but in logistic regression peoplt don’t usually do this, because whem you come to learn your parameters, you find that the optimization problem becomes non-convex, which will be a problem with muliple local optima. So gradient desecnt may not find the global optimum.
So what we use in the logistic regression is actually the following function.
Here’s some intuition for why this loss function make sence
We want L L to be as small as possible. To understand why this make sence, let’s look at the two cases.
- if want
logy^ l o g y ^ large, because the
y^ y ^ can never be bigger than 1, so you want
y^ y ^ to be close to 1
- if y=0⟶L(y^,y)=−log(1−y^) ⟶ y = 0 ⟶ L ( y ^ , y ) = − l o g ( 1 − y ^ ) ⟶ want 1−y^ 1 − y ^ large so that want y^ y ^ small, because y^ y ^ can never smaller than 0, so you want y^ y ^ to be close to 0, This is saying that if y=0 y = 0 , your loss function will push the parameters to make the y^ y ^ as close to zero as possible
Cost funtion:
J(W,b)=1m∑j=1mL(y(j),y^(j))(1) (1) J ( W , b ) = 1 m ∑ j = 1 m L ( y ( j ) , y ^ ( j ) )It turns out that logistic regression can be viewed as a very very small neural network, Let’s go on the next to see how we view the logistic regression as a very small neural network.
2.4 gradient descent
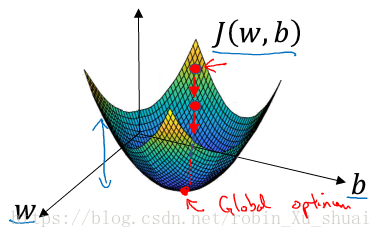
Now let’s talk about how you can use the gradient descent algorithem to train or learn the W W and on your training set. The cost function measures how well your parameters W W and are doing on the training set. What we want to do is really to find the value of W W and that corresponds to the minmum of the cost function J(W,b) J ( W , b ) . It turn out that the cost function J is a convex function, so just a single big bowl. (fig.1)So the fact that our cost function J(W,b) J ( W , b ) as defined here is convex is one of the huge reason why this particular cost functionn for logsitic regression. For logistic regression almost any initialization method works.
repeat{}w:=w−αdJ(w)dw r e p e a t { w := w − α d J ( w ) d w }
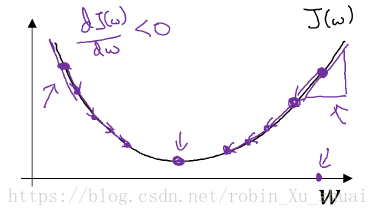
I will repeatedly do that until the algorithm converges. Now let’s just make sure that this gradient descent update make sense. (fig.2)If we have started off with the large value of w w , now the derivate is positive, and get updates as w w minus a learning rate times the poistive derivative, so you end up taking a step to the left. If we have started off the small value of , now at the point the slope will be negative, and so the gradient descent updates would subtract α α times a negative number, and so end up slowly increaseing w w , so you end up making bigger and bigger. So that whether you initilize on the left or on the right, gradient descent updates will nove you towards the global minmum point.
2.5 derivatives
For a straight line which function is f(a)=3a f ( a ) = 3 a , the slope of this function f(a) f ( a ) denote as df(a)da d f ( a ) d a , which equals to 3, this equation means that if we nudge a a to the right a little bit, go up by 3 times as much as I nudge just the value of little a a .
2.6 more derivatives example
The derivative of the function just means the slope of the function, and the slope of function can be diffient at diffient point on the function. In our first example where , this is a straight line the derivative was the same everywhere, it’s 3 everywhere. But for the function f(a)=a2 f ( a ) = a 2 , the slope of the line vary, so the slope or the derivative can be diffierent at diffierent point on the curve.
2.7 computation graph
2.8 derivatives with a computation graph
2.9 logistic regression gradient descent (just one training example)
We will talk about how to compute derivatives for you to implement gradient descent for logistic regression.
focus on just one example:
z=wTx+b z = w T x + b
y^=a=σ(z) y ^ = a = σ ( z )
L(y^,y)=−(yloga+(1−y)log(1−a)) L ( y ^ , y ) = − ( y l o g a + ( 1 − y ) l o g ( 1 − a ) )In logistic regression what we want to do is to modify the paramenters w w and in order to reduce the loss. We know how to compute the loss on a single training example. Now let’s talk about how you can go backward to compute the derivatives.
da=dL(a,y)da=−dda(yloga+(1−y)log(1−a))=−ya+1−y1−a d a = d L ( a , y ) d a = − d d a ( y l o g a + ( 1 − y ) l o g ( 1 − a ) ) = − y a + 1 − y 1 − a
dz=dL(a,y)dz=dL(a,y)dadadz=(−ya+1−y1−a)(a(1−a))=−y(1−a)+a(1−y)a(1−a)a(1−a)=a−y d z = d L ( a , y ) d z = d L ( a , y ) d a d a d z = ( − y a + 1 − y 1 − a ) ( a ( 1 − a ) ) = − y ( 1 − a ) + a ( 1 − y ) a ( 1 − a ) a ( 1 − a ) = a − y
where:a=σ(z)=11+e−z a = σ ( z ) = 1 1 + e − z
dadz=e−z(1+e−z)2=−1+1+e−z(1+e−z)2=(−1(1+e−z)2+11+e−z)=a−a2=a(1−a) d a d z = e − z ( 1 + e − z ) 2 = − 1 + 1 + e − z ( 1 + e − z ) 2 = ( − 1 ( 1 + e − z ) 2 + 1 1 + e − z ) = a − a 2 = a ( 1 − a )
dw1=dLdw1=dLdzdzdw1=x1dz d w 1 = d L d w 1 = d L d z d z d w 1 = x 1 d z
dw2=dLdw2=dLdzdzdw2w=x2dz d w 2 = d L d w 2 = d L d z d z d w 2 w = x 2 d z
db=dLdb=dLdzdzdb=dz d b = d L d b = d L d z d z d b = d zso if you want to do gradient descent with respect to just one example. what you will do is following:
w1:=w1−αdw1 w 1 := w 1 − α d w 1
w2:=w2−αdw1 w 2 := w 2 − α d w 1
b:=b−αdb b := b − α d b
so this is one step with respect to single example, but to train logstic regression model you have not just one example.2.10 gradient descent on m examples
In the previous we saw how to compute derivatives and implements gradient descent with respect to just one training example for logistic regression, now we want to do it for m m examples.
a(i)=σ(z(i))=σ(wTx(i)+b) a ( i ) = σ ( z ( i ) ) = σ ( w T x ( i ) + b )When just have one training example (x(i),y(i)) ( x ( i ) , y ( i ) ) , we saw how to compute the derivatives dw(i)1,dw(i)2 d w 1 ( i ) , d w 2 ( i ) and db(i) d b ( i ) .
The overall cost function was really the average of the individual losses, so the derivatives respect to w1 w 1 of the cost function is also going to be the average of the derivatives respect to w1 w 1 of the individual losses.
∂∂w1J(W,b)=1m∑i=1m∂∂w1L(a(i),y(i)) ∂ ∂ w 1 J ( W , b ) = 1 m ∑ i = 1 m ∂ ∂ w 1 L ( a ( i ) , y ( i ) )one single step or one single iteration of the gradient descent for logistic regression
J = 0; dw_1 = 0, dw_2 = 0, db = 0 for i in m:z^(i) = W^T x^(i) + ba^(i) = sigmoid(z^(i))J += -(y^(i) log(a^(i)) + (1-y^(i))log(1-a^(i)))dz^(i) = a^(i) - y^(i)dw_1 += x^(i)_(1) dz^(i)...dw_n += x^(i)_(m) dz^(i)db += dz^(i) J /= m dw_1 /= m dw_2 /= m db /= mw_1 = w_1 - alpha * dw_1 w_2 = w_2 - alpha * dw_2 ... b = b - alpha * db
Next let’s talk about vectorization, so that you can implement a single iteration of gradient descent without use any for loop.
2.11 vectorization
import numpy as np import time a = np.random.rand(1000000) b = np.random.rand(1000000)tic = time.time() c = np.dot(a, b) toc = time.time() print(c) print('Vectorized version ' + str(1000*(toc - tic)) + 'ms')c = 0 tic = time.time() for i in range(1000000):c += a[i]*b[i] toc = time.time() print(c) print('for loop', str(1000*(toc - tic)), 'ms')249962.033774 Vectorized version 2.5033950805664062ms 249962.033774 for loop 674.983024597168 ms2.12 more vectorization examples
2.13 vectorizing logistic regression
We have talked about how vectorization let’s you speed up your code significantly. Now we will talk about how we can vectorize the implementation of logistic regression, so you can process the entire training set, that is implement a single iteration of gradient descent with respect to an entire training set without useing even a single explicit for loop.
z(1)=WTx(1)+b z ( 1 ) = W T x ( 1 ) + b
a(1)=σ(z(1)) a ( 1 ) = σ ( z ( 1 ) )
⋮ ⋮
z(m)=WTx(m)+b z ( m ) = W T x ( m ) + b
a(m)=σ(z(m)) a ( m ) = σ ( z ( m ) )remember than we defined a matrix capital X X to be training input, stacked together in different columns.
Next we will show how we can compute z(1),z(2),⋯,z(m) z ( 1 ) , z ( 2 ) , ⋯ , z ( m ) all in one step, with one line code.
Z=[z(1),z(2),⋯,z(m)]=[w1,w2,⋯,wm]⎡⎣⎢⎢⎢⋮x(1)⋮⋮x(2)⋮⋯⋯⋯⋮x(m)⋮⎤⎦⎥⎥⎥+b=[wTx(1)+b,wTx(2)+b,⋯,wTx(m)+b]=wTx Z = [ z ( 1 ) , z ( 2 ) , ⋯ , z ( m ) ] = [ w 1 , w 2 , ⋯ , w m ] [ ⋮ ⋮ ⋯ ⋮ x ( 1 ) x ( 2 ) ⋯ x ( m ) ⋮ ⋮ ⋯ ⋮ ] + b = [ w T x ( 1 ) + b , w T x ( 2 ) + b , ⋯ , w T x ( m ) + b ] = w T xZ = np.dot(w.T, X) + b A = sigmoid(Z)2.14 vectorizing logistic regression’s gradient compute
You saw how use vectorization to compute their predictions for an entire training set all at the same time. Now you will to see how to use vectorization to also perform the gradient computations for all m training samples, again, all those at the same time.
dz(1)=a(1)−y(1)dz(2)=a(2)−y(2)⋯dz(m)=a(m)−y(m)⎫⎭⎬⎪⎪⎪⎪⎪⎪⎪⎪⟶dZ=[dz(1),dz(2),⋯,dz(m)]=A−Y(8) (8) d z ( 1 ) = a ( 1 ) − y ( 1 ) d z ( 2 ) = a ( 2 ) − y ( 2 ) ⋯ d z ( m ) = a ( m ) − y ( m ) } ⟶ d Z = [ d z ( 1 ) , d z ( 2 ) , ⋯ , d z ( m ) ] = A − Y
<script type="math/tex; mode=display" id="MathJax-Element-314"></script>
db=0db+=dz(1)db+=dz(2)⋯db+=dz(m)⎫⎭⎬⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⟶db=1m∑i=1mdz(i)=1mnp.sum(dZ)(2) (2) d b = 0 d b + = d z ( 1 ) d b + = d z ( 2 ) ⋯ d b + = d z ( m ) } ⟶ d b = 1 m ∑ i = 1 m d z ( i ) = 1 m n p . s u m ( d Z )dw=0dw+=x(1)dz(1)dw+=x(2)dz(2)⋯dw+=x(m)dz(m)⎫⎭⎬⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⟶dw=1mXdzT=1m[x(1),x(2),⋯,x(m)]⎡⎣⎢⎢dz(1)⋮dz(m)⎤⎦⎥⎥(3) (3) d w = 0 d w + = x ( 1 ) d z ( 1 ) d w + = x ( 2 ) d z ( 2 ) ⋯ d w + = x ( m ) d z ( m ) } ⟶ d w = 1 m X d z T = 1 m [ x ( 1 ) , x ( 2 ) , ⋯ , x ( m ) ] [ d z ( 1 ) ⋮ d z ( m ) ]implement a iteration of gradient descent for logistic regression without useing a single FOR loop.
Z=wTX+b (Z.shape()=(1,m))A=σ(Z)dZ=A−Ydw=1mXdZTdb=1mnp.sum(dZ)w=w−αdwb=b−αdb Z = w T X + b ( Z . s h a p e ( ) = ( 1 , m ) ) A = σ ( Z ) d Z = A − Y d w = 1 m X d Z T d b = 1 m n p . s u m ( d Z ) w = w − α d w b = b − α d b2.15 boradcasting in python
A = np.array([[56.0, 0.0, 4.4, 68.],[1.2, 104.0, 52.0, 8.0],[1.8, 135.0, 99.0, 0.9]]) print(A)[[ 56. 0. 4.4 68. ][ 1.2 104. 52. 8. ][ 1.8 135. 99. 0.9]]cal = A.sum(axis = 0) # you want to python to sum vertically print(cal)[ 59. 239. 155.4 76.9]percentage = A/cal print(percentage)[[ 0.94915254 0. 0.02831403 0.88426528][ 0.02033898 0.43514644 0.33462033 0.10403121][ 0.03050847 0.56485356 0.63706564 0.01170351]]2.16 a note on python or numpy vectors
a = np.random.rand(10) print(a)[ 0.22354426 0.90835372 0.70797423 0.37848066 0.76930812 0.211096450.80027059 0.54396317 0.39067918 0.44721829]a.shape(10,)This is called rank 1 array in python, and it’s neither a row vector nor a colume vector.
print(a.T)[ 0.22354426 0.90835372 0.70797423 0.37848066 0.76930812 0.211096450.80027059 0.54396317 0.39067918 0.44721829]print(np.dot(a, a.T))3.44491371769a = np.random.randn(5, 1) print(a)[[-1.43316675][ 0.41149367][ 1.29073252][ 0.75121868][-0.70654665]]print(a.shape)(5, 1)print(a.T)[[-1.43316675 0.41149367 1.29073252 0.75121868 -0.70654665]]print(np.dot(a, a.T))[[ 2.05396694 -0.58973904 -1.84983493 -1.07662164 1.01259917][-0.58973904 0.16932704 0.53112826 0.30912173 -0.29073947][-1.84983493 0.53112826 1.66599043 0.96962238 -0.91196273][-1.07662164 0.30912173 0.96962238 0.5643295 -0.53077104][ 1.01259917 -0.29073947 -0.91196273 -0.53077104 0.49920817]]So what I’am going to recommend is that when you doing your programming exercise, you just do not use these rank 1 array, instead, if every time you create an array, you commit to making it either a column vector or a row vector, these behavior of vector may be easier to understand.
If you not very sure what’s the dimension of one vector, you can often throw an assertion statement:
assert(a.shape == (5, 1))2.17 explanation of logistic regression cost function
Why we use the cost function for logistic regression.
y^=σ(wTx+b) y ^ = σ ( w T x + b )we said that we want to interpert y^ y ^ as the chance that y=1 y = 1 for given the set of input features x x .
so another way to say this is that:
or we can say:
if y=1:p(y|x)=y^if y=0:p(y|x)=1−y^ i f y = 1 : p ( y | x ) = y ^ i f y = 0 : p ( y | x ) = 1 − y ^next what I’m going to do is take these two equations, which basically define p(y|x) p ( y | x ) for two cases of y=0 y = 0 or y=1 y = 1 , and summarize them into a single equation.
p(y|x)=y^y(1−y^)(1−y) p ( y | x ) = y ^ y ( 1 − y ^ ) ( 1 − y )
It’s turn out that this one line summarize the two equations top.- suppose y=1,p(y|x)=y^⋅(1−y^)0=y^ y = 1 , p ( y | x ) = y ^ ⋅ ( 1 − y ^ ) 0 = y ^
- suppose y=0,p(y|x)=y^0⋅(1−y^)1−0=1−y^ y = 0 , p ( y | x ) = y ^ 0 ⋅ ( 1 − y ^ ) 1 − 0 = 1 − y ^
because the log function is a strictly monotomically increaseing function, you’re maximizing log(p|x) l o g ( p | x ) give you similiar result that is optimizing p(y|x) p ( y | x ) .
logp(y|x)=log(y^y(1−y^)(1−y))=ylogy^+(1−y)log(1−y^)=−L(y^,y) l o g p ( y | x ) = l o g ( y ^ y ( 1 − y ^ ) ( 1 − y ) ) = y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) = − L ( y ^ , y )we can carry out maximum likelihood estimation, so we want to find the parameters to maximizes the chance of you observation in the training set.
log∏i=1mp(y(i)|x(i))=∑i=1mlogp(y(i)|x(i))=−∑i=1mL(y(i),yi) l o g ∏ i = 1 m p ( y ( i ) | x ( i ) ) = ∑ i = 1 m l o g p ( y ( i ) | x ( i ) ) = − ∑ i = 1 m L ( y ( i ) , y i )
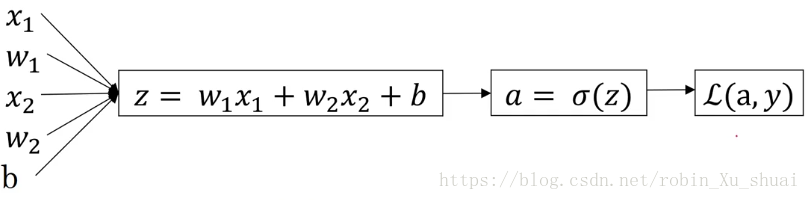




这篇关于Course1-week2-foundation of neural network的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[论文笔记]Making Large Language Models A Better Foundation For Dense Retrieval](https://img-blog.csdnimg.cn/img_convert/6dbbf911e7e57daa6ac5366f311e3e68.png)