Supervised Contrastive Pre-training for Mammographic Triage Screening Model
2023-10-10 21:36
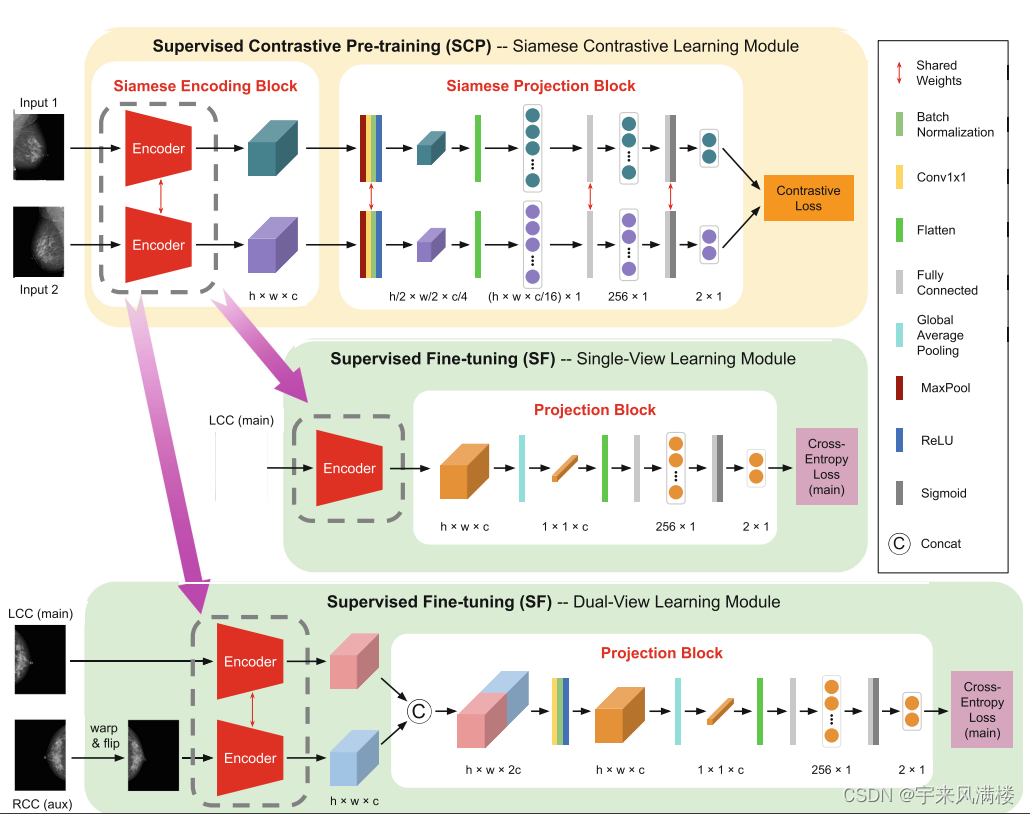
http://www.chinasem.cn/article/183237。
23002807@qq.com
相关文章

Pydantic中model_validator的实现
《Pydantic中model_validator的实现》本文主要介绍了Pydantic中model_validator的实现,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价... 目录引言基础知识创建 Pydantic 模型使用 model_validator 装饰器高级用法mo
GORM中Model和Table的区别及使用
《GORM中Model和Table的区别及使用》Model和Table是两种与数据库表交互的核心方法,但它们的用途和行为存在著差异,本文主要介绍了GORM中Model和Table的区别及使用,具有一... 目录1. Model 的作用与特点1.1 核心用途1.2 行为特点1.3 示例China编程代码2. Tab

2014 Multi-University Training Contest 8小记
1002 计算几何 最大的速度才可能拥有无限的面积。 最大的速度的点 求凸包, 凸包上的点( 注意不是端点 ) 才拥有无限的面积 注意 : 凸包上如果有重点则不满足。 另外最大的速度为0也不行的。 int cmp(double x){if(fabs(x) < 1e-8) return 0 ;if(x > 0) return 1 ;return -1 ;}struct poin
2014 Multi-University Training Contest 7小记
1003 数学 , 先暴力再解方程。 在b进制下是个2 , 3 位数的 大概是10000进制以上 。这部分解方程 2-10000 直接暴力 typedef long long LL ;LL n ;int ok(int b){LL m = n ;int c ;while(m){c = m % b ;if(c == 3 || c == 4 || c == 5 ||
2014 Multi-University Training Contest 6小记
1003 贪心 对于111...10....000 这样的序列, a 为1的个数,b为0的个数,易得当 x= a / (a + b) 时 f最小。 讲串分成若干段 1..10..0 , 1..10..0 , 要满足x非递减 。 对于 xi > xi+1 这样的合并 即可。 const int maxn = 100008 ;struct Node{int
MVC(Model-View-Controller)和MVVM(Model-View-ViewModel)
1、MVC MVC(Model-View-Controller) 是一种常用的架构模式,用于分离应用程序的逻辑、数据和展示。它通过三个核心组件(模型、视图和控制器)将应用程序的业务逻辑与用户界面隔离,促进代码的可维护性、可扩展性和模块化。在 MVC 模式中,各组件可以与多种设计模式结合使用,以增强灵活性和可维护性。以下是 MVC 各组件与常见设计模式的关系和作用: 1. Model(模型)

论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes
论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes 优势 1、构建了一个用于监督原始视频去噪的基准数据集。为了多次捕捉瞬间,我们手动为对象s创建运动。在高ISO模式下捕获每一时刻的噪声帧,并通过对多个噪声帧进行平均得到相应的干净帧。 2、有效的原始视频去噪网络(RViDeNet),通过探

Post-Training有多重要?一文带你了解全部细节
1. 简介 随着LLM学界和工业界日新月异的发展,不仅预训练所用的算力和数据正在疯狂内卷,后训练(post-training)的对齐和微调方法也在不断更新。InstructGPT、WebGPT等较早发布的模型使用标准RLHF方法,其中的数据管理风格和规模似乎已经过时。近来,Meta、谷歌和英伟达等AI巨头纷纷发布开源模型,附带发布详尽的论文或报告,包括Llama 3.1、Nemotron 340

diffusion model 合集
diffusion model 整理 DDPM: 前向一步到位,从数据集里的图片加噪声,根据随机到的 t t t 决定混合的比例,反向要慢慢迭代,DDPM是用了1000步迭代。模型的输入是带噪声图和 t,t 先生成embedding后,用通道和的方式加到每一层中间去: 训练过程是对每个样本分配一个随机的t,采样一个高斯噪声 ϵ \epsilon ϵ,然后根据 t 对图片和噪声进行混合,将加噪

COD论文笔记 ECCV2024 Just a Hint: Point-Supervised Camouflaged Object Detection
这篇论文的主要动机、现有方法的不足、拟解决的问题、主要贡献和创新点: 1. 动机 伪装物体检测(Camouflaged Object Detection, COD)旨在检测隐藏在环境中的伪装物体,这是一个具有挑战性的任务。由于伪装物体与背景的细微差别和模糊的边界,手动标注像素级的物体非常耗时,例如每张图片可能需要 60 分钟来标注。因此,作者希望通过减少标注负担,提出了一种仅依赖“点标注”的弱