本文主要是介绍【数字人】2、MODA | 基于人脸关键点的语音驱动单张图数字人生成(ICCV2023),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 一、背景
- 二、方法
- 2.1 问题描述和数据预处理
- 2.2 Mapping-Once network with Dual Attentions
- 2.3 Facial Composer Network
- 2.4 使用 TPE 来合成人像图片
- 三、效果
- 3.1 训练细节
- 3.2 数据
- 3.3 测评指标
- 3.4 结果比较
- 四、代码
- 4.1 数据前处理
- 4.2 训练
- 4.3 推理
论文:MODA: Mapping-Once Audio-driven Portrait Animation with Dual Attentions
代码:https://tinyurl.com/iccv23-moda
出处:ICCV2023
贡献:
- 提出了一个 unifided MODA 网络,能够经过一次映射来同时获得确定的唇部动作和不确定的其他面部动作
- 是一种基于密集关键点的方法,能够同时驱动嘴、眼、头、肩的运动,更自然
和典型方法的对比:
- Wav2Lip(MM2020) :下半张脸被模糊了(Wav2Lip-GFPGAN 使用两个模型提升输出结果的分辨率)
- PC-AVS(CVPR2021) :基本都是正脸的图,头部变化不够多样
- MakeItTalk(SIGGRAPH 2020):由于使用的 2D warping 所以脸部会扭曲。
- Audio2Head(IJCAI2021):只会产生正脸的图,且由于使用的 2D warping 所以脸部会扭曲
- SadTalker(CVPR2023):唇部同步性较好,唇部较清晰,头部运动较丰富,牙齿不够清晰,没有考虑除唇部动作和眨眼外的其他面部表情,表情比较固定
- MODA(ICCV2023):使用一个模型(双分支)来学习确定性的【唇部】、不确定性的【眼部+面部+head+身体】的关键点,理论上能让动作看起来更自然,能保留更多的面部细节。
一、背景
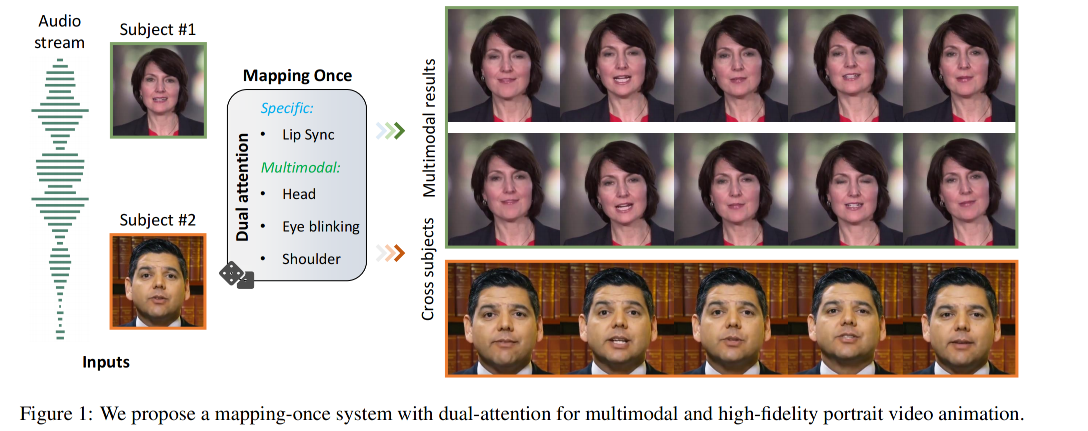
talking head 是通过一个给定的语音信号来驱动图片,从而合成一个和语音同频的说话的视频
之前的方法 [7,29,52] 都是学习语音和图片帧之间的关系,且一般会忽略 head pose(因为他们认为 head pose 难以和面部动作分开)。
很多 3D 面部重建的方法和基于 GAN 的方法一般会估计一个中间表达(3D face shape、2D landmark、face expression parameters 等)来帮助生成
但是,这些稀疏的表达会丢失很多面部细节,导致过平滑(over-smooth)
NeRF[10,44] 以其高保真结果也受到了很多关注,但是其难以控制
虽然前面提到了这么多方法,但是生成一个真实且表情丰富的 talking vedio 仍然很难,因为人们对合成的 vedio 很敏感,所以要达到可用的效果要达到很高的标准
主要要考虑的问题如下:
- 正确性:合成的 vedio 要和驱动的 audio 高度一致
- 高视觉质量:合成的 vedio 要有高分辨率且包含很多细节信息
- 多样性:说话时主要是嘴唇需要很好的和声音同步,而眨眼和头部动作时不确定的,但也需要和正常人说话的动作类似
为了实现上面三个目标,之前的方法有的将 mouth landmark 和 head pose 分开学习,使用不同的 sub-network [22,50],还有的方法只对 mouth 运动建模,head pose 是从其他 vedio 中拿来的[29,52]。但是这样 lip-sync 和其他运动会缺少关联,导致不确定的结果。
本文中,作者提出了 MODA,mapping-once network with dual attentions,是一个统一的结构来生成不同的表达,简化了步骤。
- 为了将唇部动作和其他动作结合起来,作者设计了一个 dual-attention module 来分别学习确定性的映射(确定的 mouth movement)和概率采样(the diverse head pose/eye blinking from time-totime)。
- transformer-based dual attention module:生成准确且多样性的表示特征
- facial composer network:得到更准确和细节的面部 landmark
- tenporally guided renderer:合成 vedio
二、方法
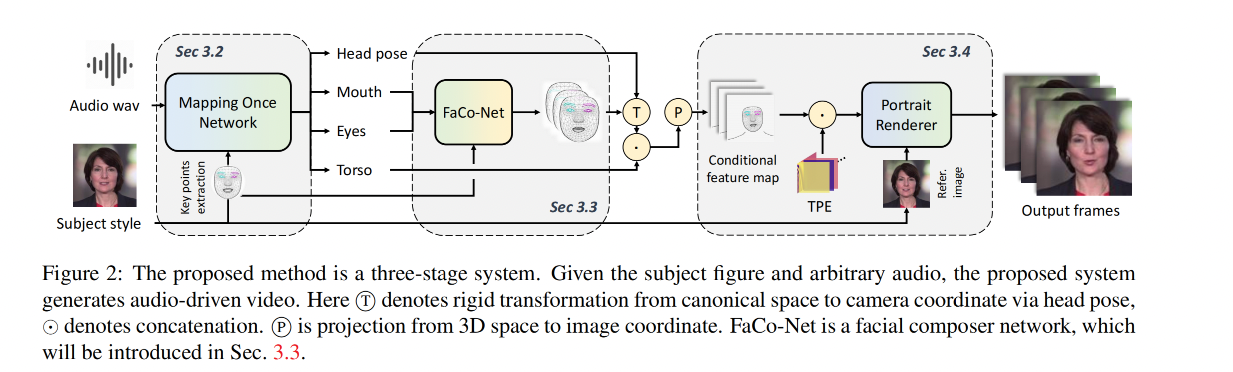
整体框架如图 2 所示,本文方法主要是为了生成高保真 talking head,且具有确定的 lip motion 和其他的 multi-modal motion(head pose、eye blinking、torso movements)
共包含 3 个部分:
- 首先,给定 driven audio 和 conditioned subjects,MODA 会生成多模态和正确的语义人像部件
- 然后,面部合成网络会将 ficial component 结合起来,并添加一些细节面部细节
- 最后,使用具有时间位置嵌入(temporally positional embedding, TPE)的人像渲染器来合成高保真且稳定的视频
2.1 问题描述和数据预处理
给定一个长度为 t 的音频序列 A = { a 0 , a 1 , . . . , a T } A=\{a_0, a_1,...,a_T\} A={a0,a1,...,aT},其音频采样率为 r
本文的 talking portrait (说话人像)方法主要的面部是将这个音频映射到对应的视频 video clip 中, V = { I 0 , I 1 , . . . , I K } V=\{I_0,I_1,...,I_K\} V={I0,I1,...,IK},且 FPS 为 f, K = ⌊ f T / r ⌋ K=\lfloor{fT/r}\rfloor K=⌊fT/r⌋
由于 V 远远大于 A,很多方法提出逐步生成 V,并且引入很多中间表达 R,为了让 V 看起来更自然,那么多 R 的约束就自然很重要了
在之前的 audio-driven face 生成任务中,R 一般都是一种 face information(如 facial landmark、head pose)
为了更好的表达说话人像,本文作者定义 R 是多种不同的人像描述, R = P M , P E , P F , H , P T R=P^M, P_E, P^F, H, P^T R=PM,PE,PF,H,PT:
- 嘴部关键点 P M P^M PM:40 个
- 眼部关键点 P E P^E PE:60 个,包括眼睛和眉毛的关键点,控制眨眼
- 面部关键点 P F P^F PF:478 个,是密集的面部 3D 关键点,用于控制面部表情细节
- 头部动作 H H H:6 个,head rotation ( θ , ϕ , ψ ) (\theta, \phi, \psi) (θ,ϕ,ψ),head transpose ( x , y , z ) (x,y,z) (x,y,z)
- 躯体动作 Torso points P T P^T PT:18 个,每个肩膀 9 个
所以,整个 talking portrait 可以被写为 A→R→V,作者也是分别设计了对应的网络来实现对应的过程
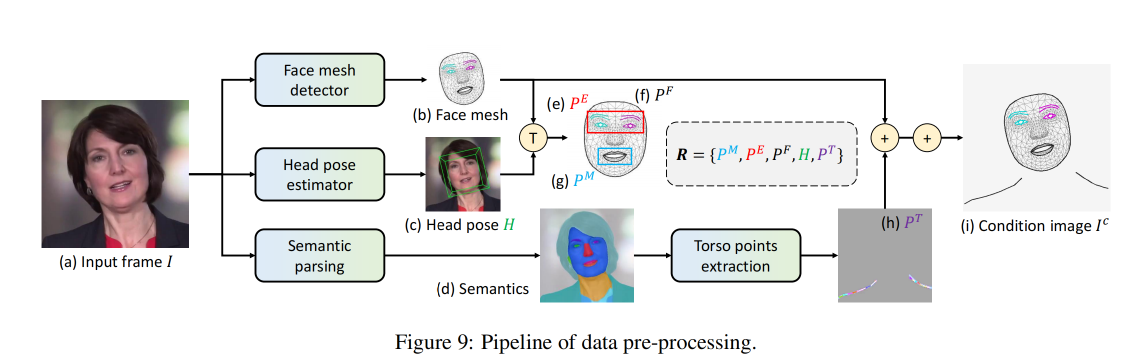
数据预处理:关键点提取
- 使用 Mediapipe 抽取 478 个 3D facial keypoints
- 使用 WHENet 估计 head pose
- 使用 BiseNet 分割,然后抽取出肩部关键点
2.2 Mapping-Once network with Dual Attentions
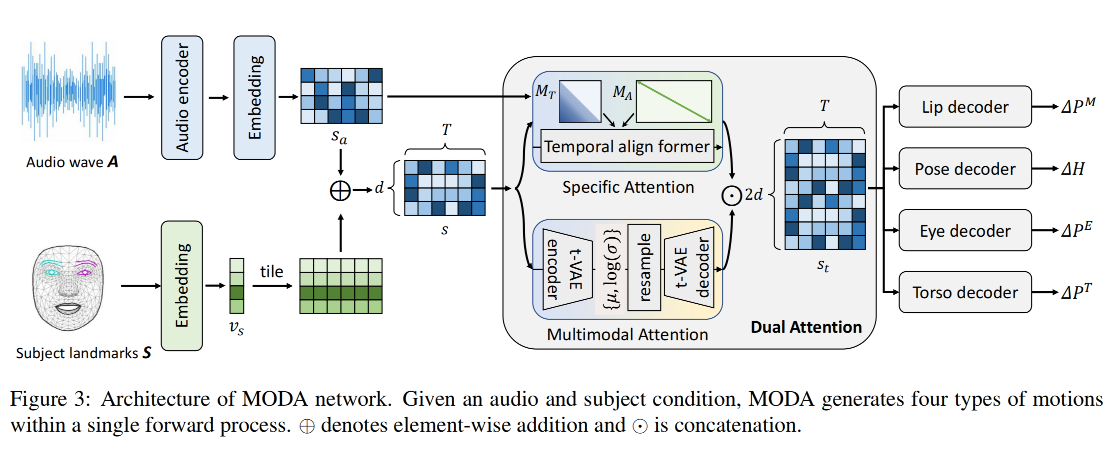
Mapping-once 结构:如图 3 所示
- 给定 driven audio A 和 subject condition S,MODA 的作用是使用一次前向过程来将其投影到 R 中(lip movement, eye blinking, head pose, and torso)
- 第一步:分别使用两个 encoder 来编码 audio feature 和抽取 subject style
- 第二步:使用一个 dual-attention module 来生成多样且确定的 motion feature
- 第三步:分别使用 4 个 decoder 来得到对应的关键点
audio 特征处理:
-
audio feature 抽取:首先使用 Wav2Vec[30] 来抽取语音上下文信息,然后使用 MLP 映射到 s a ∈ R d × T s_a \in R^{d \times T} sa∈Rd×T,d 是一帧数据的特征维度,T 是待生成的 vedio 的 frame 的个数
-
为了建模不同说话风格,作者使用 conditioned subject 的 facial vertices 作为输入,然后将这些 vertices 映射到 d 维向量 v s v_s vs 中作为 subject style code,这里的映射也是使用 MLP 来实现的,然后对 s a s_a sa 和 v s v_s vs 进行结合,得到结合后的特征 s s s
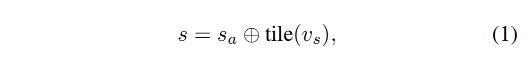
-
dual-attention module 的输入是 s s s 和 s a s_a sa,输出是时序上下文 s t s_t st
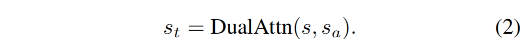
-
然后,使用 4 个 MLP 来解码不同的关键点

Dual-attention module:
- specific attention branch:SpecAttn
- probabilistic attention branch:ProbAttn
由于 talking portrait 生成任务需要从有限的驱动信息中生成多模态的输出,所以该任务具有很大的不确定性
本文方法提出的 dual-attention 模型,将这个任务解耦成了下面两个任务:
- specific mapping :得到时序对齐的确定的 audio 和 lip movement 特征
- probabilistic mapping:得到时序关联的概率 audio 和 other movements 特征
- 作者使用两个子模块来分别学习不同的特征,然后使用 time-wise concatenation 来聚合这两种特征
dual-attention 的两个分支:
- SpecAttn 分支
- ProbAttn 分支
1、SpecAttn 分支:specific attention branch,用于捕捉 s s s 和 audio feature s a s_a sa 的实时对齐的 attention s s a s_{sa} ssa,根据 FaceFormer,本文的 SpecAttn 格式如下:
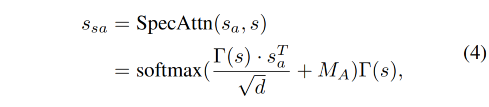
-
d d d 是 s a s_a sa 的维度
-
alignment bias M A M_A MA 如下:
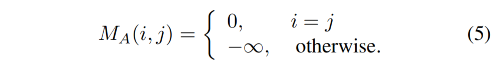
不同于 FaceFormer 中只在自回归中使用了 cross-attention,本文在整个序列中都使用了 cross-attention,计算速度提升了 Tx
为了捕捉更丰富的时序信息,作者还在 s s s 上使用了 periodic positional encoding (PPE) 和 biased casual self-attention:
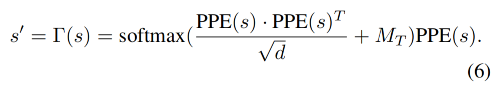
M T M_T MT 是一个上三角区为负无穷的矩阵,这是为了避免看到未来的帧来进行当前帧的预测
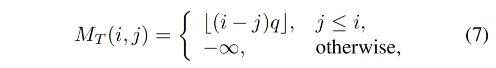
- q q q 是控制序列周期的超参数
- 这样做能够让 encoded feature s’ 包含更丰富的 空间-时序 信息,能够生成的更准确
2、ProbAttn 分支
为了生成更逼真的结果且避免过平滑,学习声音特征和人像动作之间的概率映射很重要,VAE[17] 能够建模概率生成并且在时序的生成任务上表现的比较好
所以,基于 advanced transformer Variational Autoencoder (t-VAE),本文设计了 probabilistic attention branch 来生成更多样的结果
给定特征表达 s s s,probabilistic attention 的目标是生成更多样的特征 s p a s_{pa} spa:
- 首先,将 s s s 送入 encoder(Enc),然后学习 μ \mu μ 和 θ \theta θ 来建模 s s s
- 然后,使用 decoder(Dec)通过 resample 来生成 multimodal 输出
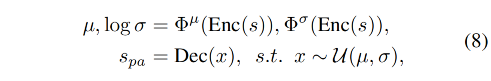
- Φ \Phi Φ:是 MLP
- U ( μ , θ ) U(\mu, \theta) U(μ,θ):是高斯分布
为了让 ProbAttn 能够学习更丰富的风格,使用 KL 散度 loss 来约束 t-VAE 的特征:
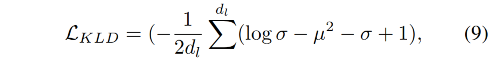
- d l d_l dl:是 μ \mu μ 的维度
3、整合两个 attention 的输出
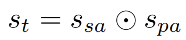
Loss 函数:
MODA 有四个 decoder,分别生成不同部位的运动系数
所以作者使用了 multi-task 学习机制,通过最小化对应的 L 1 L_1 L1 距离来实现:
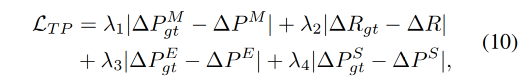
加上 KL loss:
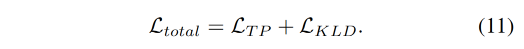
2.3 Facial Composer Network
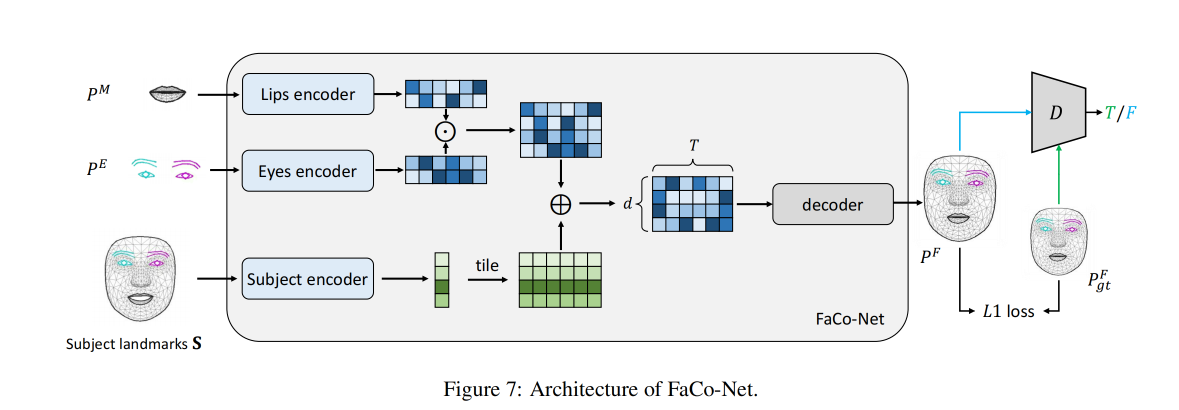
Facial composer network (FaCo-Net)的输入是 subject information S S S 、mouth point P M P^M PM 、eye point P E P^E PE
FaCo-Net 的目标:合成更精细的面部 landmark P F P^F PF:
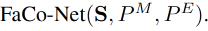
FaCo-Net 的结构:
- 3 个 encoder 对 3 种特征分别编码
- subject encoder:将 facial point S S S 映射到 style code p f p_f pf
- P M P^M PM encoder:将 P M P^M PM 映射到和 p f p_f pf 同一空间的 p m p_m pm
- P E P^E PE encoder:将 P E P^E PE 映射到和 p f p_f pf 同一空间的 p e p_e pe
- 1 个 decoder 生成面部 landmark

Faco-Net 的作用是生成器:生成 “看起来逼真” 的 facial dense point
生成器的 loss 如下:
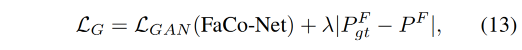
- L G A N L_{GAN} LGAN 是 adversarial loss, z ˆ = D ( P F ) \^{z}=D(P^F) zˆ=D(PF)
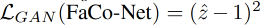
- λ \lambda λ:10
判别器 D:使用 GAN 作为判别器的 backbone 来判断是真实的 facial points 还是生成的 facial points
用于优化判别器 D 的 adversarial Loss:LSGAN loss
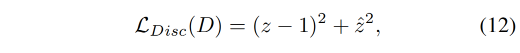
- z z z:输入为 gt face points 时,判别器的输出
- z ˆ \^{z} zˆ:输入为 生成的 face points 时,判别器的输出
生成 facial landmarks P F P^F PF 后, P F P^F PF 会根据 head pose 来变换到 camera coordinate
torso points 和 变换后的 facial landmark 会映射到 image space 来进行写实的渲染
2.4 使用 TPE 来合成人像图片
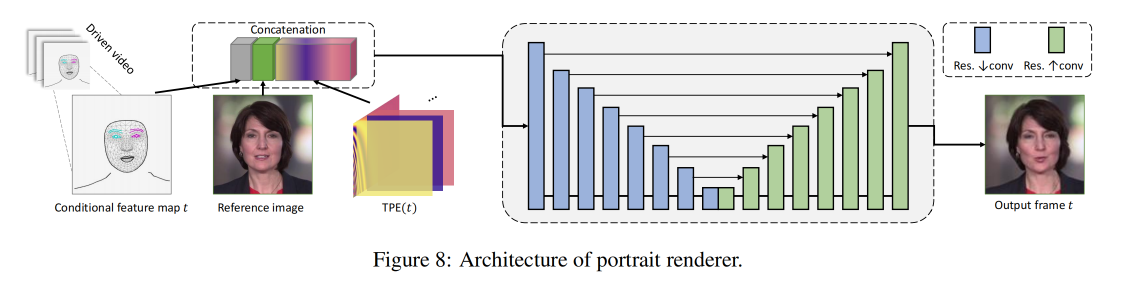
最后就是要将前面得到的输出来渲染出人像,如图 2
作者使用 U-Net-like 的带 TPE 的渲染器 G R G_R GR 来生成高保真且稳定的视频
TPE :
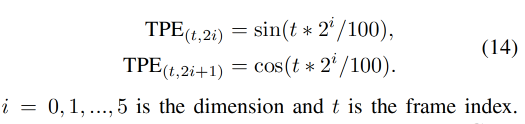
然后使用 G R G_R GR来渲染 t-frame 的结果 I t I_t It
- I t c I_t^c Itc:是 frame index t 时的 condition image
- I r I_r Ir:是 reference image
三、效果
3.1 训练细节
训练细节:
- 超参数 ( β 1 , β 2 ) = ( 0.9 , 0.99 ) (\beta_1, \beta_2)=(0.9,0.99) (β1,β2)=(0.9,0.99)
- 学习率:10^-4
- 单卡 3090:三个部分分别需要 (30, 2, 6) 小时,(200,300,100)epoch,(32,32,4) batch
- 测试时,选择最小的验证 loss 的模型
- 使用滑动窗口来处理任意长度的视频(window size 300,stirde 150)
3.2 数据
作者使用的 HDTF 和 LSP 数据,video 的平均长度为 1-5 分钟,并且作者将其处理成了 25 fps
作者随机选择 80% 的视频作为训练集,其他的作为测试集,也就是有 132 个训练视频,32 个测试视频
所有视频以人脸为中心,被 resize 成 512x512 大小
数据预处理:
- 首先,使用 Mediapipe 对所有视频提取 478 个 3D facial landmarks
- 然后,使用开源方法估计 head pose H,且根据 head pose,将上面的 3D facial landmarks 投影到 canonical space
- 接着,使用 face parsing 方法来根据分割结果估计出 torso 的 boundary
3.3 测评指标
- LMD:mouth landmark distance,衡量生成的视频的唇部正确性
- LMD-v:velocity of mouth landmark distance,衡量生成的视频的唇部正确性
- MA:衡量预测的 mouth area 和真实的 mouth area 的 IoU
- confidence score from SyncNet:衡量 audio-video 的合成
- Natural Image Quality Evaluator (NIQE) :衡量图像的质量,能够捕捉图像的细节
3.4 结果比较
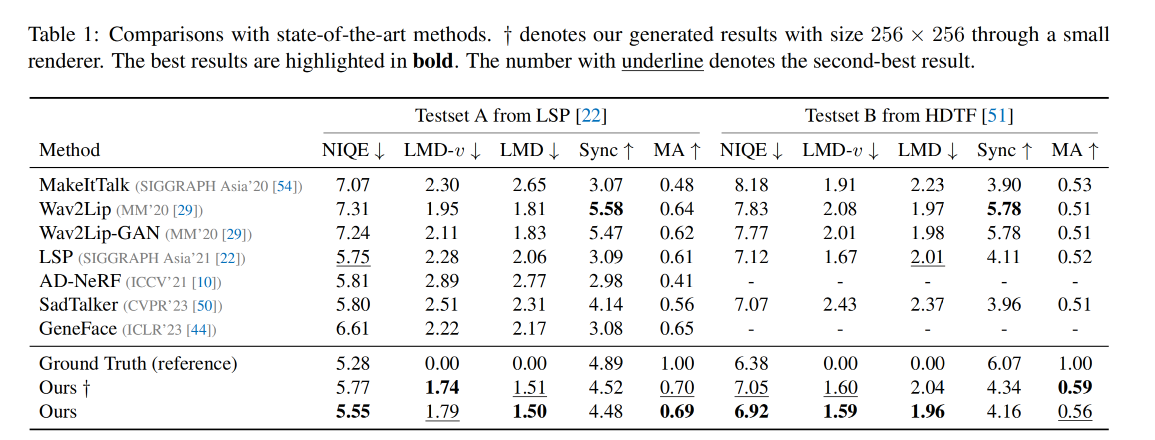
和 SOTA 结果的定量比较:


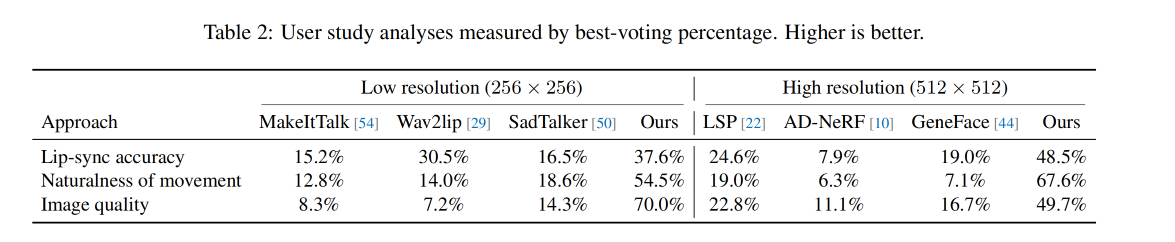
User Study:
消融实验:
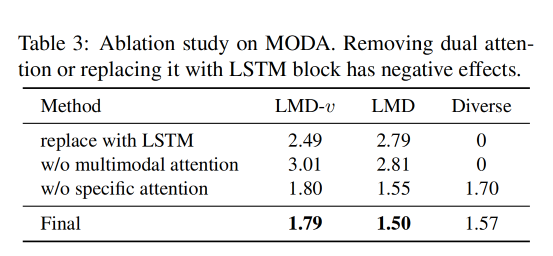
dual-attention 的消融实验效果:
- 使用 LSTM 代替 dual-attention,LSTM 无法获得 multimodal 的结果,且 diverse score 降低到了 0
- 移除 specific attention branch,移除后,MODA 生成的唇部运动结果过平滑
- 移除两个 attention branch
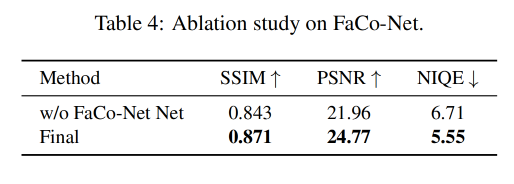
FaCo-Net 消融实验:该模型的目标是为了为渲染器生成自然且连续的表达特征
作者通过移除该模块,直接使用 facial dense landmark 来代替 eye landmark 和 mouth landmark,如图 6a 展示了没有 FaCo-Net 的结果,唇部区域联系不太正常,且丢失了一些脸部细节

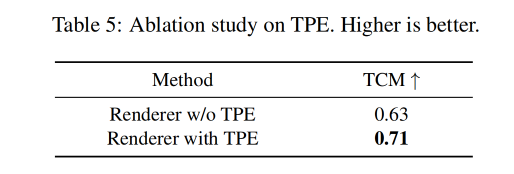
TPE 消融实验
作者使用时序一致性衡量方式来衡量 frame-wise consistency(TCM),
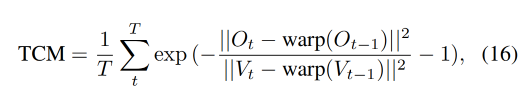
- O t O_t Ot 表示 reference video(O)第 t 帧
- V t V_t Vt 表示 generated video (V) 第 t 帧
- warp(.) 表示使用 optical flow 的 warping function
- 图 6b 展示了 with/without TPE 的对比效果,可以看出使用 TPE 能够让输出视频更稳定

本文方法的限制:
- 不能很好的泛化到不同的目标人物或 out-of-domain audio
- 对于新的人物要重新训练渲染部分的模型
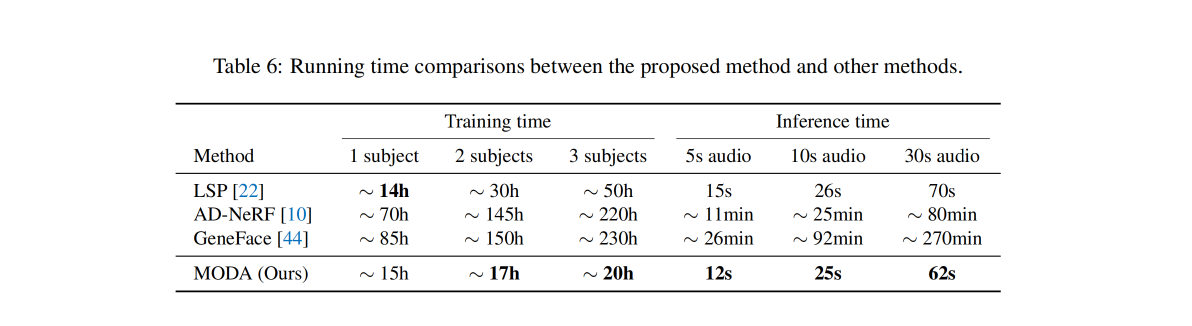
单卡 3090 训练时间和测试时间对比:
四、代码
4.1 数据前处理
git clone https://github.com/DreamtaleCore/MODA.git
1、装环境
我按照官方给出的方法没有装成功,是一步步按 conda 的命令装的
2、下载 HDTF 数据
这里目前只找到了 HDTF 的数据:
有下载 HDTF 工具的 github 路径:https://github.com/universome/HDTF
- 下载方式:
python download.py --output_dir /path/to/output/dir --num_workers 8 - 注意:要科学上网,需要安装 ffmpeg、youtubu-dl,否则会报错,报错原因可以去下载路径下的 log 中去看
- 注意:将
download.py的第 168 行修改成video_selection = f"best[ext={video_format}]",才能保证下载的视频有声音,否则下载的视频没有声音
3、处理数据
处理数据在 MODA/data_prepare/ 目录下:
第一步:先编译 3DDFA-V2 的环境:
cd 3DDFA-V2
bash build.sh
cd ..
我用 MODA 自带下来的 3DDFA-V2 无法 build,自己重新 clone 了一份 3DDFA_V2 才 build 成功
sh ./build.sh
第二步:下载 face-parsing 的模型并上传到 face-parsing/res/cp 中
第三步:执行处理代码:
python process.py -i your/video/dir -o your/output/dir
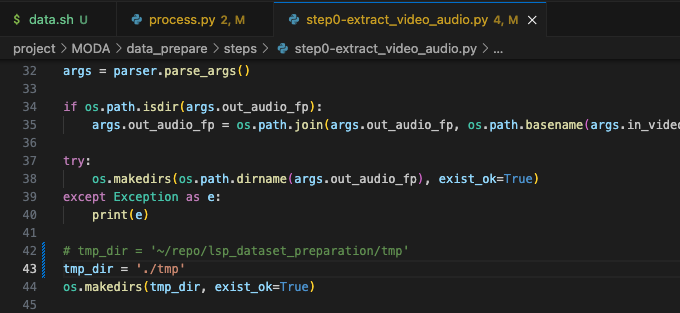
报错 1 :这里 step0 第 42 行的路径没有写入权限,导致无法在程序运行中间写入,换成有权限的目录
报错 2:unrecognized option 'crf'
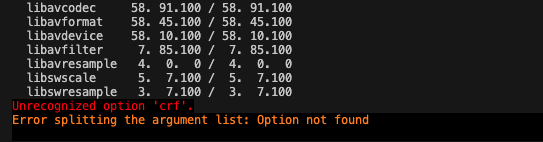
这常见于在使用 ffmpeg 时使用到了 libx264,但在实际的编译过程中并有指定编译 libx264 参数,默认不会编译这一部分组件,从而产生报错。
可以使用 apt 安装 ffmpeg :
sudo apt install ffmpeg //通过 apt 安装 ffmpeg
或者如下方式解决:
conda install x264
conda install x264 ffmpeg -c conda-forge
但我都没有解决,然后我就把 -crf 参数舍弃了哈哈哈
修改 step0 中的 line 51 如下:
# cvt_wav_cmd = 'ffmpeg -i ' + vfp + f' -vf scale={args.target_h}:{args.target_w} -crf 2 ' + args.out_video_fp + ' -y' # 无法处理 crf 参数
cvt_wav_cmd = 'ffmpeg -i ' + vfp + f' -vf scale={args.target_h}:{args.target_w} '+ args.out_video_fp + ' -y' # 注意 {args.target_w} 后的空格
报错 3:no module named 'FaceBoxes'
暂且将这里改成了绝对路径,得以解决
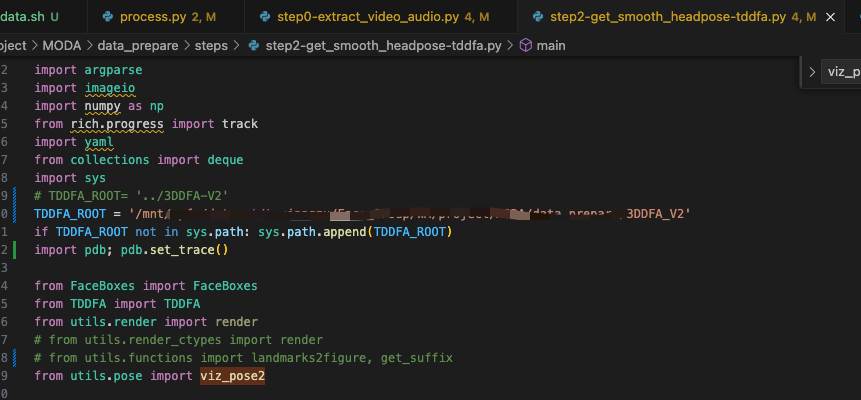
报错 4:找不到 viz_pose2
因为我这里用了 3DDFA_V2 源码,源码中没有这个函数,所以我从 MODA 中重新拷了这个函数,解决了
报错 5:
Could not find a backend to open `/mnt/cpfs/dataset/tuxiangzu/Face_Group/WM/project/MODA/HDTF_PROCESS/RD_Radio11_000/video.mp4`` with iomode `r?`

python -m pip install imageio[ffmpeg]python -m pip install imageio[pyav]
报错 6:
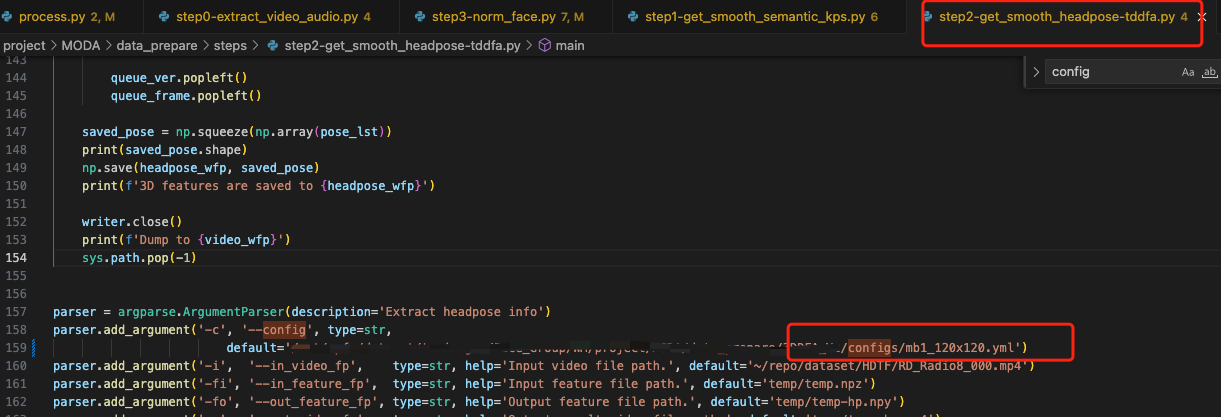
找不到 step2 中的 3DDFA-V2/config/mb1_120x120.yml,这里没发现作者写成了非下划线,改了好久才发现,我们使用的是 3DDFA_V2 是这样写的,注意修改
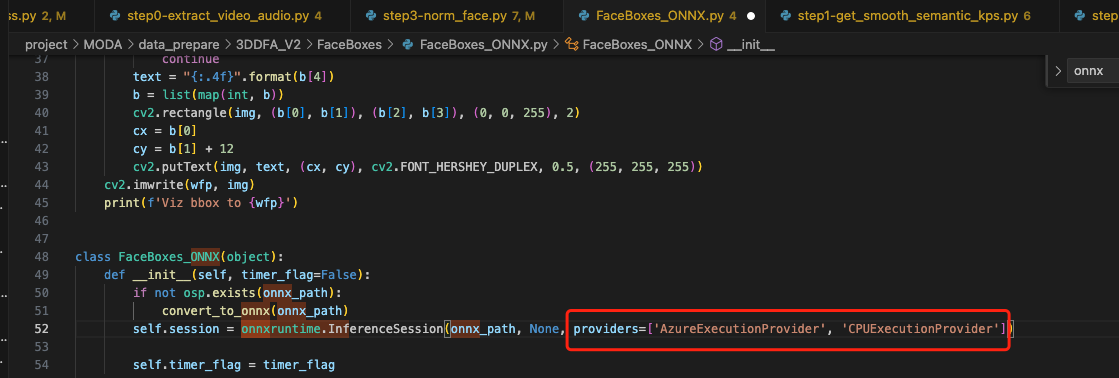
报错 7:onnxruntime.InferenceSession 报错

按上面的提示添加对应参数:
报错 8 : 找不到 config 中写的路径, No such file or directory: 'weights/mb1_120x120.pth', No such file or directory: 'configs/bfm_noneck_v3.pkl'
不知道是编译问题还是怎么的,相对路径都不起作用,暂且将 mb1_120x120.yml 中的路径都改为绝对路径
报错 9:module 'numpy' has no attribute 'long',改为 np.longlong()
numpy.long 在 numpy 1.20中被弃用,并在 numpy 1.24 中被删除,可以尝试 numpy.longlong


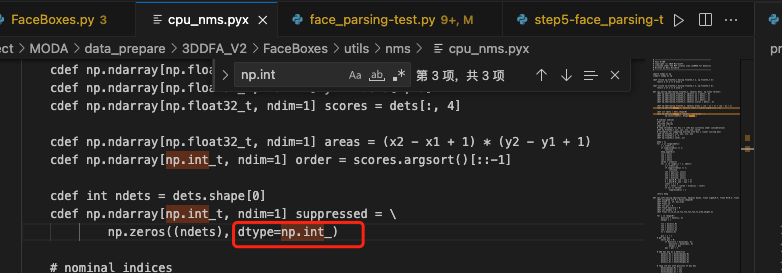
报错 10:AttributeError: module 'numpy' has no attribute 'int'.

修改为 np.int_,然后重新编译 sh ./build.sh
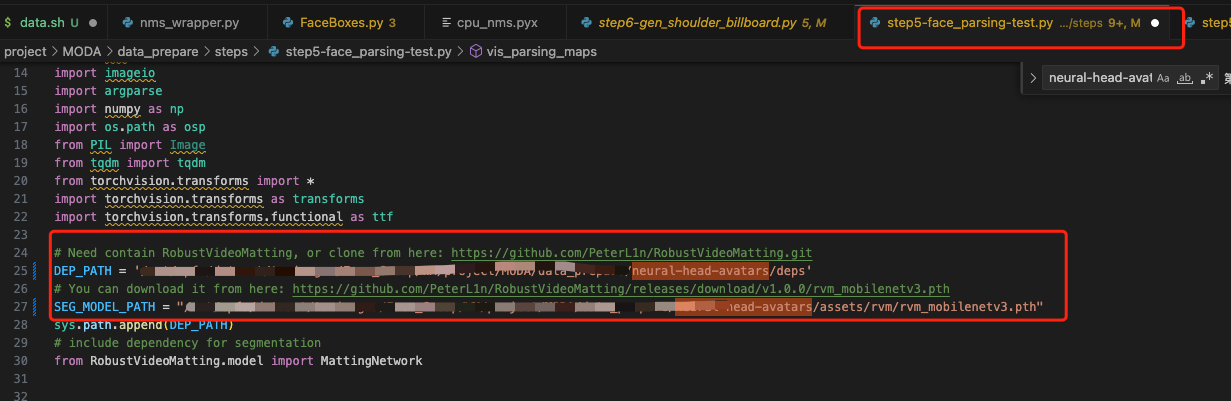
报错 11:ModuleNotFoundError: No module named 'RobustVideoMatting'

报错 12:其实是提示,但这里也最好改一下,在 step5 中 加上 n_init 这个参数:

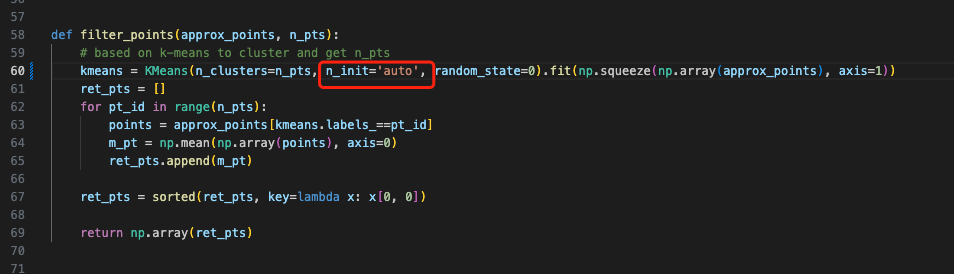
最后就愉快的跑起来啦,我这里其实很多问题都是相对路径找不到的锅~
预估跑完 HDTF 的 167 个视频需要一两天时间,8线程
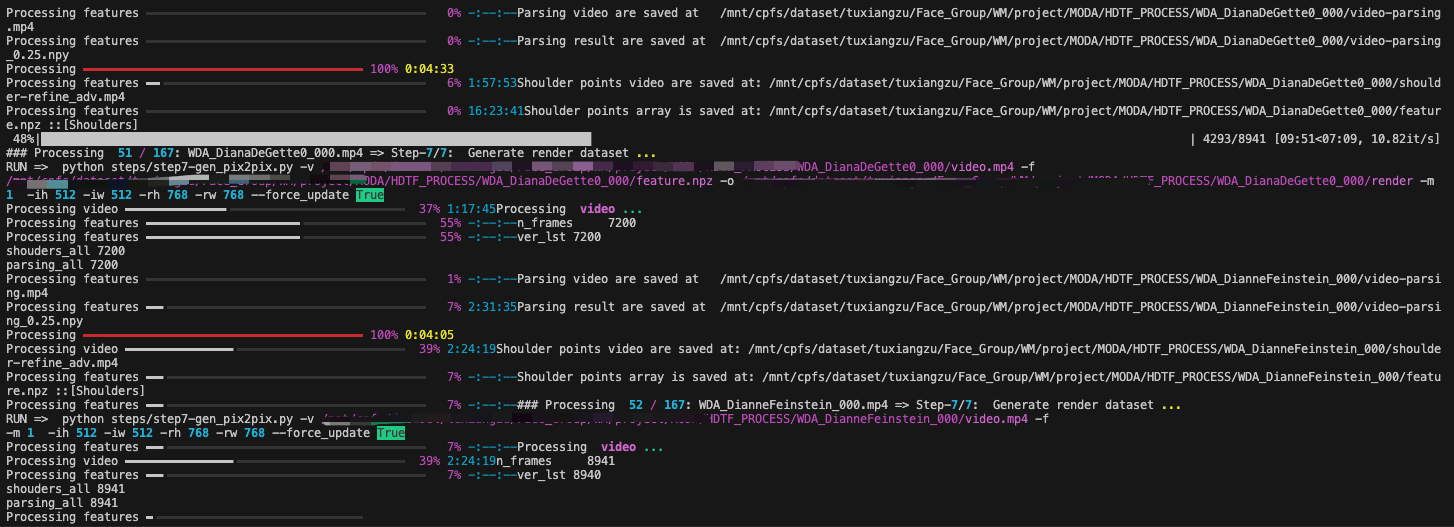
训练时报的错误:缺少 shoulder-billboard.npy
其实可以看到在整个数据处理过程是没有运行 step6 这个文件的,也就是没有从 shoulder.npy 生成 shoulder-billboard.npy,所以训练时候在 audio2repr_dataset.py 中是找不到这个文件的
但作者这里代码和实现逻辑有些出入,没有专门生成 shoulder.py 而是将其写入了 feature.npz 中,可以通过如下方式来调用,所以可以在 step5 后面加入 step6,将 process.py 中的 force_update=False,就是如果已有需要生成的文件时,不执行步骤,这样就能只执行 step6,不执行其他步骤了,生成对应的 shoulder-billboard.npy 就可以了。
process.py

step6.py
将 62 行注释,添加 64 行
这里下载的视频数据有些被损坏,有些没有内容,需要删除:
- WDA_MaggieHassan_000.mp4
- WRA_PeterKing_000.mp4
4.2 训练
首先,建立自己的 train.txt 和 val.txt
这里作者写的是随机选取的,代码里也没有写是怎么选的,所以我这里也就先随机选了一些:
import os
import random
datapath = 'MODA/assets/dataset/HDTF/HDTF_PROCESS'
dir_list = os.listdir(datapath)
val_list_num = random.sample([x for x in range(0, len(dir_list))], 32)
with open('assets/dataset/HDTF/train.txt', 'w') as f1:with open('assets/dataset/HDTF/val.txt', 'w') as f2:for i, dirs in enumerate(dir_list):if i in val_list_num:f2.write('HDTF_PROCESS/' + dirs + '\n')else:f1.write('HDTF_PROCESS/' + dirs + '\n')
得到的 txt 中放的就是这样的路径:
报错 1:Expected more than 1 value per channel when training, got input size [1,128]
这里的原因应该是最后一个 batch=1 了,所以这里设置丢弃最后一个就行了
MODA/dataset/__init__.py 的 self.dataloader 中的 drop_last=True 打开
模型结构:
model [MODAModel] was created
---------- Networks initialized -------------
[Network MODA] Total number of parameters : 96.718 M
-----------------------------------------------
---------- Networks initialized -------------
DataParallel((module): MODANet((audio_encoder): Wav2Vec2Model((feature_extractor): Wav2Vec2FeatureEncoder((conv_layers): ModuleList((0): Wav2Vec2GroupNormConvLayer((conv): Conv1d(1, 512, kernel_size=(10,), stride=(5,), bias=False)(activation): GELUActivation()(layer_norm): GroupNorm(512, 512, eps=1e-05, affine=True))(1): Wav2Vec2NoLayerNormConvLayer((conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)(activation): GELUActivation())(2): Wav2Vec2NoLayerNormConvLayer((conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)(activation): GELUActivation())(3): Wav2Vec2NoLayerNormConvLayer((conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)(activation): GELUActivation())(4): Wav2Vec2NoLayerNormConvLayer((conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)(activation): GELUActivation())(5): Wav2Vec2NoLayerNormConvLayer((conv): Conv1d(512, 512, kernel_size=(2,), stride=(2,), bias=False)(activation): GELUActivation())(6): Wav2Vec2NoLayerNormConvLayer((conv): Conv1d(512, 512, kernel_size=(2,), stride=(2,), bias=False)(activation): GELUActivation())))(feature_projection): Wav2Vec2FeatureProjection((layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)(projection): Linear(in_features=512, out_features=768, bias=True)(dropout): Dropout(p=0.1, inplace=False))(encoder): Wav2Vec2Encoder((pos_conv_embed): Wav2Vec2PositionalConvEmbedding((conv): Conv1d(768, 768, kernel_size=(128,), stride=(1,), padding=(64,), groups=16)(padding): Wav2Vec2SamePadLayer()(activation): GELUActivation())(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False)(layers): ModuleList((0): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(1): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(2): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(3): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(4): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(5): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(6): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(7): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(8): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(9): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(10): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(11): Wav2Vec2EncoderLayer((attention): Wav2Vec2Attention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(dropout): Dropout(p=0.1, inplace=False)(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(feed_forward): Wav2Vec2FeedForward((intermediate_dropout): Dropout(p=0.1, inplace=False)(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)(intermediate_act_fn): GELUActivation()(output_dense): Linear(in_features=3072, out_features=768, bias=True)(output_dropout): Dropout(p=0.1, inplace=False))(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)))))(audio_encoder_head): MLP((layers): Sequential((0): Linear(in_features=768, out_features=128, bias=True)(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): LeakyReLU(negative_slope=0.2)(3): Linear(in_features=128, out_features=128, bias=True)))(subject_encoder_head): MLP((layers): Sequential((0): Linear(in_features=1434, out_features=128, bias=True)(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): LeakyReLU(negative_slope=0.2)(3): Linear(in_features=128, out_features=128, bias=True)(4): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): LeakyReLU(negative_slope=0.2)(6): Linear(in_features=128, out_features=128, bias=True)))(temporal_body): DualTemporalMoudleV2((short_layer): TemporalAlignedBlock((decoder): TransformerDecoder((layers): ModuleList((0): TransformerDecoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(multihead_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(linear1): Linear(in_features=128, out_features=128, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=128, out_features=128, bias=True)(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False)(dropout3): Dropout(p=0.1, inplace=False))(1): TransformerDecoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(multihead_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(linear1): Linear(in_features=128, out_features=128, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=128, out_features=128, bias=True)(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False)(dropout3): Dropout(p=0.1, inplace=False))(2): TransformerDecoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(multihead_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(linear1): Linear(in_features=128, out_features=128, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=128, out_features=128, bias=True)(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False)(dropout3): Dropout(p=0.1, inplace=False))))(ppe): PeriodicPositionalEncoding((dropout): Dropout(p=0.1, inplace=False)))(long_layer): TemporalVAEBlock((embedding): PositionalEncoding((dropout): Dropout(p=0.1, inplace=False))(encoder): TransformerEncoder((layers): ModuleList((0): TransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(linear1): Linear(in_features=128, out_features=128, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=128, out_features=128, bias=True)(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False))(1): TransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(linear1): Linear(in_features=128, out_features=128, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=128, out_features=128, bias=True)(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False))(2): TransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(linear1): Linear(in_features=128, out_features=128, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=128, out_features=128, bias=True)(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False))))(decoder): TransformerDecoder((layers): ModuleList((0): TransformerDecoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(multihead_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(linear1): Linear(in_features=128, out_features=128, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=128, out_features=128, bias=True)(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False)(dropout3): Dropout(p=0.1, inplace=False))(1): TransformerDecoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(multihead_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(linear1): Linear(in_features=128, out_features=128, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=128, out_features=128, bias=True)(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False)(dropout3): Dropout(p=0.1, inplace=False))(2): TransformerDecoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(multihead_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=128, out_features=128, bias=True))(linear1): Linear(in_features=128, out_features=128, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=128, out_features=128, bias=True)(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False)(dropout3): Dropout(p=0.1, inplace=False))))(out): Sequential((0): Linear(in_features=128, out_features=128, bias=True))(to_mu): Linear(in_features=128, out_features=128, bias=True)(to_logvar): Linear(in_features=128, out_features=128, bias=True)(decode_latent): Linear(in_features=128, out_features=128, bias=True)))(lipmotion_tail): MLP((layers): Sequential((0): Linear(in_features=256, out_features=512, bias=True)(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): LeakyReLU(negative_slope=0.2)(3): Linear(in_features=512, out_features=120, bias=True)))(eyemovement_tail): MLP((layers): Sequential((0): Linear(in_features=256, out_features=256, bias=True)(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): LeakyReLU(negative_slope=0.2)(3): Linear(in_features=256, out_features=256, bias=True)(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): LeakyReLU(negative_slope=0.2)(6): Linear(in_features=256, out_features=180, bias=True)))(headmotion_tail): MLP((layers): Sequential((0): Linear(in_features=256, out_features=256, bias=True)(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): LeakyReLU(negative_slope=0.2)(3): Linear(in_features=256, out_features=256, bias=True)(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): LeakyReLU(negative_slope=0.2)(6): Linear(in_features=256, out_features=7, bias=True)))(torsomotion_tail): MLP((layers): Sequential((0): Linear(in_features=256, out_features=256, bias=True)(1): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): LeakyReLU(negative_slope=0.2)(3): Linear(in_features=256, out_features=256, bias=True)(4): BatchNorm1d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): LeakyReLU(negative_slope=0.2)(6): Linear(in_features=256, out_features=54, bias=True))))
)
[Network MODA] Total number of parameters : 96.718 M

lip decoder:MLP
Sequential((0): Linear(in_features=256, out_features=512, bias=True)(1): BatchNorm1d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): LeakyReLU(negative_slope=0.2)(3): Linear(in_features=512, out_features=120, bias=True)
)
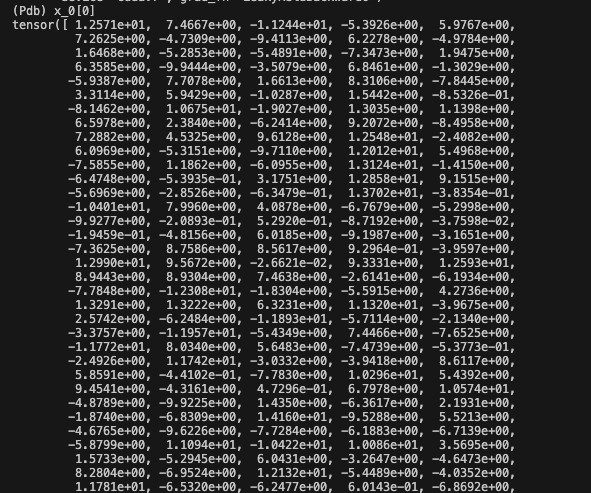
batch norm 输出后的特征(x_1)基本都一样了
layer_0 的输出:
layer_1 的输出:全为负值
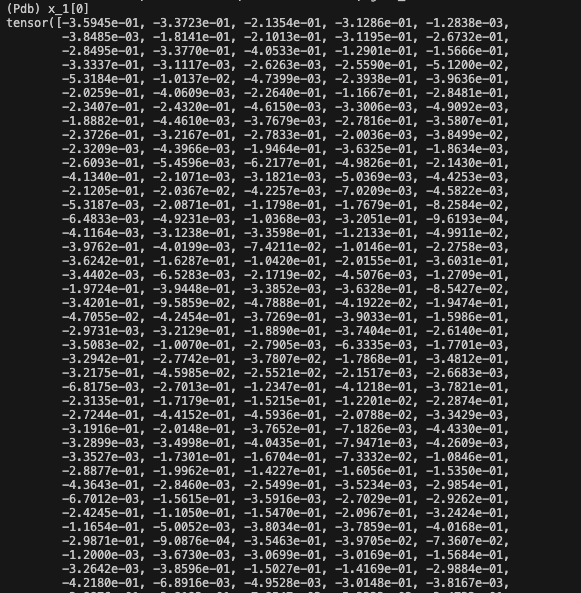
推测是模型根本没训练好,可能是学习率的问题,也可能是 target 的问题
这里把学习率从原本的 1e-4 调到了 1e-3 和 1e-5,都没有什么改变,loss 很大,尤其是 headmotion loss 大概在几十万,所以这里 target 的训练应该是有问题的
所以我又去看了看为什么 loss 这么大,发现 target_headmotion 和 target_torsomotion 的数据分布范围很大:
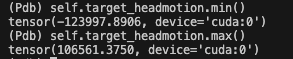
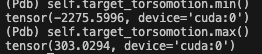
可以看看其他的 target 还是比较小的:

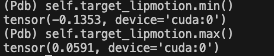
去 audio2repr_dataset.py 中看看数据是怎么处理的:

data: len=17,这里的 1200 表示 batch=2,每个 batch 帧数为 600
data_list[file_index][0]:audio_array,tensor([-0.8657, -0.9239, -0.8294, …, -0.0095, -0.0519, -0.1292]),torch.Size([640128])data_list[file_index][1]:av_rate,533data_list[file_index][2]:face_vertices,torch.Size([1200, 478, 3])data_list[file_index][3]:face_vert_ref 均值,[478, 3]data_list[file_index][4]:face_vert_ref 方差,[478, 3]data_list[file_index][5]:face_headposes,[1200, 3]data_list[file_index][6]:face_head_ref 均值,[3]data_list[file_index][7]:face_head_ref 方差, [3]data_list[file_index][8]:face_transposes, [1200, 3]data_list[file_index][9]:face_trans_ref 均值, [3]data_list[file_index][10]:face_trans_ref 方差, [3]data_list[file_index][11]:face_scales, [1200, 1]data_list[file_index][12]:face_scale_ref 均值, [1]data_list[file_index][13]:face_scale_ref 方差, [1]data_list[file_index][14]:torso_info, [1200, 18, 3]data_list[file_index][15]:torso_info_ref 均值, [18, 3]data_list[file_index][16]:torso_info_ref 方差, [18, 3]
4.3 推理
先使用 mediapipe 来提取面部关键点
# 一段从 utils.py 截出来的代码片,只是展示操作方式而已
import mediapipe as mp
mp_drawing_styles = mp.solutions.drawing_styles
mp_connections = mp.solutions.face_mesh_connections
def get_semantic_indices():semantic_connections = {'Contours': mp_connections.FACEMESH_CONTOURS,'FaceOval': mp_connections.FACEMESH_FACE_OVAL,'LeftIris': mp_connections.FACEMESH_LEFT_IRIS,'LeftEye': mp_connections.FACEMESH_LEFT_EYE,'LeftEyebrow': mp_connections.FACEMESH_LEFT_EYEBROW,'RightIris': mp_connections.FACEMESH_RIGHT_IRIS,'RightEye': mp_connections.FACEMESH_RIGHT_EYE,'RightEyebrow': mp_connections.FACEMESH_RIGHT_EYEBROW,'Lips': mp_connections.FACEMESH_LIPS,'Tesselation': mp_connections.FACEMESH_TESSELATION}def get_compact_idx(connections):ret = []for conn in connections:ret.append(conn[0])ret.append(conn[1])return sorted(tuple(set(ret)))semantic_indexes = {k: get_compact_idx(v) for k, v in semantic_connections.items()}return semantic_indexes
generate_feature.py 得到的面部信息如下:
{
'Contours': [0, 7, 10, 13, 14, 17, 21, 33, 37, 39, 40, 46, 52, 53, 54, 55, 58, 61, 63, 65, 66, 67, 70, 78, 80, 81, 82, 84, 87, 88, 91, 93, 95, 103, 105, 107, 109, 127, 132, 133, 136, 144, 145, 146, 148, 149, 150, 152, 153, 154, 155, 157, 158, 159, 160, 161, 162, 163, 172, 173, 176, 178, 181, 185, 191, 234, 246, 249, 251, 263, 267, 269, 270, 276, 282, 283, 284, 285, 288, 291, 293, 295, 296, 297, 300, 308, 310, 311, 312, 314, 317, 318, 321, 323, 324, 332, 334, 336, 338, 356, 361, 362, 365, 373, 374, 375, 377, 378, 379, 380, 381, 382, 384, 385, 386, 387, 388, 389, 390, 397, 398, 400, 402, 405, 409, 415, 454, 466],
'FaceOval': [10, 21, 54, 58, 67, 93, 103, 109, 127, 132, 136, 148, 149, 150, 152, 162, 172, 176, 234, 251, 284, 288, 297, 323, 332, 338, 356, 361, 365, 377, 378, 379, 389, 397, 400, 454],
'LeftIris': [474, 475, 476, 477],
'LeftEye': [249, 263, 362, 373, 374, 380, 381, 382, 384, 385, 386, 387, 388, 390, 398, 466],
'LeftEyebrow': [276, 282, 283, 285, 293, 295, 296, 300, 334, 336],
'RightIris': [469, 470, 471, 472],
'RightEye': [7, 33, 133, 144, 145, 153, 154, 155, 157, 158, 159, 160, 161, 163, 173, 246],
'RightEyebrow': [46, 52, 53, 55, 63, 65, 66, 70, 105, 107],
'Lips': [0, 13, 14, 17, 37, 39, 40, 61, 78, 80, 81, 82, 84, 87, 88, 91, 95, 146, 178, 181, 185, 191, 267, 269, 270, 291, 308, 310, 311, 312, 314, 317, 318, 321, 324, 375, 402, 405, 409, 415],
'Tesselation': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285, 286, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300, 301, 302, 303, 304, 305, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 327, 328, 329, 330, 331, 332, 333, 334, 335, 336, 337, 338, 339, 340, 341, 342, 343, 344, 345, 346, 347, 348, 349, 350, 351, 352, 353, 354, 355, 356, 357, 358, 359, 360, 361, 362, 363, 364, 365, 366, 367, 368, 369, 370, 371, 372, 373, 374, 375, 376, 377, 378, 379, 380, 381, 382, 383, 384, 385, 386, 387, 388, 389, 390, 391, 392, 393, 394, 395, 396, 397, 398, 399, 400, 401, 402, 403, 404, 405, 406, 407, 408, 409, 410, 411, 412, 413, 414, 415, 416, 417, 418, 419, 420, 421, 422, 423, 424, 425, 426, 427, 428, 429, 430, 431, 432, 433, 434, 435, 436, 437, 438, 439, 440, 441, 442, 443, 444, 445, 446, 447, 448, 449, 450, 451, 452, 453, 454, 455, 456, 457, 458, 459, 460, 461, 462, 463, 464, 465, 466, 467]}
这篇关于【数字人】2、MODA | 基于人脸关键点的语音驱动单张图数字人生成(ICCV2023)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







