iccv2023专题
![[论文阅读笔记31] Object-Centric Multiple Object Tracking (ICCV2023)](https://img-blog.csdnimg.cn/direct/e45906a3acc34a5e9398ebc675fbd75e.png)
[论文阅读笔记31] Object-Centric Multiple Object Tracking (ICCV2023)
最近Object centric learning比较火, 其借助了心理学的概念, 旨在将注意力集中在图像或视频中的独立对象(objects)上,而不是整个图像。这个方法与传统的基于像素或区域的方法有所不同,它试图通过识别和分离图像中的各个对象来进行学习和理解。 这个任务和跟踪有着异曲同工之处,跟踪也是需要在时序中定位感兴趣的目标。那么object centric learning能否用于无
![[ICCV2023]RenderIH:用于3D交互手部姿态估计的大规模合成数据集](https://img-blog.csdnimg.cn/direct/0911444a512445cabc03582074ab85cc.png)
[ICCV2023]RenderIH:用于3D交互手部姿态估计的大规模合成数据集
这篇论文的标题是《RenderIH: A Large-scale Synthetic Dataset for 3D Interacting Hand Pose Estimation》,作者是Lijun Li, Linrui Tian, Xindi Zhang, Qi Wang, Bang Zhang, Mengyuan Liu, 和 Chen Chen。他们来自阿里巴巴集团、上海人工智能实验室、北

免费阅读篇 | 芒果YOLOv8改进114:上采样Dysample:顶会ICCV2023,轻量级图像增采样器,通过学习采样来学习上采样,计算资源需求小
💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv8 按步骤操作运行改进后的代码即可 该专栏完整目录链接: 芒果YOLOv8深度改进教程 🚀🚀🚀 DySample是一个超轻量级和有效的动态上采样器,是一种更简洁、更高效的方式,用于提升图像分辨率。相较于传统的CARAFE和SAPA方法,DySample对计算资源的需求更小,能够在不增加额外负担的情况下实现图像分辨率的提升。 该
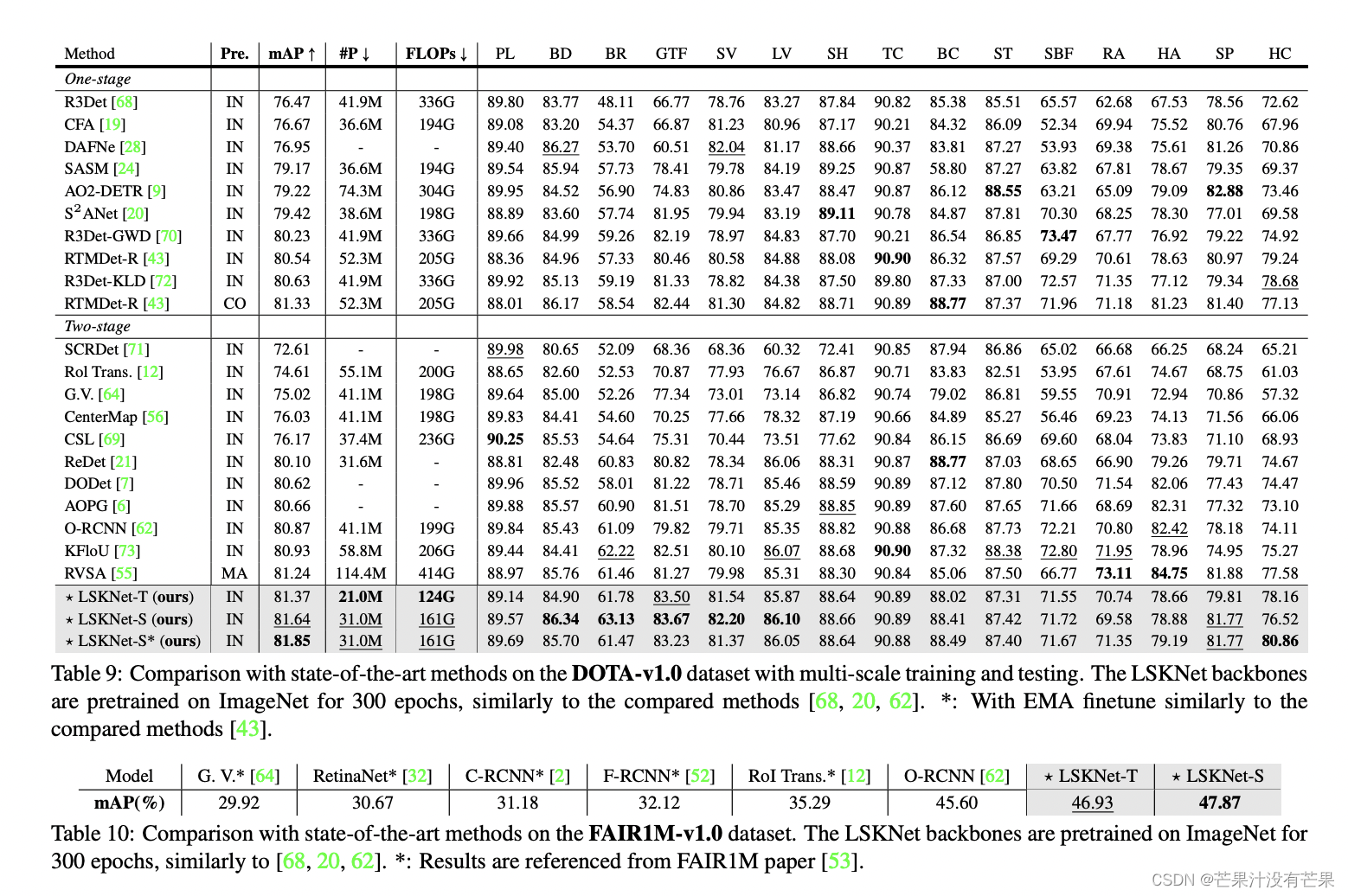
RT-DETR改进最新LSKNet结构:顶会ICCV2023|原创改进遥感旋转目标检测SOTA!大选择性卷积核的领域首次探索
💡本篇内容:RT-DETR改进最新LSKNet结构:顶会ICCV2023|原创改进遥感旋转目标检测SOTA!大选择性卷积核的领域首次探索 💡🚀🚀🚀本博客 RT-DETR + 遥感旋转目标检测SOTA!大选择性卷积核的领域首次探索 LSKNet 源代码改进 适用于 RT-DETR… 等等YOLO系列 按步骤操作运行改进后的代码即可 💡适合用来改进作为 🚀改进点 顶会ICCV2023

浙江大学刘勇教授课题组多项工作收录ICCV2023及近期学术成果汇编
点击下方卡片,关注“CVer”公众号 AI/CV重磅干货,第一时间送达 点击进入—>【目标检测和Transformer】交流群 ICCV(International Conference on Computer Vision,国际计算机视觉大会)是计算机领域世界顶级的学术会议之一,每两年举办一届,其论文集代表了计算机视觉领域最新的发展方向和水平,2023年将于今年10月在法国巴黎举行。近期,
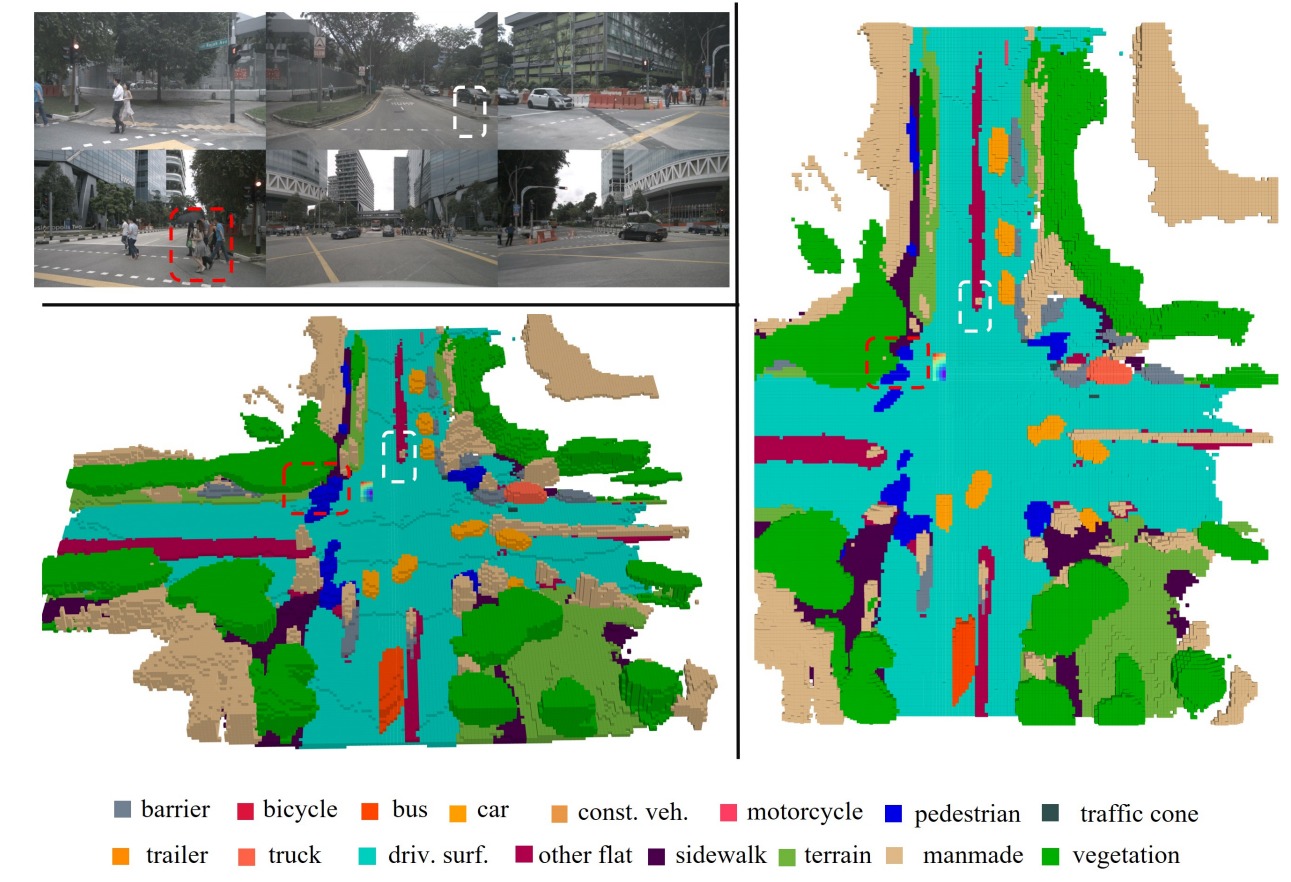
【占用网络】OccNet: Scene as Occupancy 适用于检测、分割和规划任务 ICCV2023
前言 本文分享“占用网络”方案中,具有代表性的方法:OccNet。 它以多视角相机为核心,首先生成BEV特征,然后通过级联结构和时间体素解码器重建生成3D占用特征。 构建一个通用的“3D占用编码特征”,用以表示3D物理世界。这样的特征描述可以应用于广泛的自动驾驶任务,包括检测、分割和规划。 论文地址:Scene as Occupancy 开源地址:https://github.com/O
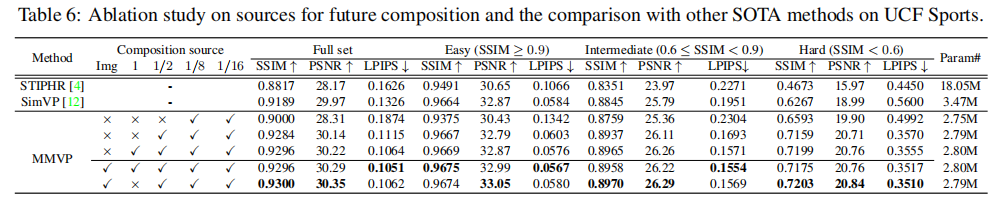
【ICCV2023】MMVP:基于运动矩阵的视频预测
目录 导读 本文方法 步骤1:空间特征提取 步骤2:运动矩阵的构造和预测 步骤3:未来帧的合成和解码 实验 实验结果 消融实验 结论 论文链接:https://openaccess.thecvf.com/content/ICCV2023/html/Zhong_MMVP_Motion-Matrix-Based_Video_Prediction_ICCV_2023_p
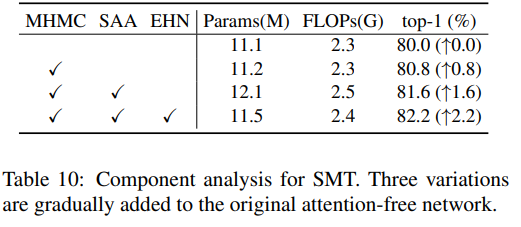
【ICCV2023】Scale-Aware Modulation Meet Transformer
Scale-Aware Modulation Meet Transformer, ICCV2023 论文:https://arxiv.org/abs/2307.08579 代码:https://github.com/AFeng-x/SMT 解读:ICCV2023 | 当尺度感知调制遇上Transformer,会碰撞出怎样的火花? - 知乎 (zhihu.com) 摘要 本文提出了一种
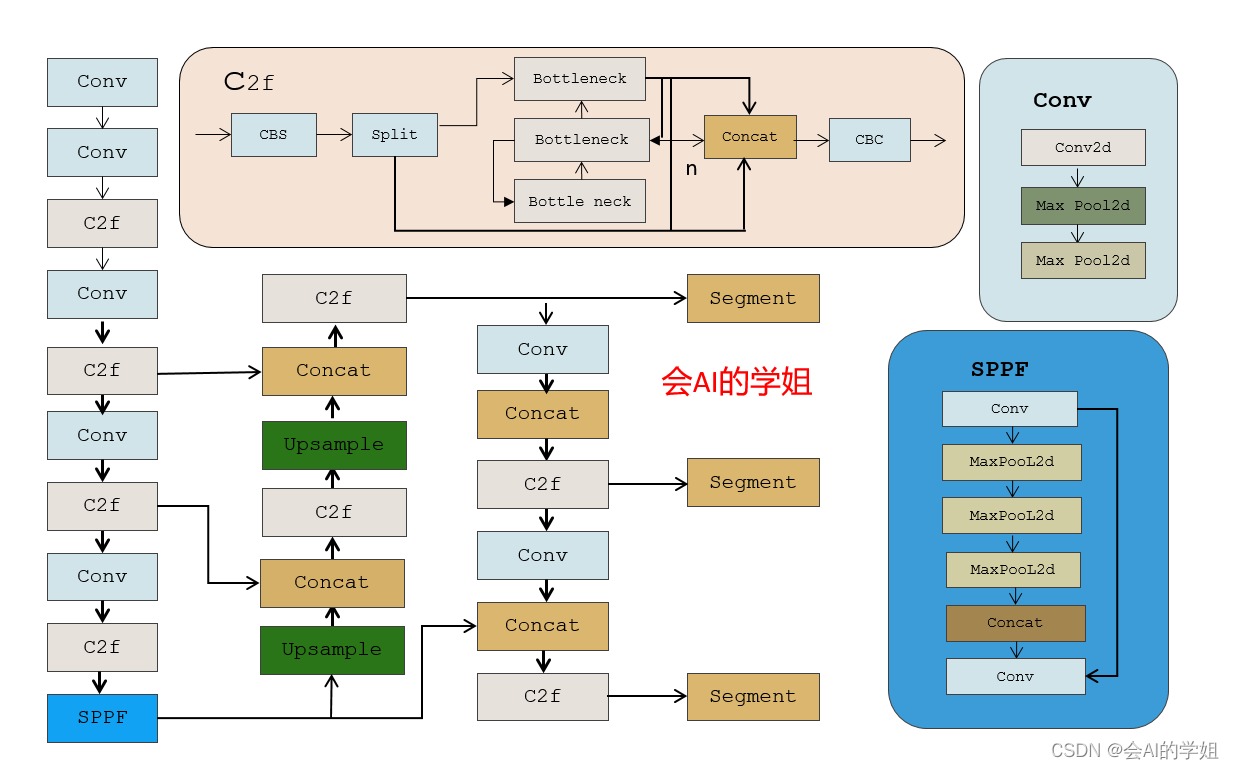
YOLOv8-Seg改进:动态蛇形卷积(Dynamic Snake Convolution) | ICCV2023
🚀🚀🚀本文改进:动态蛇形卷积(Dynamic Snake Convolution),增强微小特征提取能力,引入到YOLOv8-Seg,与C2f结合实现二次创新 🚀🚀🚀Dynamic Snake Convolution亲测在番薯破损分割任务中,mask mAP@0.5 从原始的0.625提升至0.645 🚀🚀🚀YOLOv8-seg创新专栏:http://t.csdnim
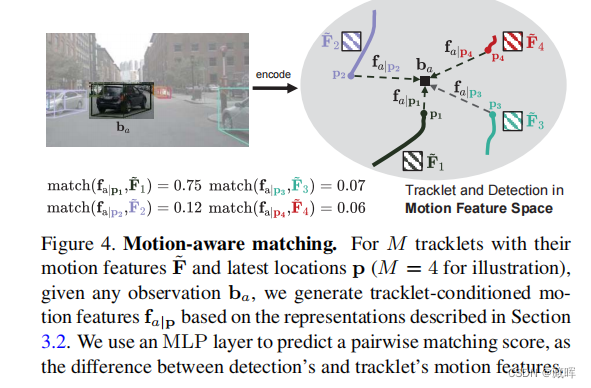
ICCV2023 Tracking paper汇总(一)(多目标跟随、单目标跟随等)
一、PVT++: A Simple End-to-End Latency-Aware Visual Tracking Framework paper: https://openaccess.thecvf.com/content/ICCV2023/papers/Li_PVT_A_Simple_End-to-End_Latency-Aware_Visual_Tracking_Framework_IC

【数字人】6、ER-NeRF | 借助空间分解来实现基于 NeRF 的更高效的数字人生成(ICCV2023)
文章目录 一、背景二、方法2.1 问题设定2.2 Tri-Plane Hash Representation2.3 Region Attention Module2.4 训练细节 三、效果3.1 实验设定3.2 定量对比3.3 定性对比3.4 User study3.5 消融实验 四、代码4.1 视频数据预处理4.2 训练4.3 推理 论文:Efficient Region-
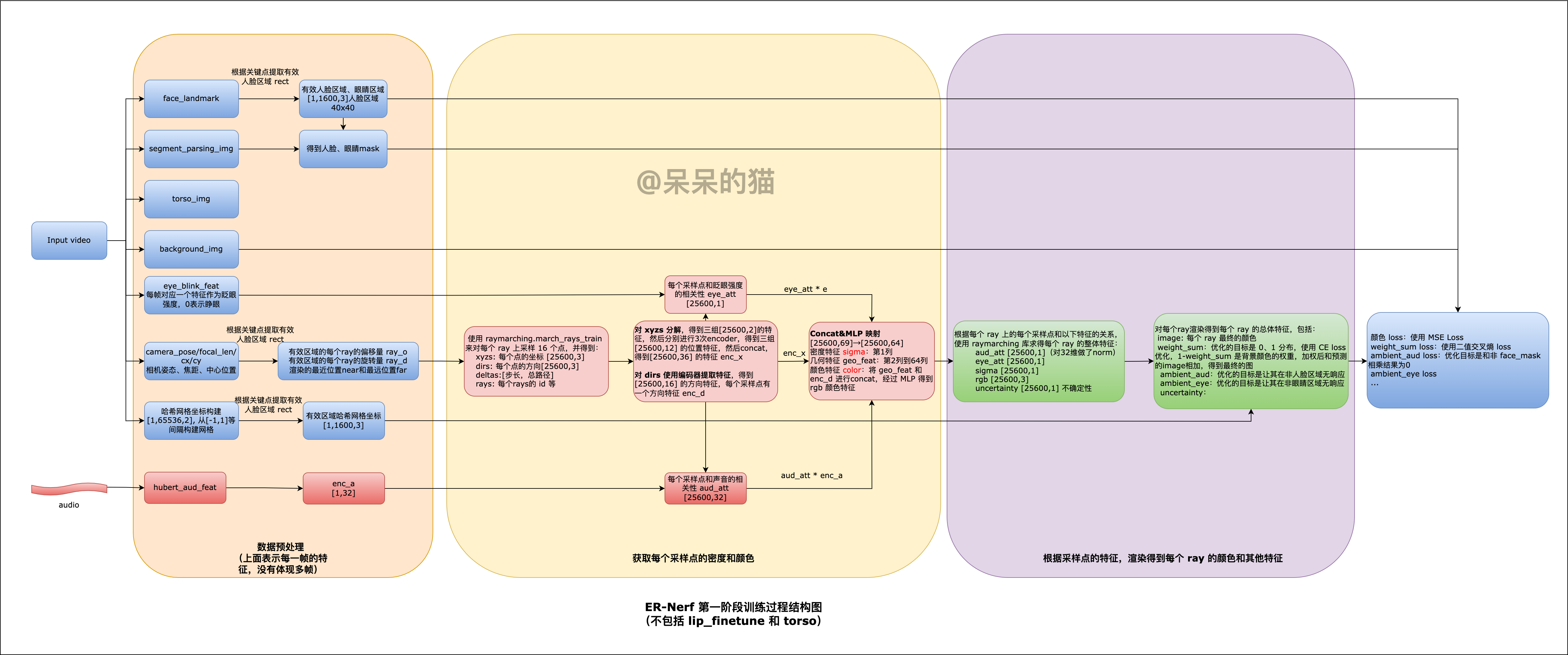
【数字人】6、ER-NeRF | 借助空间分解来实现基于 NeRF 的更高效的数字人生成(ICCV2023)
文章目录 一、背景二、方法2.1 问题设定2.2 Tri-Plane Hash Representation2.3 Region Attention Module2.4 训练细节 三、效果3.1 实验设定3.2 定量对比3.3 定性对比3.4 User study3.5 消融实验 四、代码4.1 视频数据预处理4.2 训练4.3 推理 论文:Efficient Region-

ICCV2023中super-resolution相关的文章汇总
1A Benchmark for Chinese-English Scene Text Image Super-Resolutionpytorch文本2HSR-Diff: Hyperspectral Image Super-Resolution via Conditional Diffusion Models 扩散模型<
ICCV2023领域泛化Domain Generalization相关论文
Domain Generalization即领域泛化,是近些年比较前沿的方向之一,顶会论文比较多。 Domain generalization deals with a challenging setting where one or several different but related domain(s) are given, and the goal is to learn a mo

YOLOv8血细胞检测(2):动态蛇形卷积(Dynamic Snake Convolution),增强细长微弱特征 | ICCV2023
💡💡💡本文独家改进:动态蛇形卷积(Dynamic Snake Convolution),增强细长微弱的局部结构特征与复杂多变的全局形态特征 Dynamic Snake Convolution | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.908 收录专栏: 💡💡💡YOLO医学影像检测:http://t.csdnimg.cn/N4zBP ✨✨✨实
YOLOv8血细胞检测(2):动态蛇形卷积(Dynamic Snake Convolution),增强细长微弱特征 | ICCV2023
💡💡💡本文独家改进:动态蛇形卷积(Dynamic Snake Convolution),增强细长微弱的局部结构特征与复杂多变的全局形态特征 Dynamic Snake Convolution | 亲测在血细胞检测项目中涨点,map@0.5 从原始0.895提升至0.908 收录专栏: 💡💡💡YOLO医学影像检测:http://t.csdnimg.cn/N4zBP ✨✨✨实

【数字人】2、MODA | 基于人脸关键点的语音驱动单张图数字人生成(ICCV2023)
文章目录 一、背景二、方法2.1 问题描述和数据预处理2.2 Mapping-Once network with Dual Attentions2.3 Facial Composer Network2.4 使用 TPE 来合成人像图片 三、效果3.1 训练细节3.2 数据3.3 测评指标3.4 结果比较 四、代码4.1 数据前处理4.2 训练4.3 推理 论文:MODA: M
【数字人】2、MODA | 基于人脸关键点的语音驱动单张图数字人生成(ICCV2023)
文章目录 一、背景二、方法2.1 问题描述和数据预处理2.2 Mapping-Once network with Dual Attentions2.3 Facial Composer Network2.4 使用 TPE 来合成人像图片 三、效果3.1 训练细节3.2 数据3.3 测评指标3.4 结果比较 四、代码4.1 数据前处理4.2 训练4.3 推理 论文:MODA: M