本文主要是介绍【数字人】6、ER-NeRF | 借助空间分解来实现基于 NeRF 的更高效的数字人生成(ICCV2023),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 一、背景
- 二、方法
- 2.1 问题设定
- 2.2 Tri-Plane Hash Representation
- 2.3 Region Attention Module
- 2.4 训练细节
- 三、效果
- 3.1 实验设定
- 3.2 定量对比
- 3.3 定性对比
- 3.4 User study
- 3.5 消融实验
- 四、代码
- 4.1 视频数据预处理
- 4.2 训练
- 4.3 推理
论文:Efficient Region-Aware Neural Radiance Fields for High-Fidelity Talking Portrait Synthesis
代码:https://github.com/Fictionarry/ER-NeRF
出处:ICCV2023
贡献:
- 高效渲染、快速收敛、实时推理
一、背景
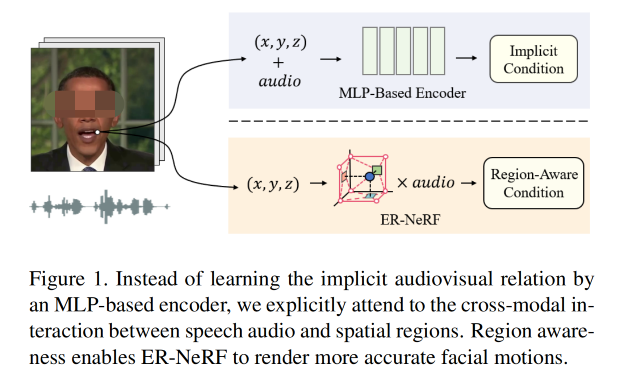
Neural Radiance Fields(NeRF)在近两年来也被用于 audio-driven talking portrait 的生成任务中了,其提供了一个新的思路来使用 MLP直接将 audio feature 映射到对应的视觉外观特征,可以直接进行端到端的学习,也可以经过中间特征表达来构建 talking portrait。
作者认为虽然 vanilla NeRF-based 方法效果还不错,但其速度和实时还相差甚远,这就导致难以用于实际应用中。
有一些方法通过使用 sparse feature grids 代替部分 MLP 的方式来提升原始 NeRF 的速度
Instant-NGP 引入 hash-encoded voxel grid 进行场景建模,能够又快又好的渲染
RAD-NeRF 首次将 Instant-NGP 中提出的技巧用于 talking portrait 生成,并且达到了一个实时 SOTA 的效果,但其需要复杂的 MLP-based grid encoder 来学习隐式的 regional audio-motion mapping,会限制收敛和重建的质量。
本文为了探索如何高效且高保真的进行 talking portrait 合成,作者基于之前的工作提出了自己观察到的一个点:
- 不同的 spatial region 对 talking portrait 的贡献是不同的
- volumetric rendering 时:由于只有 surface region 对 head 的表达是有贡献的,其他 spatial region 是没有贡献的,为了高效训练其实是可以被裁剪掉的
- 不同的脸部区域和声音特征的联系是不同的,且和本人的说话习惯有很大的关系
- 所以,作者直接使用不同区域给不同的贡献的思路来指导 talking portrait 建模,并且提出了 Efficient Region-aware talking portrait NeRF (ER-NeRF) 框架来建立高效且高保真的 talking portrait 合成。
本文主要基于 RAD-NeRF 的问题:
- 虽然 RAD-NeRF 使用 Instant-NGP 来表达 talking portrait 并且实现了快速的推理,但当建模 3D dynamic talking head 时,其渲染质量和收敛都不太好,主要由于 hash collisions 的问题
本文怎么解决这个问题的:
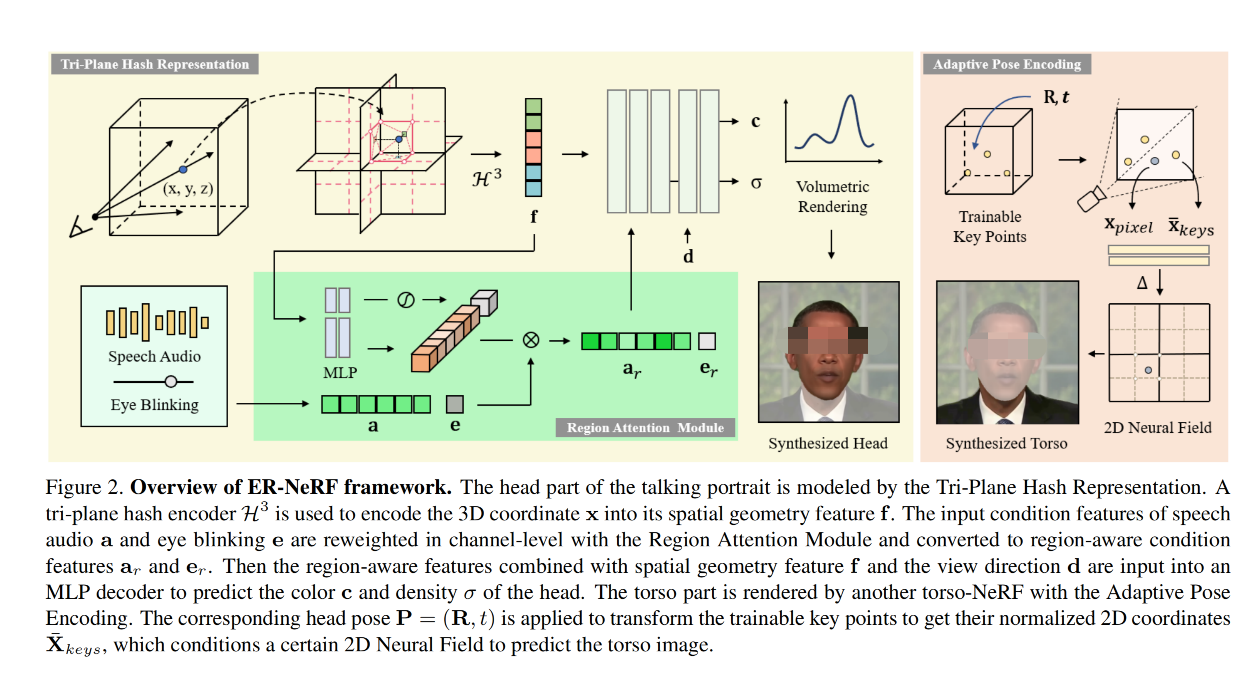
- 本文作者引入了 Tri-Plane Hash Representation,使用 NeRF-based tri-plane decomposition 将 3D 空间分解为三个正交面,通过分解,所以空间区域都被压缩到了 2D 平面上,所以只会在低维子空间出现 hash collision,且数量上减少了很多。因此,噪声就更少了,能让网络更关注处理声音特征,重建出更准确的 head 和更细致的运动系数
hash collision:
-
哈希碰撞(Hash Collision)是指两个不同的输入值通过同一个哈希函数计算后,得到相同的输出结果。这种现象在理论上是可能发生的,因为哈希函数通常将无限大或者非常大的输入空间映射到有限的输出空间。
-
举个例子来说,假设我们有一个简单的哈希函数,它只是将输入字符串中所有字符的ASCII值加在一起然后取模1000作为结果。那么字符串"abc"和"cba"就会产生相同的哈希值,这就是一个简单示例。
-
在实际应用中,如密码学或数据检索等场景下,我们通常会选择设计复杂度更高、碰撞概率更低(理想情况下接近于零)的哈希函数。因为一旦发生了碰撞,在某些情况下可能会导致安全问题或者性能问题。
Instant Neural Geometric Primitives (Instant-NGP) 是一种 3D 渲染技术,它使用哈希表来存储和索引每一个立方体网格中的神经网络参数。然而,在处理动态3D模型(如说话头部)时,可能会出现两个或更多不同位置或时间点共享相同哈希值的情况,导致参数混淆和错误。这就是所谓的“哈希碰撞”。
简而言之,“hash collisions”在 这里指当两个或更多独立和动态变化的网格单元被错误地映射到相同哈希值时出现问题,从而影响渲染质量和收敛性。
Grid-based NeRF:
- NeRF(Neural Radiance Fields)是一种用于3D重建的深度学习方法,它通过对三维空间中的点进行颜色和密度建模,从而可以从任何角度渲染出逼真的2D图像。
- Grid-based NeRF 是对传统 NeRF 方法的一种改进。在传统的 NeRF 中,神经网络会为每个 3D 空间中的点分配一个颜色和密度值。然而,这种方法在处理大型场景时可能会遇到内存限制问题。
- Grid-based NeRF 解决了这个问题。它通过将 3D 空间划分成一个网格,并仅在网格顶点上评估神经网络来优化内存使用情况。然后, 通过插值技术得到网格之间任意位置点的颜色和密度值. 这样就可以处理更大规模场景, 同时保持了较高精度.
总结一下主要区别:
- 内存使用:Grid-based NeRF优化了内存使用情况,使其能够处理更大规模场景。
- 计算效率:由于只需在网格顶点上评估神经网络,并利用插值技术获取其他位置信息, Grid-based NeRF提高了计算效率。
- 精确性:尽管采用了简化方式,在许多应用中, Grid-based NeRF还是能够保持较高精确性。
二、方法
2.1 问题设定
给定一系列多视图图像和相机姿态,NeRF 是使用隐函数 F : ( x , d ) → ( c , σ ) F:(\text{x}, \text{d})\to (\text{c},\sigma) F:(x,d)→(c,σ) 来表达静态 3D 场景的:
- x = ( x , y , z ) \text{x}=(x,y,z) x=(x,y,z) 是 3D 空间坐标
- d = ( θ , ϕ ) \text{d}=(\theta, \phi) d=(θ,ϕ) 是观察方向
- c = ( r , g , b ) \text{c}=(r,g,b) c=(r,g,b) 是输出,表示反射看到的颜色
- σ \sigma σ 表示体积密度/透明度
通过从相机中心 o o o 沿着光线 r ( t ) = o + t d r(t) = o + td r(t)=o+td 聚集颜色 c c c,可以计算出穿过该光线的像素的颜色 C ( r ) C(r) C(r)
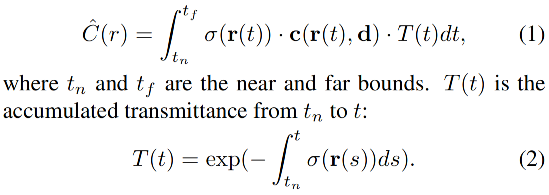
在基于哈希网格的 NeRF [27] 中,使用多分辨率哈希编码器 H H H 来通过其坐标 x \text{x} x 对空间点进行编码。因此,在音频特征 a a a 的前提条件下,基于哈希 NeRF 的 audiodriven talking portrait 合成的基本隐函数如下:
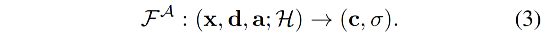
本文和之前的 [19,24,35] 方法的基础设定类似,本文特点如下:
- 只使用一个人的视频来做为训练数据
- 每一帧的相机内部和外部参数都是根据 3DMM 模型估计的头部姿势来计算的
- 音频特征是从预训练的 DeepSpeech [20] 模型中提取出来的。我们还使用了一个现成的像素语义解析的方法,将 head、torso、background 分开以便于各种用途
- 为了加速,分别训练并渲染头部和躯干
在NeRF(神经辐射场)中,"光线"和"颜色"有特殊的含义。
-
“光线”通常指的是从相机出发并穿过像素的路径。在 3D 渲染中,这条路径被用来确定视图中每个像素的颜色。使用一个函数(在 NeRF 中是一个神经网络),我们可以沿着这条光线计算出空间中每一点的颜色和密度。
-
“颜色”则是指通过上述函数计算得到的 RGB 值,即红绿蓝三原色组合而成的颜色。这个函数基于输入光线位置和方向给出结果,结果就是该位置处物体表面发射或反射到相机方向上来的 RGB 颜色值。
2.2 Tri-Plane Hash Representation
Instant-NGP[27] 使用的是一组哈希表来降低特征网格的数量,从而提升表达效率
****** 哈希网格在NERF中的使用主要是为了提高效率 ******
在NERF中,场景被建模为一个连续的 3D 函数,这个函数将每个点(x, y, z)和一个视角 v 映射到颜色和透明度。由于这个函数是连续的,理论上可以在任意精度下对其进行采样。然而,在实际应用中,由于计算资源有限,不能对整个空间进行密集采样。
哈希网格就是一种解决方案。它首先将3D空间划分为许多小块(即"网格"),然后只对这些小块进行采样,并存储结果。当需要查询某点的颜色和透明度时,只需找到该点所在的网格,并使用存储的结果即可。
通过这种方式,哈希网格能够大大降低计算量,并使得渲染速度更快。同时也减少了内存使用量,因为我们不需要保存整个场景所有可能位置上的信息, 只需保存具体采样位置上的信息即可. 这使得NERF能够处理更大、更复杂的场景.
基于该思路,RAD-NeRF[35] 做到了实时、高质量的 talking portrait 的合成,它利用哈希映射来表示多分辨率下头像表面区域的少数部分。然而,通用 3D 哈希网格表示法并不适合我们的任务。因为存在哈希冲突问题。
在 Instant-NGP 中, 哈希处理将 3D 空间中每个位置等同对待, 这增强了它对复杂场景表达能力。然而, 随着采样点数量增加, 哈希冲突数量也会线性增长, 这使得 MLP 解码器解决冲突梯度变得很困难。当重建静态场景时, 这个问题影响不大,但是在进行说话人像合成时,当 MLP 解码器需要同时处理多个音频特征时,问题就变得严重了。
直观来看,如果直接降低每条光线的采样数量的话,最终的结果质量就会越低,所以可以通过避免高维哈希碰撞来解决
在之前的工作 [6] 中已经证明,一个静态的 3D 空间可以使用 3 个 2D tensor 来表示,所以肯定也可以将动态的说话头压缩到几个低维子空间,且信息损失比较小。
因此,本文作者将 3D 空间分解为了 3 个正交的 2D 哈希网格
-
给定一个坐标 x = ( x , y , z ) ∈ R X Y Z \text{x}=(x,y,z) \in R^{XYZ} x=(x,y,z)∈RXYZ,可以分别使用 3 个 2D 多分辨率哈希编码器 H A B : ( a , b ) → f a b A B H^{AB}:(a,b) \to f_{ab}^{AB} HAB:(a,b)→fabAB 来对三个投影坐标分别编码
-
输出 f a b A B ∈ R L F f_{ab}^{AB} \in R^{LF} fabAB∈RLF 是投影坐标 ( a , b ) (a,b) (a,b) 的 plane-level 的几何特征,L 是 level,F 是特征维度
-
H A B H^{AB} HAB 表示 plane R A B R^{AB} RAB 上的哈希编码器
-
然后将三个平面的编码结果进行 concat,得到最终的几何特征 f g ∈ R 3 × L F f_g \in R^{3 \times LF} fg∈R3×LF
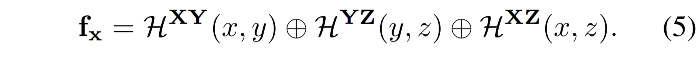
本文提出的这种分解形式到底能带来什么效果:减低哈希碰撞,因为现在的哈希碰撞只会出现在 2D planes
- 假设 3D 时发生哈希碰撞数量为 O ( R 2 N ) O(R^2N) O(R2N), R 2 R^2 R2 是 target pixel 的数量,N 是采样数量
- 则分解后哈希碰撞的数量降低为 O ( R 2 + 2 R N ) O(R^2+2RN) O(R2+2RN)
- RAD-NeRF 中的一般情况 N=16, R ≈ 256,则这样就可以在同样模型大小的情况下降低约 5x 的哈希碰撞,降低后,能够让 MLP decoder 更加关注处理声音特征,提升收敛速度和渲染的效果。
整体的 Head 表达:
MLP 的输入是 x \text{x} x、view direction d d d、dynamic condition feature set D D D(包括声音特征)
tri-plane 哈希表达如下:
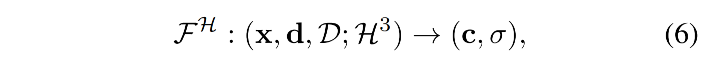

2.3 Region Attention Module

已知音频是动态条件,所以对整个 portrait 的影响肯定是不均等的,所以,为了生成自然的面部运动,很重要的一点是学习这些动态条件是如何影响面部不同位置的。
之前的工作[19,24,42] 忽略了这一点,并且使用昂贵的方法来隐式的学习其相关性
作者通过使用哈希编码器中的多分辨率区域信息,引入了一个轻量级的 region attention 机制,来显式的获得动态特征(声音)和不同面部区域的关系。
Region Attention Mechanism:
- 有一个 attention step 来计算 attention vector
- 有一个 cross-model channel attention 来 reweighting
我们的目标是为了将 dynamic condition feature(声音)和多分辨率几何特征 f x ∈ R N f_x \in R^N fx∈RN 联系起来,但多分辨率的特征是使用 concat 连接的,在 encoding 时没有直接的信息流
为 加强 f x f_x fx 的不同 level 之间的信息交换,并通过 attention vector 来区分出 audio 对每个 region 的重要性,作者使用 2 层 MLP 来捕捉空间的全局上下文信息。这个 MLP 也可以被表达成 external attention mechanism [18] 的形式,对于每个有两个额外的记忆单元 M k M_k Mk 和 M v M_v Mv,分别用于挖掘 level 内的联系 和 self-condition query:
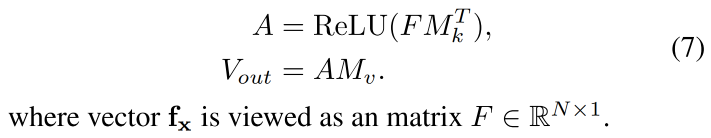
然后,和 [22] 中的 channel attention 一样,作者将 V o u t ∈ R O × 1 V_{out} \in R^{O \times 1} Vout∈RO×1 看做 region attention vector v v v,来 reweight condition feature q ∈ R O q \in R^O q∈RO 的所有 channel
最终的输出向量为:(下面的操作为 Hadamard product)
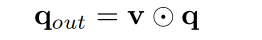
每个通道的产生的区域感知特征 q o u t q_{out} qout 与 x 所在的层次化区域有关,因为 region-aware 向量 v 包含了空间的信息丰富的多分辨率表示。因此,多分辨率空间区域可以决定应保留或增强 q 中哪部分信息。
Speech Audio:
对于声音信号,给定一个 query coordinate x \text{x} x 和一个声音特征 a ∈ R A a \in R^{A} a∈RA
-
首先,使用 tri-plane hash encoder H 3 H^3 H3 计算 x 的几何特征
-
然后,将得到的几何特征输入 2 层 MLP 来为 audio 生成 region attention vector v a , x ∈ R A v_{a, x} \in R^A va,x∈RA,该特征和 A 的 channel 数量相同
-
接着,将 channel-wise attention 用于 a a a
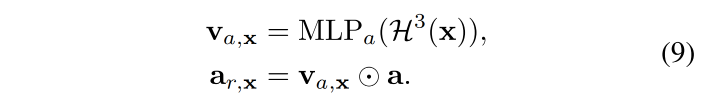
在训练过程中,对于随音频变化的区域,attention vector v a , x v_{a, x} va,x 被优化以更好地利用音频特征 a a a。相反,对于静态部分,音频条件被视为噪声,并且 v a , x v_{a, x} va,x 将成为零向量以帮助去除无用信息。
Eye Blinking:
作者同样做了对眨眼的控制,作者使用一个一维向量 e e e 来描述眨眼的动作
眨眼的 region attention vector v e ∈ R 1 v_e \in R^1 ve∈R1 是使用 sigmoid 层得到的:
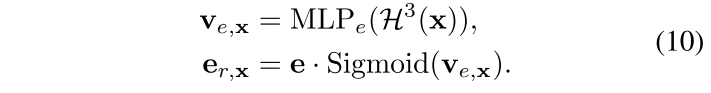
- e r , x e_{r,x} er,x 是根据几何位置对 v e , x v_{e,x} ve,x 的缩放得到的
- 在眼睛区域, e r , x e_{r,x} er,x 会显著影响外观特征,所以要尽可能的接近于 e e e 来最大化其作用
- 在其他区域, e r , x e_{r,x} er,x 会趋近于 0 以降低影响
2.4 训练细节
1、Adaptive Pose Encoding
为了解决头部与躯干的分离问题,作者在以前的工作[35, 43]基础上进行了改进,没有直接使用整个图像或姿态矩阵作为条件,而是将头部姿态的复杂变换映射到几个具有更清晰位置信息的关键点坐标中,并引导 torso-NeRF 从这些坐标中学习隐式躯干姿态。
编码过程:
- 首先,在 3D 规范空间中初始化 N 个点,这些点具有可训练的齐次坐标 X k e y s ∈ R 4 × N X_{keys} \in R^{4 \times N} Xkeys∈R4×N
- 然后,应用头部姿势 P = ( R , t ) P = (R, t) P=(R,t) 来转换关键点 X ^ k e y s = P − 1 X k e y s \hat{X}_{keys} = P^{−1} X_{keys} X^keys=P−1Xkeys
- 接着,将 X ^ k e y s \hat{X}_{keys} X^keys 投影到图像平面上,并得到最终编码结果 2D 坐标 X ‾ k e y s ∈ R 2 × N \overline{X}_{keys} \in R^{2 \times N} Xkeys∈R2×N,会用于条件化 torson-NeRF
- 此外,作者在这里使用 N = 3 和一个 2D 可变形神经场[35] 来渲染 torso 的像素级颜色。
2、Coarse-to-Fine Optimization
作者使用了两阶段的训练方式:
-
coarse stage:作者使用原始 NeRF 的方式,使用 MSE loss 来衡量图像 I I I 预测 color C ^ ( r ) \hat{C}(r) C^(r) 和真实 C ( r ) C(r) C(r) 的差距:
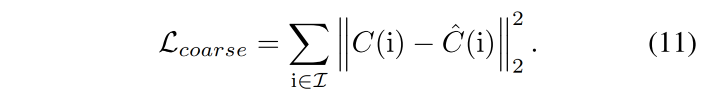
-
fine stage:由于 MSE loss 在优化细节上表现不太好,所以作者还使用了 LPIPS loss[49] ,即从原图中随机采样一组 patch P P P ,然后使用下面的方式结合两个 loss
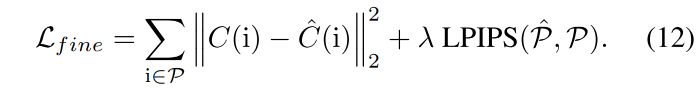
三、效果
3.1 实验设定
1、数据集
作者使用的数据集和 [19, 24, 29] 中使用的一样,都是可下载的开放视频,作者收集了 4 个 high-definition speaking video(高清晰度的),长度大约 6500 frames(in 25 FPS),原始视频都被 resize 到 512x512,然后使用 DeepSpeech model 来抽取 audio feature
2、对比基准
作者对比:
- 同系列的 one-shot person-specific model,包括 Wav2Lip [28], PC-AVS [51], NVP [36], LSP [25] 和 SynObama [34]
- end-to-end NeRF-based models: ADNeRF [19], SSP-NeRF, 和 RAD-NeRF [24]
3、实验细节
Head:
- corse stage head part:100000 iters
- fine stage head part:25000 iters
- 在每个 iter:随机从一个图像中采样 25 6 2 256^2 2562 rays
- 每个哈希 encoder 的 L = 14 , F = 1 L=14,F=1 L=14,F=1,分辨率从 64 到 512
Torso:
- load head 模型然后继续训练 100000 iters
优化器:AdamW
学习率:
- hash encoder:0.01
- 其他:0.001
控制眨眼:
- 使用 AU45[13] 来描述方向和动作
训练时间:
- 单卡 3080Ti,head 和 torso 训练共需要 2 hours 左右
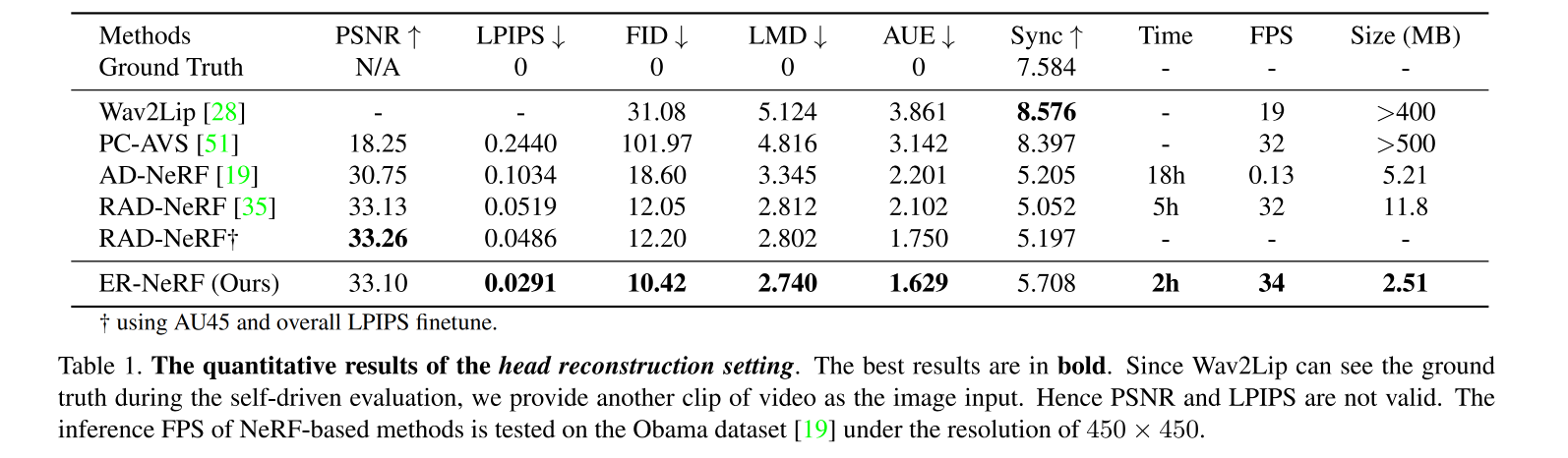
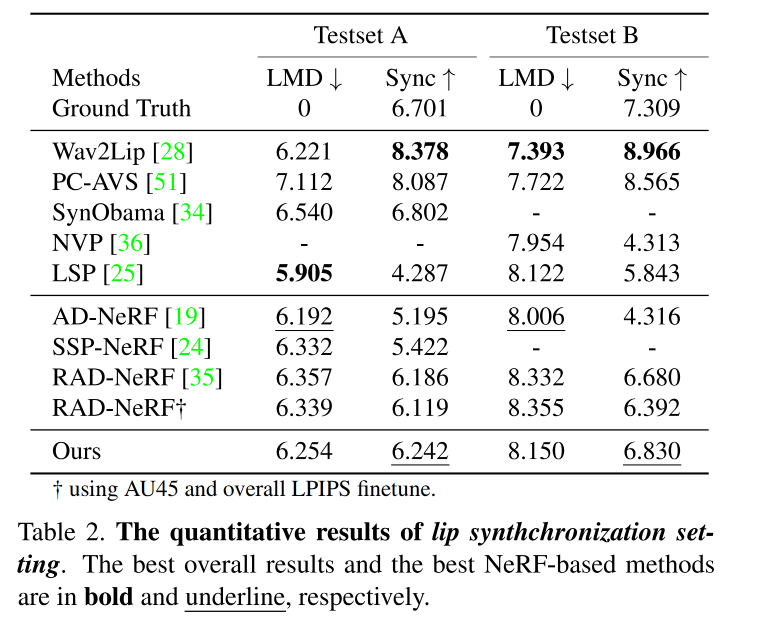
3.2 定量对比
- PSNR:Peak Signal-to-Noise Ratio,衡量整个图像的质量
- LPIPS: Learned Perceptual Image Patch Similarity,衡量细节质量,LPIPS 在训练中也使用了,训练中还引入了 feature-based loss
Fréchet Inception Distance (FID) 来评估图像质量 - LMD:landmark distance,衡量 lip synchronization
- Sync:SyncNet confidence score,衡量 lip synchronization
- AUE:action units error,衡量 face motion accuracy
在定量对比中,比较关注的是 head 的合成质量,所以,对比主要分为如下两部分设置:
- head 重构对比设置:将每个 video 分为 training 和 testing set 来衡量 head 重构的质量。作者使用收集到的数据集,并分为训练和测试
- lip 同步对比设置:作者使用未见过的音频来驱动所有方法,从而对比音唇同步的效果。作者使用 NVP 和 SynObama 的两个 audio ,分别命名为 Testset A 和 Testset B
对比结果:
3.3 定性对比

3.4 User study

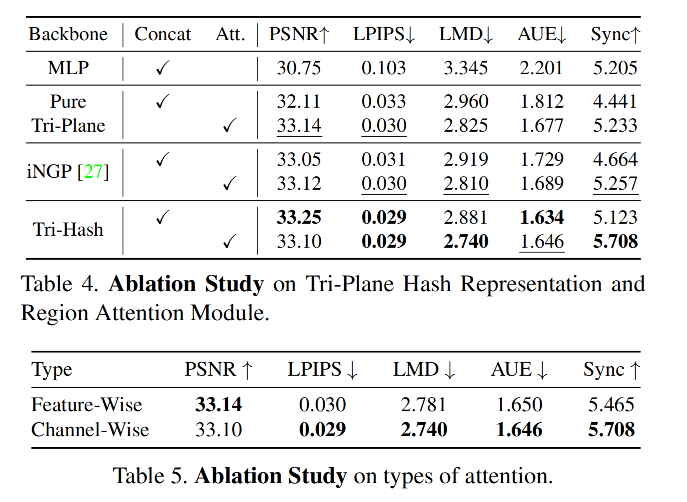
3.5 消融实验
四、代码
4.1 视频数据预处理
python data_utils/process.py
处理后得到的数据结构如下:
./data/<ID>├──<ID>.mp4 # original video├──ori_imgs # original images from video│ ├──0.jpg│ ├──0.lms # 2D landmarks│ ├──...├──gt_imgs # ground truth images (static background)│ ├──0.jpg│ ├──...├──parsing # semantic segmentation│ ├──0.png│ ├──...├──torso_imgs # inpainted torso images│ ├──0.png│ ├──...├──aud.wav # original audio ├──aud_hu.npy # audio features (hubert)├──aud.npy # audio features (deepspeech)├──bc.jpg # default background├──track_params.pt # raw head tracking results├──transforms_train.json # head poses (train split)├──transforms_val.json # head poses (test split)
1、提取声音
def extract_audio(path, out_path, sample_rate=16000):print(f'[INFO] ===== extract audio from {path} to {out_path} =====')cmd = f'ffmpeg -i {path} -f wav -ar {sample_rate} {out_path}'os.system(cmd)print(f'[INFO] ===== extracted audio =====')
主要使用 ffmpeg 来提取声音,一般方法是:
ffmpeg -i obama.mp4 -f wav -ar 16000 aud.wav
一般音频的采样频率都使用的是 16000Hz,主要有以下几个原因:
- 人类听觉范围:人类的听觉频率范围大约在 20Hz 到 20000 Hz。然而,大部分语言中的重要信息都包含在低频区域,一般不会超过 8000Hz。根据奈奎斯特定理(Nyquist-Shannon theorem),为了避免混叠现象并能完整地重建信号,采样频率应该至少是信号最高频率的两倍。所以 16000Hz 已经足够捕获大部分语音信息。
- 计算资源和存储空间:更高的采样率虽然可以提供更多细节,但也意味着需要更多的计算资源和存储空间。对于许多应用来说,并不需要超过 16kHz 的采样率。
- 与标准化相符合:很多历史上和现代的电话系统使用 8kHz 或 16kHz 作为标准采样率,这使得 16kHz 成为了一种广泛接受并使用的标准。
2、提取声音特征
文中说提取声音特征使用的 deepspeech,github repo 中还提供了使用 hubert 的方法,具体修改 extract_audio_features 函数中的参数即可,如果使用 hubert 方法,就会生成对应的 aud_hu.npy 文件,作为提前提取的声音特征,后续用于训练和推理。
def extract_audio_features(path, mode='wav2vec'):print(f'[INFO] ===== extract audio labels for {path} =====')if mode == 'wav2vec':cmd = f'python nerf/asr.py --wav {path} --save_feats'elif mode == 'deepspeech': # deepspeechcmd = f'python data_utils/deepspeech_features/extract_ds_features.py --input {path}'else:cmd = f'python hubert.py --wav {path}'os.system(cmd)print(f'[INFO] ===== extracted audio labels =====')
3、原图抽帧
def extract_images(path, out_path, fps=25):print(f'[INFO] ===== extract images from {path} to {out_path} =====')cmd = f'ffmpeg -i {path} -vf fps={fps} -qmin 1 -q:v 1 -start_number 0 {os.path.join(out_path, "%d.jpg")}'os.system(cmd)print(f'[INFO] ===== extracted images =====')
上面的代码就是对输入视频以 25 帧来抽帧,然后保存,也就是每秒提取 25 帧图像
4、抽取语义分割结果
是继承了 AD-NeRF 中的操作过程:https://github.com/YudongGuo/AD-NeRF/
找了一圈发现应该最初是基于这个仓库的代码:https://github.com/zllrunning/face-parsing.PyTorch/blob/master/evaluate.py
def extract_semantics(ori_imgs_dir, parsing_dir):print(f'[INFO] ===== extract semantics from {ori_imgs_dir} to {parsing_dir} =====')cmd = f'python data_utils/face_parsing/test.py --respath={parsing_dir} --imgpath={ori_imgs_dir}'os.system(cmd)print(f'[INFO] ===== extracted semantics =====')
使用的分割网络是 19 类 BiSeNet ,主要用来进行目标区域的分割,BiSeNet 之所以被广泛使用,原因主要有以下几点:
- 高效性能: BiSeNet由两个路径组成:一个是用于获取丰富的高级语义信息的上下文路径;另一个是用于捕获精细视觉细节信息的空间路径。这两条路径共同工作,使得BiSeNet能够在保证准确性的同时提供实时性能。
- 平衡速度和精度: BiSeNet通过其独特结构,在速度和精度之间达到了良好平衡。这对于需要快速并且准确地进行人脸解析或者其他分割任务(如NeRF中)非常重要。
- 适应不同复杂场景:由于其强大的学习能力和灵活性,BiSeNet可以很好地处理各种复杂场景,并且具有很好的鲁棒性。
- 易于集成:相比其他一些复杂模型, BiSeNet更加简单易懂, 易集成进现有系统.
在人脸解析中,BiSeNet常用于识别和标注人脸的不同部位。
在这里:罗列了分割的类别,0 是背景
atts = ['background', 'skin', 'l_brow', 'r_brow', 'l_eye', 'r_eye', 'eye_g', 'l_ear', 'r_ear', 'ear_r','nose', 'mouth', 'u_lip', 'l_lip', 'neck', 'neck_l', 'cloth', 'hair', 'hat']
分割后的示例如下图:

对分割后的 19 类结果,在这里做了 3 大部分整合,将面部、头发、帽子整合到一个部分,颈部为一个部分,衣服为一个部分:
for pi in range(1, 14): # 'skin', 'l_brow', 'r_brow', 'l_eye', 'r_eye', 'eye_g', 'l_ear', 'r_ear', 'ear_r', 'nose', 'mouth', 'u_lip', 'l_lip'index = np.where(vis_parsing_anno == pi)vis_parsing_anno_color[index[0], index[1], :] = np.array([255, 0, 0]) # blue:面部for pi in range(14, 16): # 'neck', 'neck_l'index = np.where(vis_parsing_anno == pi)vis_parsing_anno_color[index[0], index[1], :] = np.array([0, 255, 0]) # green:颈部for pi in range(16, 17): # 'cloth'index = np.where(vis_parsing_anno == pi)vis_parsing_anno_color[index[0], index[1], :] = np.array([0, 0, 255]) # red:衣服for pi in range(17, num_of_class+1): # 'hair', 'hat'index = np.where(vis_parsing_anno == pi)vis_parsing_anno_color[index[0], index[1], :] = np.array([255, 0, 0]) # blue:头发、帽子

5、抽取背景
背景区域可以从 parsing 结果中提取,当像素值为 [255,255,255] 时,该像素点就是背景
然后使用最近邻的方式,填补背景区域的像素,具体比较复杂,没细看

def extract_background(base_dir, ori_imgs_dir):print(f'[INFO] ===== extract background image from {ori_imgs_dir} =====')from sklearn.neighbors import NearestNeighborsimage_paths = glob.glob(os.path.join(ori_imgs_dir, '*.jpg'))# only use 1/20 image_paths image_paths = image_paths[::20]# read one image to get H/Wtmp_image = cv2.imread(image_paths[0], cv2.IMREAD_UNCHANGED) # [H, W, 3]h, w = tmp_image.shape[:2]# nearest neighborsall_xys = np.mgrid[0:h, 0:w].reshape(2, -1).transpose()distss = []for image_path in tqdm.tqdm(image_paths):parse_img = cv2.imread(image_path.replace('ori_imgs', 'parsing').replace('.jpg', '.png'))bg = (parse_img[..., 0] == 255) & (parse_img[..., 1] == 255) & (parse_img[..., 2] == 255)fg_xys = np.stack(np.nonzero(~bg)).transpose(1, 0)nbrs = NearestNeighbors(n_neighbors=1, algorithm='kd_tree').fit(fg_xys)dists, _ = nbrs.kneighbors(all_xys)distss.append(dists)distss = np.stack(distss)max_dist = np.max(distss, 0)max_id = np.argmax(distss, 0)bc_pixs = max_dist > 5bc_pixs_id = np.nonzero(bc_pixs)bc_ids = max_id[bc_pixs]imgs = []num_pixs = distss.shape[1]for image_path in image_paths:img = cv2.imread(image_path)imgs.append(img)imgs = np.stack(imgs).reshape(-1, num_pixs, 3)bc_img = np.zeros((h*w, 3), dtype=np.uint8)bc_img[bc_pixs_id, :] = imgs[bc_ids, bc_pixs_id, :]bc_img = bc_img.reshape(h, w, 3)max_dist = max_dist.reshape(h, w)bc_pixs = max_dist > 5bg_xys = np.stack(np.nonzero(~bc_pixs)).transpose()fg_xys = np.stack(np.nonzero(bc_pixs)).transpose()nbrs = NearestNeighbors(n_neighbors=1, algorithm='kd_tree').fit(fg_xys)distances, indices = nbrs.kneighbors(bg_xys)bg_fg_xys = fg_xys[indices[:, 0]]bc_img[bg_xys[:, 0], bg_xys[:, 1], :] = bc_img[bg_fg_xys[:, 0], bg_fg_xys[:, 1], :]cv2.imwrite(os.path.join(base_dir, 'bc.jpg'), bc_img)print(f'[INFO] ===== extracted background image =====')6、抽取 torso 躯干信息
使用分割结果,将颈部和衣服区域抠出来

7、抽取面部关键点
使用的库:https://github.com/1adrianb/face-alignmen
共抽取 68 个关键点:
- 眼睛:每只眼睛通常有6个关键点,标记出眼角和眼皮轮廓。
- 眉毛:每条眉毛通常有5个关键点,标记出眉毛轮廓。
- 鼻子:鼻子上有9个关键点,包括鼻尖、鼻翼以及鼻梁。
- 嘴巴:嘴巴区域有20个关键点, 标记出嘴唇轮廓以及嘴巴开口。
- 下颌线: 下颌线上共17个关键点, 标记了下颌线的形状。

抽取完成后,会存放到 .lms 文件中
def extract_landmarks(ori_imgs_dir):print(f'[INFO] ===== extract face landmarks from {ori_imgs_dir} =====')import face_alignmenttry:fa = face_alignment.FaceAlignment(face_alignment.LandmarksType._2D, flip_input=False)except:fa = face_alignment.FaceAlignment(face_alignment.LandmarksType.TWO_D, flip_input=False)image_paths = glob.glob(os.path.join(ori_imgs_dir, '*.jpg'))for image_path in tqdm.tqdm(image_paths):input = cv2.imread(image_path, cv2.IMREAD_UNCHANGED) # [H, W, 3]input = cv2.cvtColor(input, cv2.COLOR_BGR2RGB)preds = fa.get_landmarks(input)if len(preds) > 0:lands = preds[0].reshape(-1, 2)[:,:2]np.savetxt(image_path.replace('jpg', 'lms'), lands, '%f')del faprint(f'[INFO] ===== extracted face landmarks =====')
8、人脸追踪
输出为 track_params.pt
包括所有的 head pose 和追踪的信息,也就是 head tracking results
9、获取 transformers_train.json 和 transformers_val.json
{"focal_len": 1100.0,"cx": 225.0,"cy": 225.0,"frames": [{"img_id": 7272,"aud_id": 7272,"transform_matrix": [[0.9878025054931641,0.13286976516246796,-0.081189826130867,-0.04144233837723732],[-0.13447882235050201,0.9908080697059631,-0.014657966792583466,0.0019160490483045578],[0.07849592715501785,0.025397488847374916,0.9965909123420715,0.7656423449516296],[0.0,0.0,0.0,1.0]]}
}
-
“focal_len”:代表了相机的焦距,这是一个测量单位,表示相机镜头和成像传感器之间的距离。在这个例子中,焦距为1100.0。
-
“cx” 和 “cy”:它们分别表示图像中心点在x轴和y轴上的位置。在这个例子中,图像中心位于(225, 225)。
-
“frames”: 这是一个包含多个帧信息的列表。每个帧都有以下内容:
-
“img_id” 和 “aud_id”: 它们分别表示图像ID和音频ID,此处都为7272。
-
“transform_matrix”:这是一个4x4变换矩阵,用于描述从3D世界坐标系到当前帧(即相机坐标系)的变换关系。矩阵内部元素包括旋转、平移等信息:
- 第 1 行至第 3 行前三列主要描述了旋转,它描述了物体在三维空间中如何进行旋转
- 第 1 行至第 3 行最后一列描述了平移,它描述了物体在三维空间中沿着X、Y和Z轴方向分别移动了多少距离。
- 最后一行通常设置为[0, 0, 0, 1]以满足齐次坐标系统要求,在计算机图形学中,我们使用齐次坐标来表示三维空间中的点或向量,并且能够同时处理位移、缩放、旋转等操作。所以一般第四行会设置为[0, 0, 0, 1]。
4.2 训练
训练框架整理如下:

NeRF 训练时输入是一个视频,所以每个人物都需要训练才能实现对该人物的输出。
这里以 github 链接中给的 Obama.mp4 为例来说明训练过程
# 第一步:不微调嘴唇
python main.py data/obama/ --workspace trial_obama/ -O --iters 100000
# 第二步:微调嘴唇
python main.py data/obama/ --workspace trial_obama/ -O --iters 125000 --finetune_lips --patch_size 32
# 第三步:在第二步训练好的基础上,训练torso
python main.py data/obama/ --workspace trial_obama_torso/ -O --torso --head_ckpt <head>.pth --iters 200000
训练时的超参数:
Namespace(H=450, O=True, W=450, amb_aud_loss=1, amb_dim=2, amb_eye_loss=1, asr=False, asr_model='hubert', asr_play=False, asr_save_feats=False, asr_wav='', att=2, aud='', bg_img='', bound=1, ckpt='latest', color_space='srgb', cuda_ray=False, data_range=[0, -1], density_thresh=10, density_thresh_torso=0.01, dt_gamma=0.00390625, emb=False, exp_eye=False, fbg=False, finetune_lips=True, fix_eye=-1, fovy=21.24, fp16=False, fps=50, gui=False, head_ckpt='', ind_dim=4, ind_dim_torso=8, ind_num=10000, init_lips=False, iters=125000, l=10, lambda_amb=0.0001, lr=0.01, lr_net=0.001, m=50, max_ray_batch=4096, max_spp=1, max_steps=16, min_near=0.05, num_rays=65536, num_steps=16, offset=[0, 0, 0], part=False, part2=False, patch_size=32, path='data/obama/', preload=0, r=10, radius=3.35, scale=4, seed=0, smooth_eye=False, smooth_lips=False, smooth_path=False, smooth_path_window=7, test=False, test_train=False, torso=False, torso_shrink=0.8, train_camera=False, unc_loss=1, update_extra_interval=16, upsample_steps=0, warmup_step=10000, workspace='trial_obama')
'--num_rays', type=int, default=4096 * 16 # 表示训练时每个图片中采样的 ray 的个数
数据预处理:NeRFDataset provider.py line 312
- eye_blink:au.csv 中的
['AU45_r'],shape=(frame-1,),也就是每一帧图片一个眨眼参数,是0-1之间的值,[0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ,0. , 0. , 0. , 0. , 0. , 0.05, 0.15, 0.19, 0.13, 0.03, 0. ...]) - head pose 转换到 ngp 的表达中:每帧图片对应一个 [4,4] 大小的变换矩阵,表示 head pose 的旋转(左上3x3矩阵)和平移(第四列前三个值)
def nerf_matrix_to_ngp(pose, scale=0.33, offset=[0, 0, 0]):new_pose = np.array([[pose[1, 0], -pose[1, 1], -pose[1, 2], pose[1, 3] * scale + offset[0]],[pose[2, 0], -pose[2, 1], -pose[2, 2], pose[2, 3] * scale + offset[1]],[pose[0, 0], -pose[0, 1], -pose[0, 2], pose[0, 3] * scale + offset[2]],[0, 0, 0, 1],], dtype=np.float32)return new_pose# NeRF
array([[ 9.9951243e-01, -3.1217920e-02, 5.4783188e-04, 7.4655092e-03],[ 3.0509701e-02, 9.8026478e-01, 1.9532026e-01, 2.8802392e-01],[-6.6345125e-03, -1.9520833e-01, 9.8073936e-01, 1.4707624e+00],[ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00, 1.0000000e+00]],dtype=float32)
# NGP
array([[ 3.0509701e-02, -9.8026478e-01, -1.9532026e-01, 1.1520957e+00],[-6.6345125e-03, 1.9520833e-01, -9.8073936e-01, 5.8830495e+00],[ 9.9951243e-01, 3.1217920e-02, -5.4783188e-04, 2.9862037e-02],[ 0.0000000e+00, 0.0000000e+00, 0.0000000e+00, 1.0000000e+00]],dtype=float32)
- 提取每帧对应的声音特征,假设使用 hubert 提取到的声音特征为 [222, 1024, 2],则提取一帧为 [1024, 2]
- 基于 face_alignment 得到的 lms 人脸关键点,提取人脸的全脸区域 face_rect 和下半脸区域 lhalf_rect
- 提取眼睛眨眼强度:基于 openface 提取的 au.npy 来提取,au_blink.shape=221,提取到对应帧的眼睛眨眼情况即可
area = au_blink[f['img_id']],如果为 0 表示不眨眼,使用 openface 得到的 “AU45_r” 代表的是面部动作单元45(Blink)的强度。这个指标通常用于衡量眼睛闭合的程度。"_r"后缀表示这是一个连续型变量,其值范围从0到5,0表示该动作单元未被激活,5表示该动作单元完全激活。总的来说,“AU45_r”可以帮助我们了解一个人是否在眨眼以及眨眼的强度。当’AU45_r’接近或等于5时,可以理解为眼睛完全闭合或者处于强烈的眨眼状态。然而,在实际应用中,“完全闭合”的具体阈值可能会根据具体情境和需求有所不同。值为0通常表示眼睛处于完全打开的状态,也就是说没有眨眼。 - 提取眼睛区域,这个区域是两个眼睛框到一起的区域
- 提取嘴唇区域,因为会涉及到 finetune_lips,所以会需要嘴唇区域
- 提取焦距长度
['focal_len'] - 提取图像中心
[cx, cy] - 构建发射 ray 的坐标网格,维度为 [1, 65536, 2],坐标是从 [-1,1] 的,65536=256*256
- 提取有效区域的平移和旋转,(训练时是 face_rect)的坐标 [144, 184, 105, 145],然后计算有效区域的面积为 1600,返回有效区域的 pose 平移量 rays_o 和 旋转量 rays_d
- 提取全脸、下半脸、眼部的 mask:是 true 和 false 的布尔值,大小都是 [1,1600] 的矩阵
- 将 torso 图片和背景图片进行合成,合成一张图片,如果训练 torso 则只使用背景图作为背景,如果不训练 torso 的话,则要使用 torso 和背景合成的图作为背景
- 提取原图中的有效区域 image 、背景的有效区域 bg_img、发射位置有效区域 bg_coords、大小都是 [1,1600,3]
# self.bg_coords 原始 65536 个位置的网格坐标示例
tensor([[[-1.0000, -1.0000],[-1.0000, -0.9922],[-1.0000, -0.9843],...,[ 1.0000, 0.9843],[ 1.0000, 0.9922],[ 1.0000, 1.0000]]], device='cuda:0')
训练全图:
# 训练全图时,全图的点都是有效区域,256*256=65536
python main.py data/obama/ --workspace trial_obama/ -O --iters 100000
渲染:
- 第一步:获得每个 ray 上的每个采样点的 rgb 颜色,共 65536 个 ray,共 65536*16 个采样点
- 第二步:汇总每个 ray 上所有采样点,得到每个 ray 的颜色
微调嘴唇:
# 加上 --finetune_lips 就是只有嘴唇区域为有效区域,此处有效区域为 [144, 184, 105, 145],共 1600 个像素点
python main.py data/obama/ --workspace trial_obama/ -O --iters 125000 --finetune_lips --patch_size 32
渲染:
渲染的第一步:得到 rgb 颜色,这里的 1600 是有效嘴唇的区域,下面的所有描述都是按照 finetune lip 的过程来描述的。
-
使用 raymarching 方法来渲染,生成预测的点的 rgb,输入为有效区域的:
- ray_o :相机在世界空间中的位置,也就是 ray 的出发点,所有 1600 个 ray 的出发点都是一样的,所以 ray_o 是每行都一样的 [1,1600,3] 的向量,每行都来自 pose 的最后一列的前3 个值
- 从 ray_o 出发的 1600 个光线的方向 ray_d,先将图像中的位置转换到世界坐标系,就得到了这 1600 个位置在世界坐标系中的位置 [1,1600,3],然后将这些位置和 pose 参数中的旋转方向矩阵相乘,得到了发射到每个位置的 ray 的方向 [1,1600,3]
- 声音特征 auds
- ray 网格坐标 bg_coords
-
使用
raymarching.near_far_from_aabb获取距离最近和最远的位置,也就是 near 和 far,确定这个范围的原因是为了确定渲染范围,每个位置都会有一个渲染范围,[1600] 大小,如果没有设置合适的开始和结束位置,则可能会错过一些重要信息,比如在结束点之后还有未被考虑进去但对结果影响很大的对象;反之如果设置得过远,则可能会增加不必要计算量,并且由于深度值变大导致精度下降。 -
对声音编码,得到 [1,32] 大小的声音特征
-
设置每个 ray 上采样点个数为 16,则 所有采样点共 1600*16=25600,得到这些采样点的:
- 位置坐标 xyzs:在raymarching中,得到的xyzs通常指的是一个包含了射线沿其路径上所有采样点坐标的数组或列表。每个采样点的坐标都由三个值(x, y, z)组成,代表了这个点在三维空间中的位置。
- 方向 dirs:[25600, 3],每个射线上的所有点的方向都是一样的,射线通常由一个起点和一个方向来定义。起点就是你从哪里开始“发射”这个射线,而方向则决定了这个射线朝哪个方向前进。因此,在大多数情况下,dirs是一个包含三个元素(对应于x、y、z轴)的矢量(或者说数组),用来表示这个射线的方向。
- deltas
- delta_t: 这是步长或者说增量时间。在Raymarching中,我们需要逐步推进射线以找到与场景物体的交点。每一次迭代后,射线前进的距离就是这个delta_t。这个值通常根据场景和所需的精度来设定
- ray_t:这是当前射线沿着自己方向行进过程中经过的总距离。开始时,它通常被设置为0(表示从射线起点开始)。然后,在每次迭代中都会增加上述提到的delta_t, 直到找到与物体表面交点或者超出了最大距离限制)
- rays:[1600,3], 表示每个 ray 的 index, point_offset, point_count
- index: 这个通常是指射线的索引号,如果你同时处理多条射线(例如在GPU并行计算中),每条射线都会有一个唯一的索引号,以便于跟踪和管理。
- point_offset: 这个通常用于表示当前处理到的点在整个点序列(或者叫做缓冲区)中的起始位置。这样,在处理完当前步骤后,你可以直接从这个偏移量开始读取或者写入下一步需要使用到的数据。
- point_count: 这个用于表示当前射线已经采样了多少次或者说已经生成了多少个点。这对于判断是否达到了最大迭代次数、是否需要终止迭代等问题非常有用。
-
将上面得到的变量送入模型迭代训练,求密度,为这 25600 个位置每个位置都生成一个密度
- 对 xyzs 进行分解,分解为 xy,yz,xz,例如 [-0.2275, 0.4829, -0.0135] 就被分解为 [-0.2275, 0.4829],[ 0.4829, -0.0135],[-0.2275, -0.0135],维度都为[25600,2]
- 然后对分解后的坐标分别进行 encoder,得到 enc_x,总共进行 3 次,每个 plane 得到的特征为 [25600,12],三个 concat 后为 [25600, 36],
GridEncoder: input_dim=2 num_levels=12 level_dim=1 resolution=64 -> 512 per_level_scale=1.2081 params=(163584, 1) gridtype=hash align_corners=False - 使用分解后的位置特征对语音和眨眼进行加权,分别对 enc_x 和 enc_a 求相关性,对 enc_x 和 eye feature 求相关性,然后将 enc_x 和得到的两组相关性特征 concat,经过 MLP 得到融合后的特征,维度为[25600, 65],第一列取exp作为 sigma,也就是我们要的该采样点的密度,后面所有列作为几何 geo_feat。
- 对方向 d 进行编码,d 维度为 [25600,3],得到 [25600, 16] 的特征 enc_d
- 然后将 geo_feat 和 enc_d 进行 concat,经过 MLP 得到最终的 color 特征
poses:tensor([[[-0.0676, -0.9976, -0.0154, 0.0722],[-0.0063, 0.0158, -0.9999, 6.0399],[ 0.9977, -0.0675, -0.0074, 0.0680],[ 0.0000, 0.0000, 0.0000, 1.0000]]], device='cuda:0')ray_d:tensor([[[-2.6027e-02, -9.9937e-01, -2.4224e-02],[-2.6075e-02, -9.9938e-01, -2.3512e-02],[-2.6124e-02, -9.9940e-01, -2.2799e-02],...,[-5.5563e-02, -9.9846e-01, 2.5730e-04],[-5.5611e-02, -9.9845e-01, 9.6933e-04],[-5.5659e-02, -9.9845e-01, 1.6813e-03]]], device='cuda:0')ray_o:tensor([[[0.0722, 6.0399, 0.0680],[0.0722, 6.0399, 0.0680],[0.0722, 6.0399, 0.0680],...,[0.0722, 6.0399, 0.0680],[0.0722, 6.0399, 0.0680],[0.0722, 6.0399, 0.0680]]], device='cuda:0')
渲染的第二步:对每个 ray 的所有采样点的结果进行组合,从 rgb 颜色得到原图,每个 ray 对应一个特征喽
- 得到每个ray的 weights_sum (像素点的透明度,优化目标是 0/1)、amb_aud_sum、amb_eye_sum、uncertainty_sum,这些值也是要单独优化的,每个使用不同的 loss 来优化,然后对得到的有效区域的 image (也就是预测的 rgb)和真实的 rgb计算 MSE loss
- weights_sum 使用的交叉熵损失,优化的目标是将其优化为 0 或 1,也就是二分布。1-weights_sum 会用于背景颜色的权重,维度为 [1600,1],使用方式为
image = image + (1 - weights_sum).unsqueeze(-1) * bg_color,如果 weights_sum 为 1,则背景失效,前景透明度为0,如果 weights_sum 为 0,则前景和背景相加为最终的结果。 - amb_aud_sum,表示每个 ray 和声音的相关性,脸部之外的地方不应该有相关性,应该是静止的,所以维度为 [1,1600] 的相关性矩阵,amb_aud_sum 会和不是 face_mask 区域的点相乘,也就是如果非 face_mask 区域也有amb_aud_sum响应,则是不希望的,将这部分优化为 0,即让 amb_aud_sum 对非 face_mask 区域不做响应
- amb_eye_sum,表示每个 ray 和眼睛的相关性
- weights_sum 使用的交叉熵损失,优化的目标是将其优化为 0 或 1,也就是二分布。1-weights_sum 会用于背景颜色的权重,维度为 [1600,1],使用方式为
- 如果使用了 finetune_lips 的话,则还要计算 LPIPS loss,权重为 0.01,
loss = loss + 0.01 * self.criterion_lpips_alex(pred_rgb, rgb)
(Pdb) deltas
tensor([[0.0271, 5.5928],[0.0271, 5.6198],[0.0271, 5.6469],...,[0.0271, 5.9320],[0.0271, 5.9591],[0.0271, 5.9861]], device='cuda:0')
(Pdb) xyzs
tensor([[-0.2275, 0.4829, -0.0135],[-0.2289, 0.4559, -0.0139],[-0.2304, 0.4289, -0.0143],...,[-0.2454, 0.1442, -0.0227],[-0.2469, 0.1172, -0.0231],[-0.2483, 0.0902, -0.0235]], device='cuda:0')
(Pdb) rays
tensor([[ 1536, 0, 16],[ 1537, 16, 16],[ 1538, 32, 16],...,[ 1533, 25552, 16],[ 1534, 25568, 16],[ 1535, 25584, 16]], device='cuda:0', dtype=torch.int32)
(Pdb) dirs
tensor([[-0.0538, -0.9984, -0.0146],[-0.0538, -0.9984, -0.0146],[-0.0538, -0.9984, -0.0146],...,[-0.0538, -0.9984, -0.0154],[-0.0538, -0.9984, -0.0154],[-0.0538, -0.9984, -0.0154]], device='cuda:0')
NeRF 网络结构:
NeRFNetwork((audio_net): AudioNet((encoder_conv): Sequential((0): Conv1d(1024, 32, kernel_size=(3,), stride=(2,), padding=(1,))(1): LeakyReLU(negative_slope=0.02, inplace=True)(2): Conv1d(32, 32, kernel_size=(3,), stride=(2,), padding=(1,))(3): LeakyReLU(negative_slope=0.02, inplace=True)(4): Conv1d(32, 64, kernel_size=(3,), stride=(2,), padding=(1,))(5): LeakyReLU(negative_slope=0.02, inplace=True)(6): Conv1d(64, 64, kernel_size=(3,), stride=(2,), padding=(1,))(7): LeakyReLU(negative_slope=0.02, inplace=True))(encoder_fc1): Sequential((0): Linear(in_features=64, out_features=64, bias=True)(1): LeakyReLU(negative_slope=0.02, inplace=True)(2): Linear(in_features=64, out_features=32, bias=True)))(audio_att_net): AudioAttNet((attentionConvNet): Sequential((0): Conv1d(32, 16, kernel_size=(3,), stride=(1,), padding=(1,))(1): LeakyReLU(negative_slope=0.02, inplace=True)(2): Conv1d(16, 8, kernel_size=(3,), stride=(1,), padding=(1,))(3): LeakyReLU(negative_slope=0.02, inplace=True)(4): Conv1d(8, 4, kernel_size=(3,), stride=(1,), padding=(1,))(5): LeakyReLU(negative_slope=0.02, inplace=True)(6): Conv1d(4, 2, kernel_size=(3,), stride=(1,), padding=(1,))(7): LeakyReLU(negative_slope=0.02, inplace=True)(8): Conv1d(2, 1, kernel_size=(3,), stride=(1,), padding=(1,))(9): LeakyReLU(negative_slope=0.02, inplace=True))(attentionNet): Sequential((0): Linear(in_features=8, out_features=8, bias=True)(1): Softmax(dim=1)))(encoder_xy): GridEncoder: input_dim=2 num_levels=12 level_dim=1 resolution=64 -> 512 per_level_scale=1.2081 params=(163584, 1) gridtype=hash align_corners=False(encoder_yz): GridEncoder: input_dim=2 num_levels=12 level_dim=1 resolution=64 -> 512 per_level_scale=1.2081 params=(163584, 1) gridtype=hash align_corners=False(encoder_xz): GridEncoder: input_dim=2 num_levels=12 level_dim=1 resolution=64 -> 512 per_level_scale=1.2081 params=(163584, 1) gridtype=hash align_corners=False(eye_att_net): MLP((net): ModuleList((0): Linear(in_features=36, out_features=16, bias=False)(1): Linear(in_features=16, out_features=1, bias=False)))(sigma_net): MLP((net): ModuleList((0): Linear(in_features=69, out_features=64, bias=False)(1): Linear(in_features=64, out_features=64, bias=False)(2): Linear(in_features=64, out_features=65, bias=False)))(encoder_dir): SHEncoder: input_dim=3 degree=4(color_net): MLP((net): ModuleList((0): Linear(in_features=84, out_features=64, bias=False)(1): Linear(in_features=64, out_features=3, bias=False)))(unc_net): MLP((net): ModuleList((0): Linear(in_features=36, out_features=32, bias=False)(1): Linear(in_features=32, out_features=1, bias=False)))(aud_ch_att_net): MLP((net): ModuleList((0): Linear(in_features=36, out_features=64, bias=False)(1): Linear(in_features=64, out_features=32, bias=False)))
)
原始代码处理上限为 10000 帧:opt.ind_num=10000,如果要处理更长的视频的话,需要将 opt.ind_num 加大
2、训练
ER-NeRF/nerf_triplane/utils.py line723, train_step()
- 使用 raymarching 计算最远位置和最近位置
- 使用
self.encode_audio处理声音特征
4.3 推理
# smooth_path 可以减轻头部抖动
# --test 指定为测试模式
# --test_train 指定使用训练图片的 pose
python main.py data/obama/ --smooth_path --workspace trial_obama/ -O --test --test_train --aud aud_hu.npy
- 第一步,和训练时一样,提取所有需要的参数,包括 rays_o,rays_d,bg_coords,poses,auds,eye 等
- 第二步,使用训练好的模型来逐步进行逐点渲染,每次都对所有 ray 在本次步进位置上渲染得到 xyzx、dirs、deltas
- 第三步,使用训练好的 nerf 模型,来预测每个 ray 对应该步进位置上的的密度、颜色,然后更新有效的 rays,并重复执行第二步和第三步 max_step=16 次
- 第四步,将渲染最后得到每个 ray 对应的位置上的颜色和背景进行组合,得到最终的 image,深度信息也会归一化,维度都为 [1,65536],然后给颜色255就是最终的 rgb 值,深度255是最终的深度值
这篇关于【数字人】6、ER-NeRF | 借助空间分解来实现基于 NeRF 的更高效的数字人生成(ICCV2023)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




