本文主要是介绍浙江大学刘勇教授课题组多项工作收录ICCV2023及近期学术成果汇编,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—>【目标检测和Transformer】交流群
ICCV(International Conference on Computer Vision,国际计算机视觉大会)是计算机领域世界顶级的学术会议之一,每两年举办一届,其论文集代表了计算机视觉领域最新的发展方向和水平,2023年将于今年10月在法国巴黎举行。近期,ICCV 2023公布录用结果,浙江大学控制科学与工程学院刘勇教授课题组共有5篇论文录用,研究方向涉及室内场景重建、图像合成、动作识别、剪枝/量化、3D目标追踪方向。
刘勇教授课题组现已建立一支由研究员、博士后、博士、硕士组成的研究团队,研究方向涉猎全面,在计算机视觉和机器人感知导航领域中取得了丰硕的研究成果。近两个月来,团队还取得了1篇 ACM MM(ACM International Conference on Multimedia,多媒体领域国际会议),5篇 IROS(International Conference on Intelligent Robots and Systems,智能机器人和系统国际会议)和7篇期刊的佳绩,方向涉及室内场景重建、图像合成、图像异常检测、动作识别、剪枝/量化、3D目标追踪、点云全景分割、点云语义场景补全、单目深度估计、大规模集群追逃避碰、激光-惯性SLAM、地理定位、换脸检测、多智能体合作、神经网络加速等。
课题组网站链接:
https://april.zju.edu.cn/our-team/
课题组Github:
https://github.com/APRIL-ZJU
刘勇教授主页:
https://scholar.google.com/citations?user=qYcgBbEAAAAJ
01 ICCV 2023
RICO: Regularizing the Unobservable for Indoor Compositional Reconstruction
通过约束不可见区域实现有效的室内场景解耦重建
作者:李梓彰、吕晓阳、丁缘媛、王蒙蒙、廖依伊、刘勇
通过体渲染带方向距离(SDF)的方式可以实现从二维图片中重建准确的场景隐式三维几何信息,最近的一些工作在此基础上将SDF表示为场景内多物体不同的SDF值,并在体渲染过程中进行筛选,以此实现在多视角掩码输入情况下对不同物体的几何的解耦重建。然而这些方法都只考虑了可见面的有效解耦,在室内场景很多物体都只能从部分视角观察时(如沙发倚靠着墙壁),由于无法从所有方向对SDF场进行约束,在不可见区域的重建效果往往非常差,并影响整体的解耦效果。以此为出发点,本论文引入三种几何先验来约束不可见区域的SDF场。首先,对不可见的背景区域,约束其渲染法向量和深度值在小范围区域内的连续性,防止不可见区域出现空洞或极其不规则的几何属性;在有了较为完善的背景表面后,利用“所有室内场景物体都在背景范围内”这一先验,从逐采样点,以及反向渲染深度的两个角度,分别离散、连续地约束各物体的SDF场,最终实现室内场景的各物体干净的解耦重建效果。所提出的方法在真实的室内场景数据集以及仿真数据集上分别进行了定性、定量的分析,均实现了很强的重建效果提升。
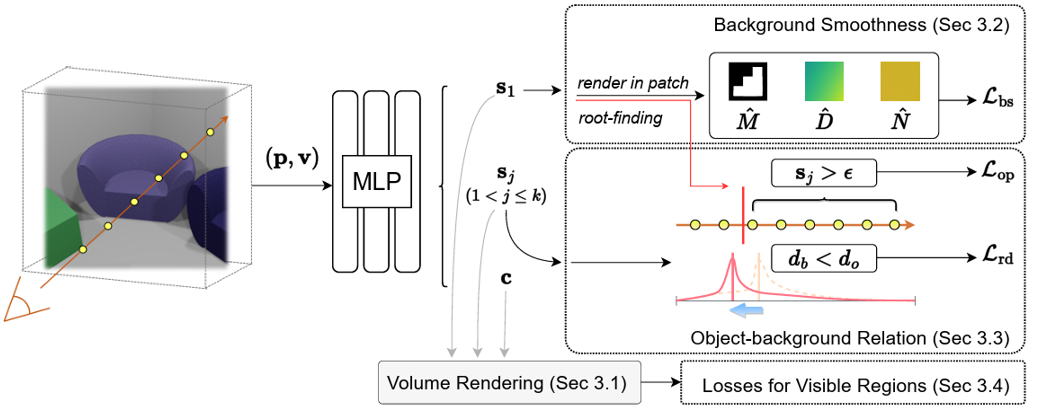
所提出三种约束的总体框架
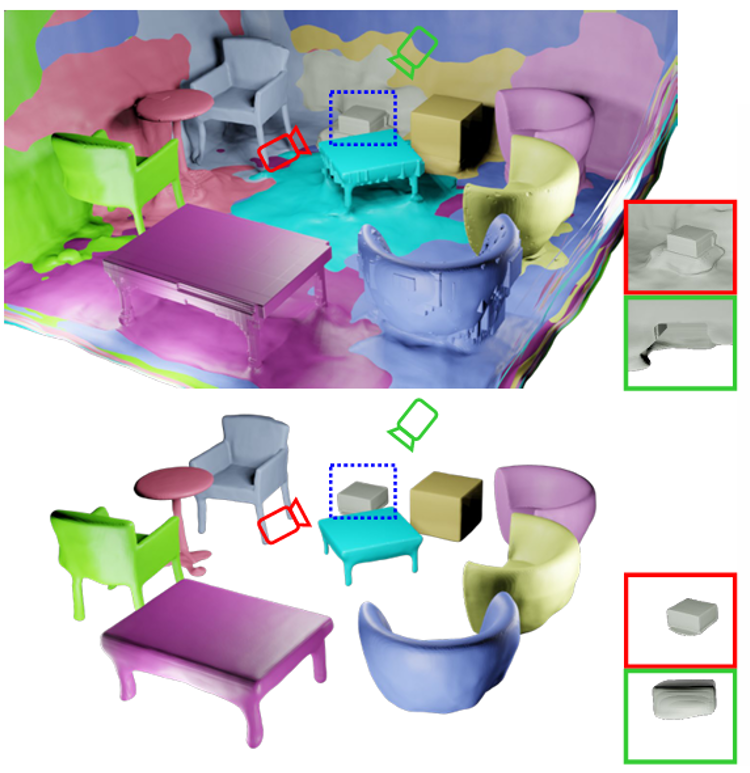
所提出RICO与之前基线方法在室内场景的解耦重建效果对比
02 ICCV 2023
Learning Global-Aware Kernel for Image Harmonization
学习全局感知核的图像和谐化
作者:沈心田、张江宁、陈军、白世鹏、韩玥、王亚彪、汪铖杰、刘勇
论文主要解决图像和谐化方法中对于背景参考信息的注入问题,提出了一种新的基于全局感知动态核的图像和谐化方法,实现对背景信息的综合性平衡考量。针对区域匹配方法导致的背景一致性对待问题,通过学习合成图像前景的动态核实现针对性的和谐化;在和谐化核的预测阶段也设计了联合全局特征的机制,使得动态核能够获取针对局部有效的全局背景信息。该方法基于和谐化核的预测和调制两部分联合机制为图像和谐化提供一种更合理的背景色彩参考基线方法。
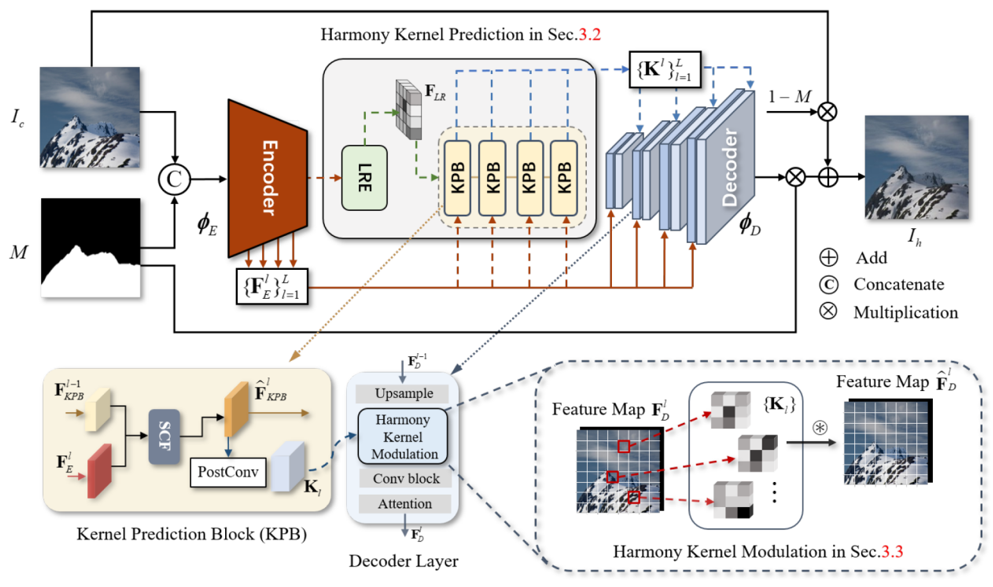
03 ICCV 2023
Boosting Few-Shot Action Recognition with Graph-Guided Hybrid Matching
基于图引导混合匹配机制的小样本动作识别方法
作者:幸家正、王蒙蒙、阮雨迪、陈波帆、郭曜玮、母博宇、戴光、王井东、刘勇
在这项工作中,我们提出了一种新的少样本动作识别框架GgHM,该框架在没有任何数据集或任务偏好的情况下,在相似类别识别方面取得了优异的性能。具体来说,我们通过在类原型构建过程中利用图网络的指导来学习面向任务的特征,显性地优化了特征类内和类间的相关性。此外,我们提出了一种混合类原型匹配策略,该策略利用帧和序列级原型匹配来有效地处理具有不同风格的视频任务。最后,我们提出了可学习的密集时序建模模块来增强视频特征时序表征能力,这有助于为匹配过程建立更坚实的基础。
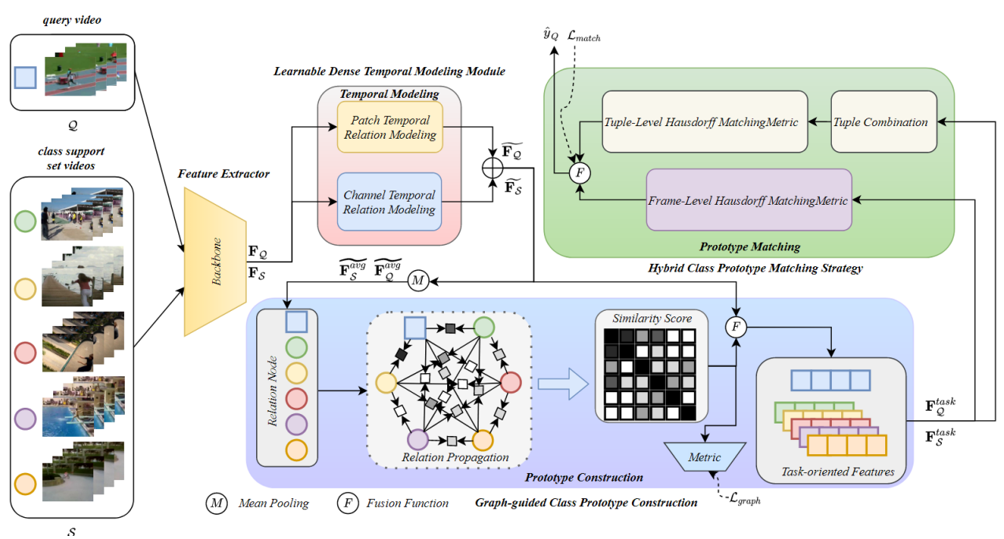
04 ICCV 2023
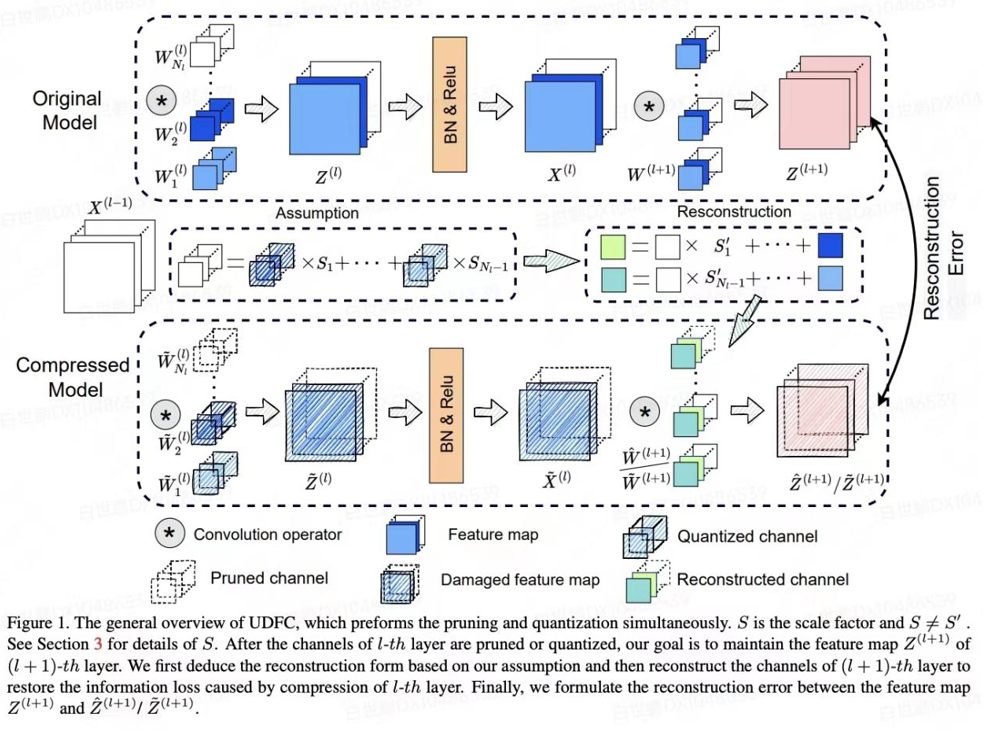
Unified Data-Free Compression: Pruning and Quantization without Fine-Tuning
无数据压缩框架:剪枝和量化
作者:白世鹏、陈军、沈心田、钱一萱、刘勇
论文针对某些场景下数据不可用以及再训练过程繁琐复杂等问题。首次提出一种无需数据以及再训练过程的统一压缩框架,包括模型剪枝和模型量化。通过假设损坏(被修剪或量化)的通道可以用其他通道的线性组合来代替,从而保留原始信息。该方法可以在不使用任何数据的情况下完成量化和剪枝,在8-bit的情况下不损失精度。
05 ICCV 2023
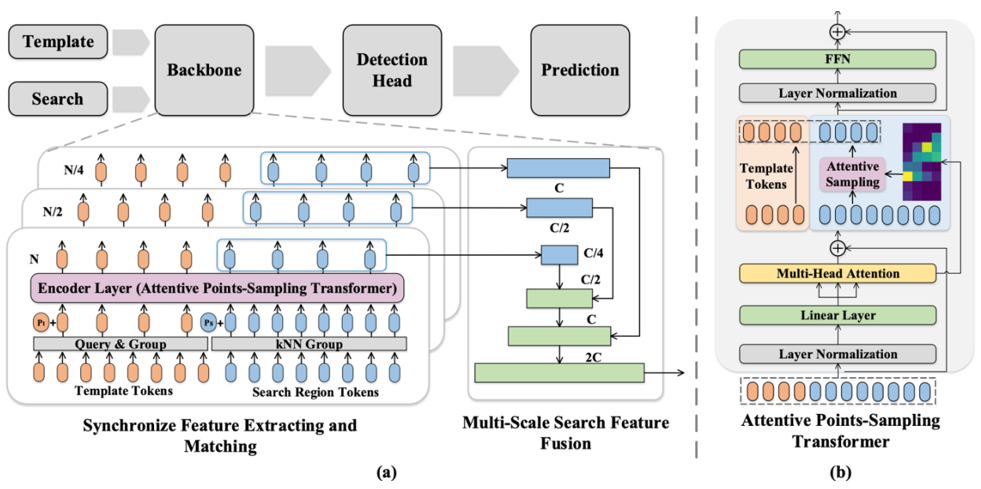
Synchronize Feature Extracting and Matching: A Single Branch Framework for 3D Object Tracking
同步特征提取和匹配:用于 3D 目标追踪的单支网络框架
作者:马特立、王蒙蒙、肖继民、邬惠峰、刘勇
论文针对三维点云单目标追踪场景下目标帧与初始帧需要使用孪生网络进行两次前向运算分别提取特征的问题,提出一种新的基于Transformer的骨干网络结构,在同时提取目标帧与初始帧特征的过程中,能同时做到两种特征的交互。该方法可以避免和之前的方法一样单独设计特征匹配网络来匹配两种特征,从而实现一个骨干网络完成所有工作,保持网络设计的简洁与优雅。同时,与过去的点云降采样方法不同,我们还提出根据自注意力机制的注意力图来进行点云的降采样与特征聚合,从而实现在网络前向过程中提取与目标物体最相关的多尺度特征。
06 ACM MM 2023
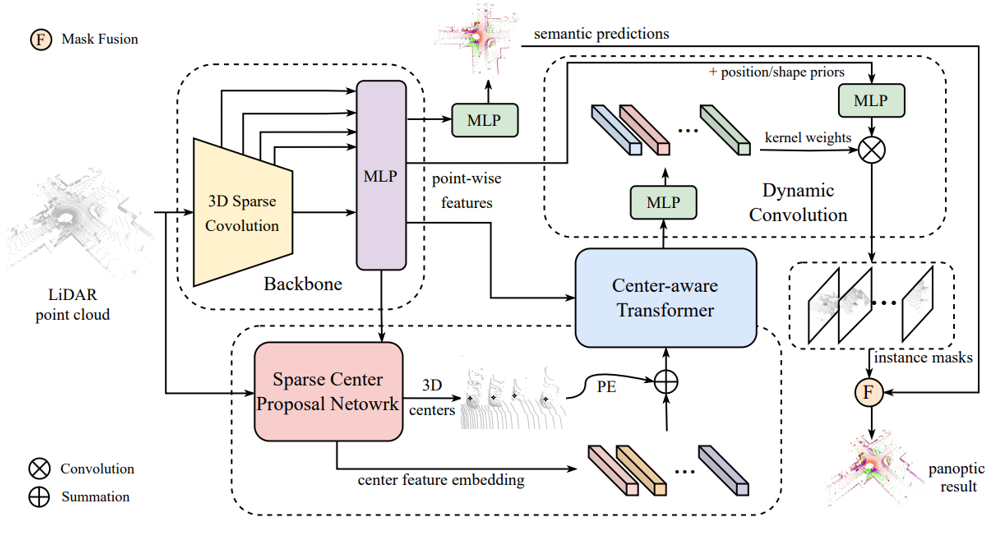
CenterLPS: Segment Instances by Centers for LiDAR Panoptic Segmentation
基于实例中心编码的点云全景分割
作者:梅剑标、杨煜、王蒙蒙、李梓彰、侯晓军、罗钟元、李来健、刘勇
点云全景分割(LPS)在自动驾驶和机器人领域有着广泛的应用前景,近年来受到越来越多的关注。主流的LPS方法要么采用自上而下的策略,依靠3D目标检测器来发现实例,要么利用耗时的启发式聚类算法以自下而上的方式对实例进行分组。受实例中心表示和基于动态核的分割方法的启发,本文设计了基于中心的实例编码和解码范式,提出了一种新的非检测和非聚类框架(CenterLPS)。具体来说,为有效编码实例特征,本文提出了一个稀疏中心提议网络来生成稀疏3D实例中心和对应的中心特征嵌入。然后使用中心感知的Transformer来收集不同实例中心特征嵌入之间以及实例中心周围点的上下文。更进一步,本文基于增强的中心特征嵌入生成动态核权重,用于初始化动态卷积以解码最终的实例掩膜。最后,设计了掩膜融合模块来统一语义和实例预测并提高最终的全景质量。本文在SemanticKITTI 和 nuScenes 上进行了大量实验,证明了本文提出的基于中心的框架 CenterLPS 的有效性。
07 IROS 2023
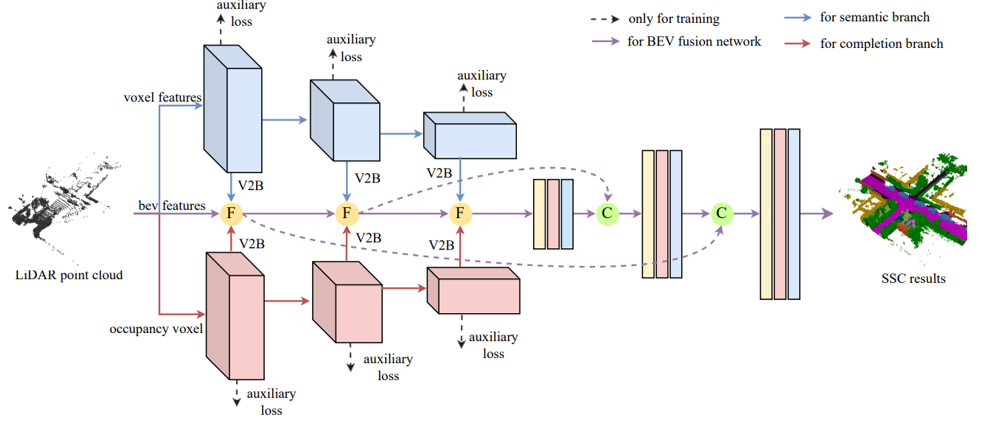
SSC-RS: Elevate LiDAR Semantic Scene Completion with Representation Separation and BEV Fusion
基于表示分解和BEV融合的点云语义场景补全
作者:梅剑标、杨煜、王蒙蒙、黄田鑫、杨雪梦、刘勇
点云语义场景补全 (SSC) ,从稀疏 LiDAR 点云中预测整个 3D 场景中每个体素的语义占用, 由于复杂的户外场景(例如各种形状/大小以及遮挡),从部分观察中精确估计整个 3D 现实世界场景的语义和几何结构具有挑战性。大多数户外SSC方法以混合或半混合方式考虑语义上下文(语义表示)和几何结构(几何表示),如何有效地学习语义/几何表示并利用两者之间的关系仍有待探索。本文从特征表示分解(语义特征/几何特征)和BEV融合的角度提出一种新的点云语义场景补全网络,根据语义/几何特征各自的性质,分别设计基于层次化监督的稀疏语义分支和轻量级几何分支来提取多尺度语义上下文和几何结构,增强了网络特征表示能力且降低了计算量,此外设计BEV融合网络对语义/几何特征进行自适应融合,相比于常规的3D空间的稠密特征融合,更加方便高效。
08 IROS 2023
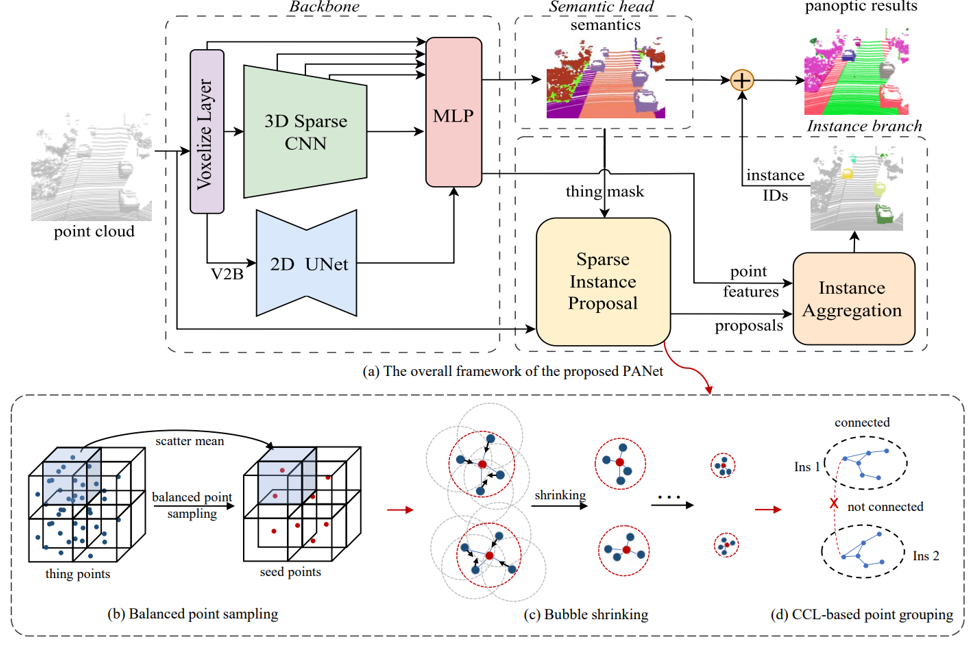
PANet: LiDAR Panoptic Segmentation with Sparse Instance Proposal and Aggregation
基于稀疏实例提议和聚合的点云全景分割
作者:梅剑标、杨煜、王蒙蒙、侯晓军、李来健、刘勇
点云全景分割(LPS) 将点云语义分割和实例分割结合在一个框架中,为场景中的点提供语义标签,并为属于实例(事物)的点提供实例 ID。为消除主流聚类方法对偏移分支的依赖并提高在大目标上的性能,本文提出了一种新的 LPS 框架。首先,本文提出了一种非学习的稀疏实例提议(SIP)模块,采用“采样-偏移-聚类”方案,可以有效地将原始点云中的前景点直接聚类为实例。具体来讲,引入平衡点采样来生成在距离范围内点分布更均匀的稀疏种子点;并且提出了一种偏移方法——“气泡收缩”,将种子点偏移到聚类中心;然后利用连接组件标签算法来生成实例提议。此外,本文提出实例聚合模块来整合潜在的碎片实例,改进SIP 模块在大目标上的性能。
09 IROS 2023
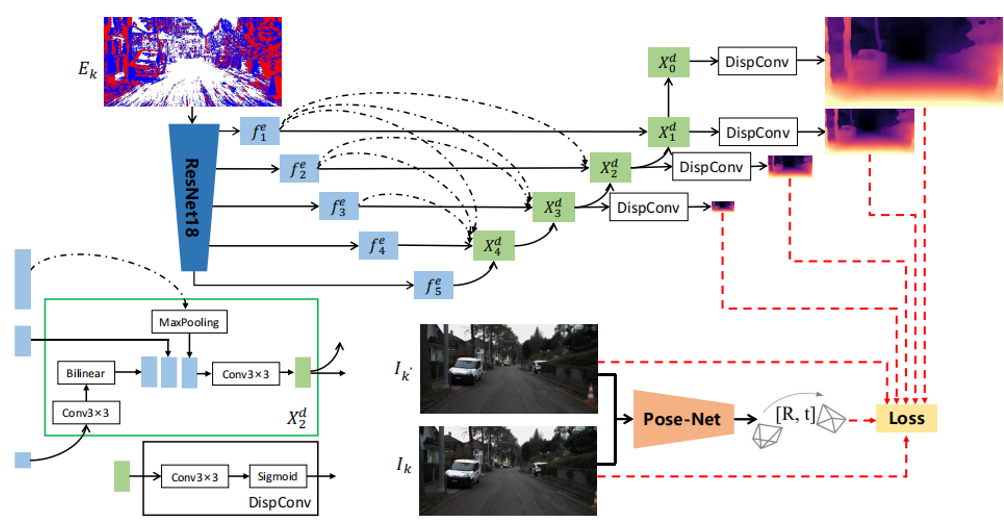
Self-Supervised Event-Based Monocular Depth Estimation using Cross-Modal Consistency
利用跨模态一致性的事件相机自监督单目深度估计
作者:朱俊宇、刘丽娜、姜博丰、温丰、张洪波、李晚龙、刘勇
事件相机是一种新型相机,它输出异步的事件数据,具有高时间分辨率、高动态范围、低带宽、低功耗的优点,近年来有许多工作在事件相机上探索了不同的视觉任务,该论文关注的是事件相机自监督单目深度估计。考虑到事件数据不同于图像数据,它不满足灰度一致性假设,因此该论文提出利用事件数据的单目深度估计和与之像素对齐的图像数据,以及图像数据相邻帧的位姿估计,根据图像的灰度一致性假设,构造跨模态一致性损失得到自监督信号。另外考虑到事件数据在图像平面上是很稀疏的,该论文还提出多尺度跳跃链接结构以提升网络的特征提取能力。我们在MVSEC和DSEC数据集上进行了实验,验证了我们的贡献是有效的,我们模型的精度也超越了现有的相关方法。
10 IROS 2023
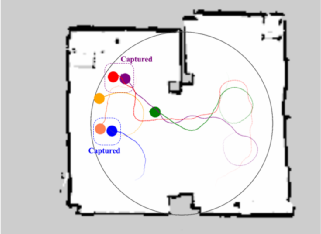
Large Scale Pursuit-Evasion Under Collision Avoidance Using Deep Reinforcement Learning
基于深度强化学习的大规模集群追逃避碰
作者:杨贺磊、葛鹏、曹军杰、杨一帆、刘勇
该论文研究了多个追逐者和多个逃避者(MPME)场景中的多机器人追逐逃避任务。双方的机器人均为分布式决策,在满足运动学约束和避碰的前提下完成各自追逐/逃避任务,相较于追逐者运动更为灵活的逃避者对追逐者的合作协同提出了重要挑战。追逃双方 learning-based 的策略在博弈对抗中协同进化,有效降低了基于规则的对手策略导致的过拟合风险。为了解决大规模场景下的维度灾难,论文提出了一种基于自注意力机制的 Mix-Attention 方法,实验结果表明,随着规模的增加,将 Mix-Attention 和 IPPO 相结合在 MPME 问题上显著优于其他方法,训练得到的策略具备一定的泛化性和鲁棒性,可以适应不同数量智能体和障碍物的场景而无需额外训练。

11 IROS 2023
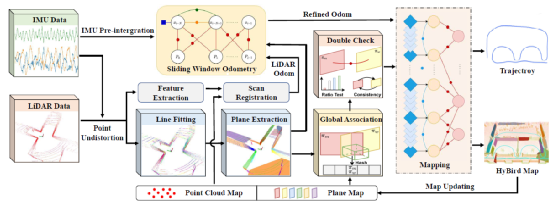
LiDAR-Inertial SLAM with Effciently Extracted Planes
高效提取的平面辅助的激光-惯性SLAM
作者:陈超、吴航宇、马煜铠、吕佳俊、李来健、刘勇
该论文针对现有激光惯性SLAM在室内狭小环境中观测约束不足导致定位累积漂移严重的问题,提出了高效提取的平面辅助的激光惯性SLAM系统。论文提出了基于区域生长的点→线→面的平面提取方法,该方法首先针对机械式LIDAR同一线束上的点云拟合直线段,然后对相邻直线段构造线段连通图,最后基于线段连通图进行区域生长拟合平面。相比同类别的平面提取方法,该方法运行速度快,且提取的平面更加完整。论文然后将提取的显式平面融入SLAM前端里程计,以获取后端优化更准确的初值位姿。在SLAM后端优化中,将提取的显式平面作为新的路标参与因子图优化,并提出基于体素哈希的平面地图管理方法和更鲁棒的平面匹配策略,显著降低了系统累积漂移。
12 期刊 TIP
Omni-Frequency Channel-Selection Representations for Unsupervised Anomaly Detection
基于全频段重建和通道选择的无监督图像异常检测
作者:梁雨菲、张江宁、赵世玮、吴润泽、刘勇、潘树文
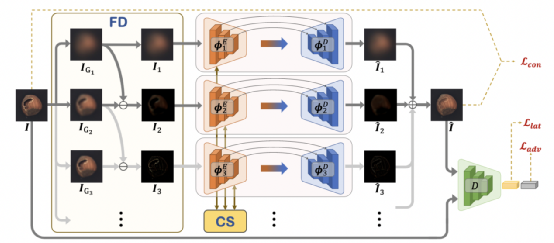
近年来,基于密度估计和分类预测的方法在无监督异常检测中占据主导地位,而基于重构的方法由于模型重构能力差、性能不足而很少被提及。因此,本文将重点放在改进基于重构的图像异常检测方法上,提出了一种新颖的全频通道选择重构网络(OCR-GAN)来处理频率视角下的图像异常检测任务。具体来说,本文提出了频率解耦模块(FD),将输入图像解耦为不同的频率成分,并将重建过程建模为并行全频图像复原的组合,这是基于我们观察到正常图像和异常图像在频率分布上存在显著差异。考虑到多个频率之间的相关性,本文进一步提出了通道选择(CS)模块,该模块通过自适应选择不同的通道特征来实现不同频段编码器之间的信息交互。大量的实验证明了本文方法的有效性和优越性,例如,在MVTec AD数据集上OCR-GAN实现了98.3的检测AUC,相比于基于重建的基线方法提升了38.1,相比于当前的SOTA方法提升了0.3。
13 期刊 PR
Data-Free Quantization via Mixed-Precision Compensation without Fine-Tuning
无数据量化:无需微调的混合精度补偿
作者:陈军、白世鹏、黄田鑫、王蒙蒙、田冠中、刘勇
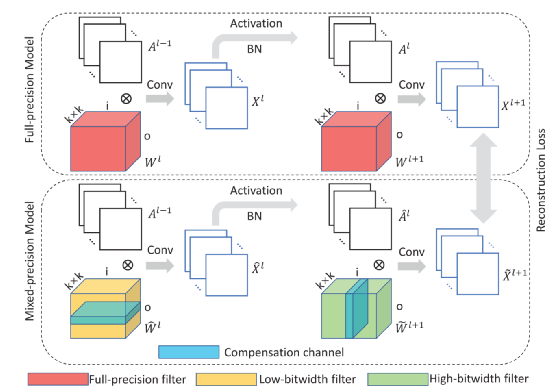
神经网络量化是模型压缩领域非常有前途的解决方案,但其产生的精度很大程度上取决于训练/微调过程,并且需要原始数据。这不仅带来大量的计算和时间成本,而且不利于隐私和敏感信息的保护。因此,最近的一些工作开始关注无数据量化。然而,无数据量化在处理超低精度量化时表现不佳。尽管研究人员利用合成数据的生成方法部分解决了这个问题,但数据合成需要花费大量的计算和时间。在本文中,我们提出了一种无数据混合精度补偿(DF-MPC)方法,无需任何数据和微调过程即可恢复超低精度量化模型的性能。通过假设低精度量化层引起的量化误差可以通过高精度量化层的重建来恢复,我们在数学上给出了预训练的全精度模型与其分层混合精度量化模型之间的重建损失。根据公式,我们通过最小化特征图的重建损失从理论上推导出闭合形式的解。由于DF-MPC不需要任何原始/合成数据,因此它是逼近全精度模型的更有效方法。在实验上,与最近的方法相比,我们的DF-MPC 在无需任何数据和微调的情况下,能够在超低精度量化模型上实现更高的精度。
14 期刊 RAL
Geo-Localization with Transformer-Based 2D-3D Match Network
一种基于2D-3D匹配网络的地理定位方法
作者:李来健、马煜铠、唐恺、赵祥瑞、陈超、黄健鑫、梅剑标、刘勇
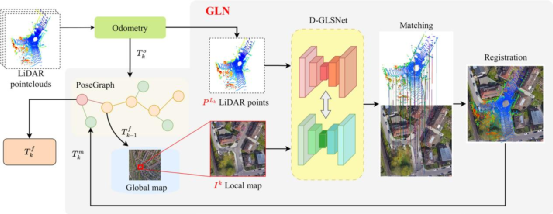
文章提出了一种通过卫星地图与LiDAR点云跨域匹配来进行地理定位的方法。该方法提出了一个名为 D-GLSNet 的 2D-3D 匹配网络,它通过端到端的方式学习 LiDAR 点云和卫星图像的匹配关系。D-GLSNet 可在 LiDAR 点云和卫星图像之间提供精确的点到像素关联,之后根据匹配可计算出LiDAR 点云和卫星图像之间的水平偏移(Δx,Δy)和角度偏差Δθ,从而实现精确配准。为了所提出的网络在定位方面的潜力,基于网络设计了一个地理定位节点(GLN),它实现地理定位并可以与 SLAM 系统无缝集成。与 GPS 相比,GLN 不易受到外部干扰,例如建筑物遮挡。在城市场景中,所提出的D-GLSNet可以输出高质量的匹配,使GLN能够稳定运行并提供更准确的定位结果。
15 期刊 PRL
Hierarchical Supervisions with Two-Stream Network for Deepfake Detection
基于层级监督和双流网络的换脸检测
作者:梁雨菲、王蒙蒙、金怡宁、潘树文、刘勇
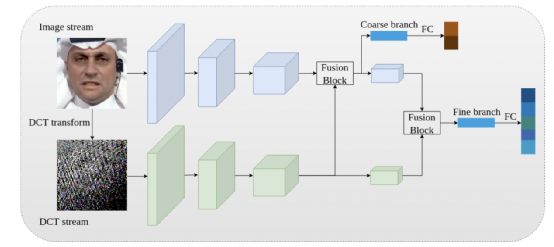
近期,人脸生成和伪造的质量达到了令人印象深刻的水平,甚至使人类难以分辨真假人脸。与此同时,辨别真假人脸的方法也不断涌现,如Deepfake检测。然而,Deepfake检测任务仍然具有挑战性,特别是互联网上流传的低分辨率伪造图像和人脸生成方法的多样性使得这项任务十分困难。在这项工作中,我们提出了一种新的Deepfake检测网络,它可以有效区分由不同生成方法生成的不同分辨率的伪造人脸。首先,本文设计了一个双流框架,其中包含一个常规图像域分支和一个频域分支来处理低分辨率伪造监测问题,因为我们发现低分辨率为着图像的频域伪影会被保留。其次,本文以从粗到细的方式引入分级监管,网络包括一个粗分类分支,用于对真假图像进行分类,以及细分类分支,用于对真实图像和四种不同类型的伪造图像进行进一步细分类。广泛的实验证明了本文所提框架在广泛使用的FaceForensics++数据集上的有效性。
16 期刊 ACM TIST
Fast Real-Time Video Object Segmentation with a Tangled Memory Network
基于纠缠记忆网络的快速实时视频目标分割
作者:梅剑标、王蒙蒙、杨煜、李艳君、刘勇
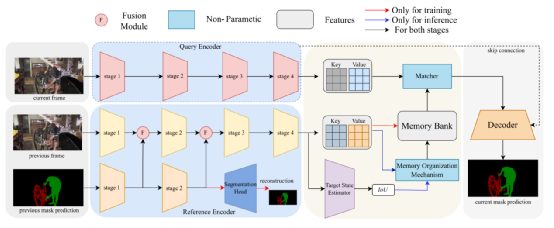
本文中提出了一种快速实时的纠缠记忆网络(TMN),可以高效地分割目标。具体而言,本文提出了纠缠参考编码器和基于状态估计的记忆组织机制,以充分利用掩膜特征,并减少基于记忆的方法中使用动态存储带来的内存开销和计算负担。首先,本文设计纠缠双流参考编码器,从 RGB 帧和预测掩模中提取和融合特征,以利用掩模特征中丰富的边缘和轮廓信息; 其次,本文设计了目标状态估计器来学习掩膜预测值和真实值之间的 IoU 分数,以指示预测掩模的质量并反馈用于组织记忆的在线预测状态;此外,为了加速推理过程并避免内存溢出,本文根据状态估计器提供的掩膜状态分数设计了一种新的高效记忆组织机制,使用固定大小的记忆来存储历史特征。
17 期刊 NCA
Expert Demonstrations Guide Reward Decomposition for Multi-Agent Cooperation
专家样本指导奖励分解
作者:刘维维、敬巍、刘善琪、阮雨迪、张可鑫、杨建、刘勇
人类能够通过合作极为出色的完成团队任务,是因为每个人都正确获知自己的行为对团队的贡献,但是由于共享相同的团队奖励,使多智能体系统存在信用分配问题。这项工作使用专家样本来分解每个时间步的奖励。具体来说,引入GAI和MAGAIL来衡量智能体行为和专家行为之间的相似性,并学习奖励分解策略。如图所示,使用专家样本和强化学习经验池中经验来训练鉴别器,其被用来判断智能体的状态-动作对与专家样本的相似性,然后分解奖励。总的来说,我们的算法为每个智能体提供每一步的奖励信号,并引导智能体表现得更像专家。最后,在三个开源实验平台进行了大量实验来验证所提出算法的有效性,并且发现在一些场景中所提出的算法表现远高于基线算法。此外,我们的算法在专家样本数量相同的情况下明显优于MAGAIL 和MAVEN+BC 等模仿学习算法。最后,与基线算法相比,由于专家数据间接指导了策略更新,我们的算法生成的数据分布更接近专家样本分布。
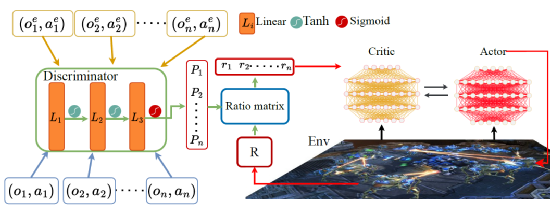
专家指导奖励分解算法框图
18 期刊 EAAI
Single-Shot Pruning and Quantization for Hardware-Friendly Neural Network Acceleration
单次修剪和量化:面向硬件友好的神经网络加速方法
作者:姜博丰、陈军、刘勇
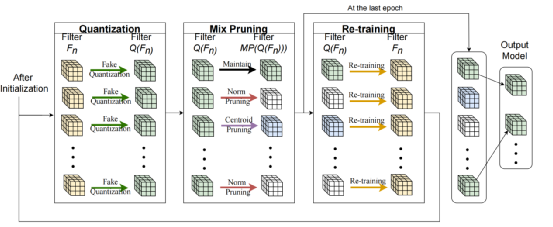
将卷积神经网络(CNN)部署在嵌入式系统是一个前景良好但挑战性极大的任务。这是因为目前CNN参数数量较多,前向推理计算量较大,但底层硬件资源受限。为了解决这个问题,目前广泛应用的方法是剪枝和模型量化。但是这些方法较为费时,并且只能串行地对神经网络进行压缩。本文提出了一种单次修剪和量化策略,可在单个训练过程中同时对CNN进行量化和修剪,这样可以在训练中同时考虑由结构引起的量化误差和剪枝误差,从而对网络参数进行更新。我们在两个常用数据集CIFAR-10和CIFAR-100上对该方法进行了评估。实验结果表明,相比之前的模型,我们的模型体积减小了69.4%,准确率下降较小,并且在硬件(NVIDIA Xavier NX)上运行速度可以提升至6-8倍。

点击进入—>【目标检测和Transformer】交流群
ICCV / CVPR 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!▲扫码进星球
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看![]()
这篇关于浙江大学刘勇教授课题组多项工作收录ICCV2023及近期学术成果汇编的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





