本文主要是介绍AI for Science:OpenVINO+英特尔独立显卡解薛定谔方程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:王立奇 英特尔边缘计算创新大使
一、PINN——加入物理约束的神经网络
基于物理信息的神经网络(Physics-informed Neural Network, 简称PINN),是一类用于解决有监督学习任务的神经网络,它不仅能够像传统神经网络一样学习到训练数据样本的分布规律,而且能够学习到数学方程描述的物理定律。与纯数据驱动的神经网络学习相比,PINN在训练过程中施加了物理信息约束,因而能用更少的数据样本学习到更具泛化能力的模型。本文主要解析这种神经网络以及相关应用
1. 论文简介
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations 。
https://www.sciencedirect.com/science/article/pii/S0021999118307125
2019年,来自布朗大学应用数学的研究团队提出了一种用物理方程作为运算限制的“物理激发的神经网络” (PINN) 并发表在了计算物理学领域权威杂志《计算物理学期刊》(Journal of Computational Physics) 上。这篇论文一经发表就获得了大量关注。这篇论文因为代码体系的完整性使得开发人员们很容易上手把相关的学习框架应用到不同领域上去。所以在发表不久之后,一系列不同的PINN也被其他研究者开发出来。甚至可以不夸张的说,PINN是目前AI物理领域论文中最常见到的框架和词汇之一。
2. 算法描述
而所谓的物理神经网络,其实就是把物理方程作为限制加入神经网络中使训练的结果满足物理规律。而这个所谓的限制是怎么实现的?其实就是通过把物理方程的迭代前后的差值加到神经网络的损失函数里面去,让物理方程也“参与”到了训练过程。这样,神经网络在训练迭代时候优化的不仅仅是网络自己的损失函数,还有物理方程每次迭代的差,使得最后训练出来的结果就满足物理规律了。

二、DeepXDE
DeepXDE 由 Lu Lu 在布朗大学 George Karniadakis 教授的指导下于 2018 年夏季至 2020 年夏季开发,并得到 PhILM 的支持。 DeepXDE 最初是在布朗大学的 Subversion 中自行托管的,名称为 SciCoNet(科学计算神经网络)。 2019 年 2 月 7 日,SciCoNet 从 Subversion 迁移到 GitHub,更名为 DeepXDE。
1.DeepXDE 特性
DeepXDE 已经实现了如上所示的许多算法,并支持许多特性:
- 复杂的域几何图形,没有专制网格生成。原始几何形状是间隔、三角形、矩形、多边形、圆盘、长方体和球体。其他几何可以使用三个布尔运算构建为构造实体几何 (CSG):并集、差集和交集。
- 多物理场,即(时间相关的)耦合偏微分方程。
- 5 种类型的边界条件 (BC):Dirichlet、Neumann、Robin、周期性和一般 BC,可以在任意域或点集上定义。
- 不同的神经网络,例如(堆叠/非堆叠)全连接神经网络、残差神经网络和(时空)多尺度傅里叶特征网络。
- 6种抽样方法:均匀抽样、伪随机抽样、拉丁超立方抽样、Halton序列、Hammersley序列、Sobol序列。
- 训练点可以在训练期间保持不变,也可以每隔一定的迭代重新采样一次。
- 方便保存 训练期间的模型,并加载训练好的模型。
- 使用 dropout 的不确定性量化。
- 许多不同的(加权)损失、优化器、学习率计划、指标等回调,用于在训练期间监控模型的内部状态和统计信息,例如提前停止。
- 使用户代码紧凑,与数学公式非常相似。
- DeepXDE 的所有组件都是松耦合的,因此 DeepXDE 结构良好且高度可配置。
- 可以轻松自定义 DeepXDE 以满足新的需求。
2.数值算例
(1)、问题设置
我们将求解由下式给出的非线性薛定谔方程:
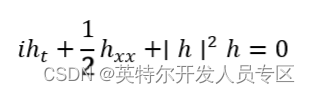
周期性边界条件为:

初始条件为:
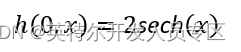
Deepxde 只使用实数,因此我们需要明确拆分复数 PDE 的实部和虚部。
代替单个残差:
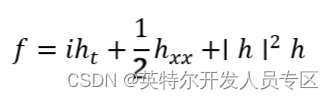
我们得到两个(实值)残差:
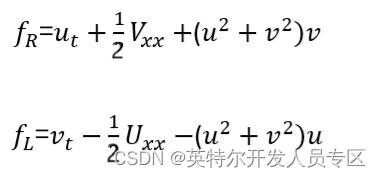
其中 u ( x , t )和 v ( x , t ) 分别表示h的实部和虚部。
import numpy as npimport deepxde as dde# 用于绘图import matplotlib.pyplot as pltfrom scipy.interpolate import griddatax_lower = -5x_upper = 5t_lower = 0t_upper = np.pi / 2# 创建 2D 域(用于绘图和输入)x = np.linspace(x_lower, x_upper, 256)t = np.linspace(t_lower, t_upper, 201)X, T = np.meshgrid(x, t)# 整个域变平X_star = np.hstack((X.flatten()[:, None], T.flatten()[:, None]))# 空间和时间域/几何(对于 deepxde 模型)space_domain = dde.geometry.Interval(x_lower, x_upper)time_domain = dde.geometry.TimeDomain(t_lower, t_upper)geomtime = dde.geometry.GeometryXTime(space_domain, time_domain)# 损失的“物理信息”部分def pde(x, y):"""INPUTS:x: x[:,0] 是 x 坐标x[:,1] 是 t 坐标y: 网络输出,在这种情况下:y[:,0] 是 u(x,t) 实部y[:,1] 是 v(x,t) 虚部OUTPUT:标准形式的 pde,即必须为零的东西"""u = y[:, 0:1]v = y[:, 1:2]# 在'jacobian'中,i 是输出分量,j 是输入分量u_t = dde.grad.jacobian(y, x, i=0, j=1)v_t = dde.grad.jacobian(y, x, i=1, j=1)u_x = dde.grad.jacobian(y, x, i=0, j=0)v_x = dde.grad.jacobian(y, x, i=1, j=0)# 在“hessian”中,i 和 j 都是输入分量。 (Hessian 原则上可以是 d^2y/dxdt、d^2y/d^2x 等)# 输出组件由“组件”选择u_xx = dde.grad.hessian(y, x, component=0, i=0, j=0)v_xx = dde.grad.hessian(y, x, component=1, i=0, j=0)f_u = u_t + 0.5 * v_xx + (u ** 2 + v ** 2) * vf_v = v_t - 0.5 * u_xx - (u ** 2 + v ** 2) * ureturn [f_u, f_v]# 边界条件和初始条件# 周期性边界条件bc_u_0 = dde.PeriodicBC(geomtime, 0, lambda _, on_boundary: on_boundary, derivative_order=0, component=0)bc_u_1 = dde.PeriodicBC(geomtime, 0, lambda _, on_boundary: on_boundary, derivative_order=1, component=0)bc_v_0 = dde.PeriodicBC(geomtime, 0, lambda _, on_boundary: on_boundary, derivative_order=0, component=1)bc_v_1 = dde.PeriodicBC(geomtime, 0, lambda _, on_boundary: on_boundary, derivative_order=1, component=1)# 初始条件def init_cond_u(x):"2 sech(x)"return 2 / np.cosh(x[:, 0:1])def init_cond_v(x):return 0ic_u = dde.IC(geomtime, init_cond_u, lambda _, on_initial: on_initial, component=0)ic_v = dde.IC(geomtime, init_cond_v, lambda _, on_initial: on_initial, component=1)data = dde.data.TimePDE(geomtime,pde,[bc_u_0, bc_u_1, bc_v_0, bc_v_1, ic_u, ic_v],num_domain=10000,num_boundary=20,num_initial=200,train_distribution="pseudo",)# 网络架构net = dde.maps.FNN([2] + [100] * 4 + [2], "tanh", "Glorot normal")model = dde.Model(data, net)Adam 优化
# 强烈建议使用 GPU 加速系统.model.compile("adam", lr=1e-3, loss="MSE")model.train(epochs=1000, display_every=100)
L-BFGS 优化
dde.optimizers.config.set_LBFGS_options(maxcor=50,ftol=1.0 * np.finfo(float).eps,gtol=1e-08,maxiter=1000,maxfun=1000,maxls=50,)model.compile("L-BFGS")model.train()Compiling model...'compile' took 0.554160 sTraining model...Step Train loss Test loss Test metric1000 [1.25e-02, 1.32e-02, 2.72e-06, 3.28e-04, 5.27e-06, 4.65e-06, 2.24e-02, 1.31e-03] [1.25e-02, 1.32e-02, 2.72e-06, 3.28e-04, 5.27e-06, 4.65e-06, 2.24e-02, 1.31e-03] [] 2000 [7.03e-04, 7.62e-04, 6.76e-06, 1.33e-05, 2.88e-07, 8.49e-06, 4.01e-04, 3.86e-05] INFO:tensorflow:Optimization terminated with:Message: STOP: TOTAL NO. of f AND g EVALUATIONS EXCEEDS LIMITObjective function value: 0.001928Number of iterations: 945Number of functions evaluations: 10012001 [7.18e-04, 7.43e-04, 6.27e-06, 1.23e-05, 2.94e-07, 8.89e-06, 4.01e-04, 3.82e-05] [7.18e-04, 7.43e-04, 6.27e-06, 1.23e-05, 2.94e-07, 8.89e-06, 4.01e-04, 3.82e-05] [] Best model at step 2001:train loss: 1.93e-03test loss: 1.93e-03test metric: []'train' took 179.449384 s(<deepxde.model.LossHistory at 0x13422ad90>,<deepxde.model.TrainState at 0x10d759850>)# 做预测prediction = model.predict(X_star, operator=None)u = griddata(X_star, prediction[:, 0], (X, T), method="cubic")v = griddata(X_star, prediction[:, 1], (X, T), method="cubic")h = np.sqrt(u ** 2 + v ** 2)# 绘制预测fig, ax = plt.subplots(3)ax[0].set_title("Results")ax[0].set_ylabel("Real part")ax[0].imshow(u.T,interpolation="nearest",cmap="viridis",extent=[t_lower, t_upper, x_lower, x_upper],origin="lower",aspect="auto",)ax[1].set_ylabel("Imaginary part")ax[1].imshow(v.T,interpolation="nearest",cmap="viridis",extent=[t_lower, t_upper, x_lower, x_upper],origin="lower",aspect="auto",)ax[2].set_ylabel("Amplitude")ax[2].imshow(h.T,interpolation="nearest",cmap="viridis",extent=[t_lower, t_upper, x_lower, x_upper],origin="lower",aspect="auto",)plt.show()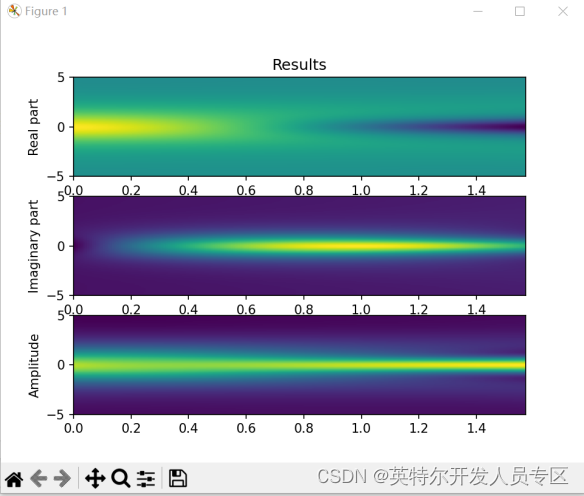
三、生成OpenVINO IR模型
如需使用LabVIEW OpenVINO推理deepxde的模型,需要做以下几步:
1. 将deepxde模型转成onnx模型作为中间件:

代码中,我们首先要创建一个和X_star的形状相同的X2作为参考输入(X2必须是cpu上的矩阵),其次是新建一个基于cpu的mode2,其权重和model完全一致。最后使用torch.onnx.export生成onnx模型。
2. 使用命令行将onnx模型转为IR模型:
mo --input_model Schrodinger.onnx --input_shape "[256,2]"

命令中,我们将输入的形状设置为256*2,其中第0列为位置x,第1列为时间t。256为我们设置的每个时间点需要推理的x的点数,可以为任意长度。
完成上述两个步骤后,我们可以看到文件夹里多了三个文件Schrodinger.onnx、Schrodinger.xml和Schrodinger.bin。其中onnx为pytorch生成的onnx模型,xml和bin为mo生成的OpenVINO IR模型。
四、LabVIEW调用IR模型
LabVIEW是NI推出的图形化编程环境,在科研、工业测控领域有着广泛的应用。使用LabVIEW的波形图、强度图等控件,可以使用户更直观的观测自己模型的训练结果。
使用我们编写好的Schrodinger_OpenVINO.vi,即可快速推理Schrodinger方程的OpenVINO模型。以下是使用LabVIEW调用模型的步骤:
1. 初始化模型:使用LoadIR.vi调用xml和bin文件,推理引擎可使用CPU或GPU(Intel核显或独显);

2. 初始化位置。根据我们训练时用的参数,需要模拟-5~5范围内任意数量的位置点(本案例中使用256个位置点)。
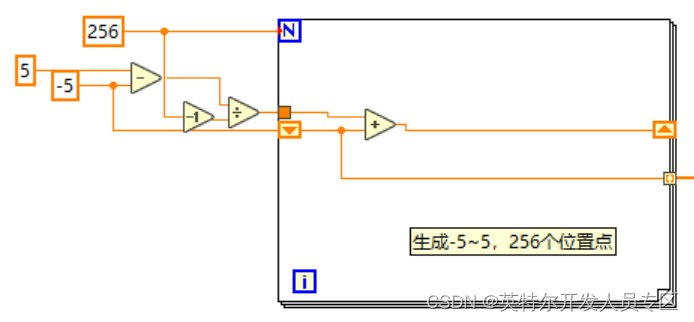
3. 初始化时间,根据我们训练的参数,需要模拟0~pi/2范围内任意数量的时间点(本案例中使用201个时间点。
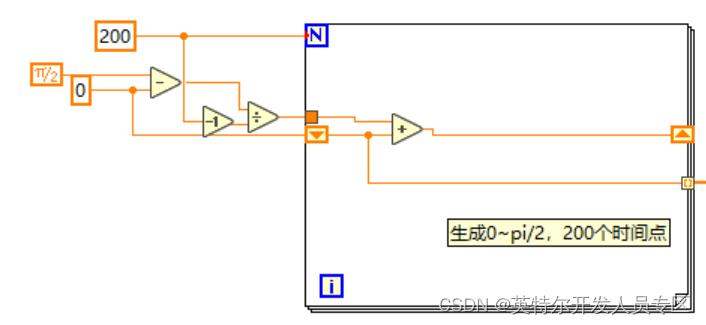
4. 推理模型时。每次循环将某一个时间点复制256份,和所有的256个位置点组成2*256的二维数组,然后转置成256*2的数组,输入至网络中。

5. 获取输出。输出为256*2,但和输入的意义不同:其中第0列为波函数h的实部,第1列为h的虚部。因此需要将结果转置成2*256,后,方能使用波形图(Waveform Graph)显示两条曲线。

6. 获取整个时间段、所有位置的结果。使用For循环索引,保存所有时间段实部、虚部和幅值的结果,并显示在强度图上。

7. 使用release.vi关闭OpenVINO模型。
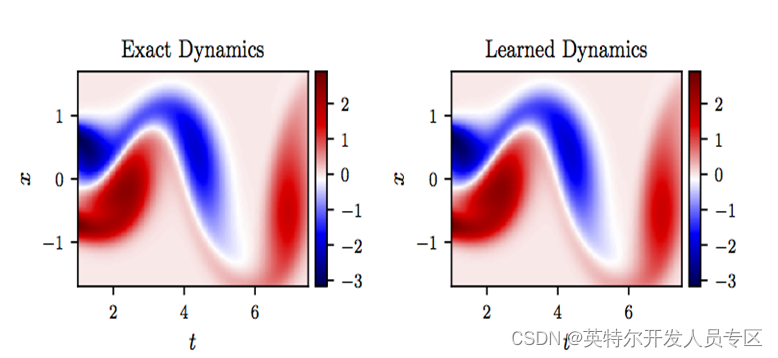
运行程序。我们使用Intel A770独立显卡(设备名称为GPU.1)运行该模型。运行结果如下图:
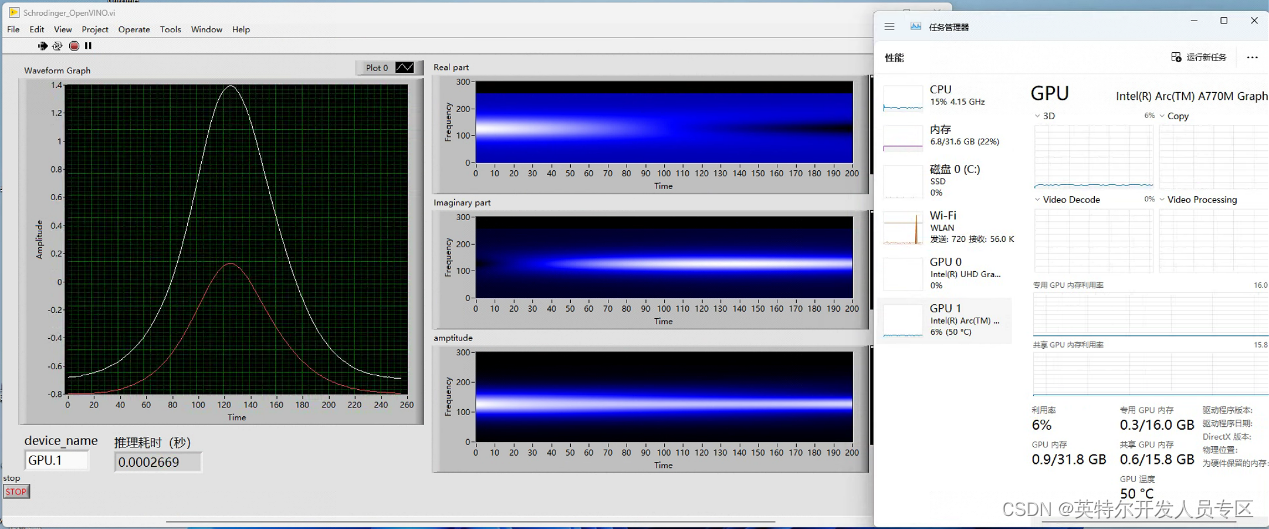
左边的波形图为每一个时间点的波函数实部和虚部的曲线,右边的强度图为所有时间点的实部、虚部和幅值分布。结果表明,使用OpenVINO推理物理信息神经网络模型,和deepxde的结果完全一致。此外,在A770上模型也得到了最大加速,并节省了大量的cpu资源。
五、公司介绍
上海仪酷智能科技有限公司是国内领先的人工智能软件提供商和机器人应用开发商,开发了低代码可重构的人工智能定制平台,包括基于边缘计算的高性能、高性价比工业硬件,以及跨平台的图形化深度学习视觉软件,满足智能制造、智慧医疗、智慧教育等多个领域的定制化需求;同时为广大院校用户搭建了人工智能教育软硬件平台(语音交互套件、无人驾驶套件、机械臂套件、以及支持所有硬件的云端实验平台);公司是百度、软银机器人、NI、Intel的战略合作伙伴,科大讯飞创投生态圈下企业,连续多年上海交通大学优秀合作伙伴,上海市高新技术企业,姑苏领军人才,且入驻百度飞桨人工智能产业赋能中心,拥有70余项专利及著作权,总部位于上海,于苏州、安庆设立分公司。
大家可以在公司官网下载仪酷软件工具包:仪酷智能
这篇关于AI for Science:OpenVINO+英特尔独立显卡解薛定谔方程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








