本文主要是介绍时序预测 | MATLAB实现EMD-iCHOA+GRU基于经验模态分解-改进黑猩猩算法优化门控循环单元的时间序列预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
时序预测 | MATLAB实现EMD-iCHOA+GRU基于经验模态分解-改进黑猩猩算法优化门控循环单元的时间序列预测
目录
- 时序预测 | MATLAB实现EMD-iCHOA+GRU基于经验模态分解-改进黑猩猩算法优化门控循环单元的时间序列预测
- 预测效果
- 基本介绍
- 程序设计
- 参考资料
预测效果
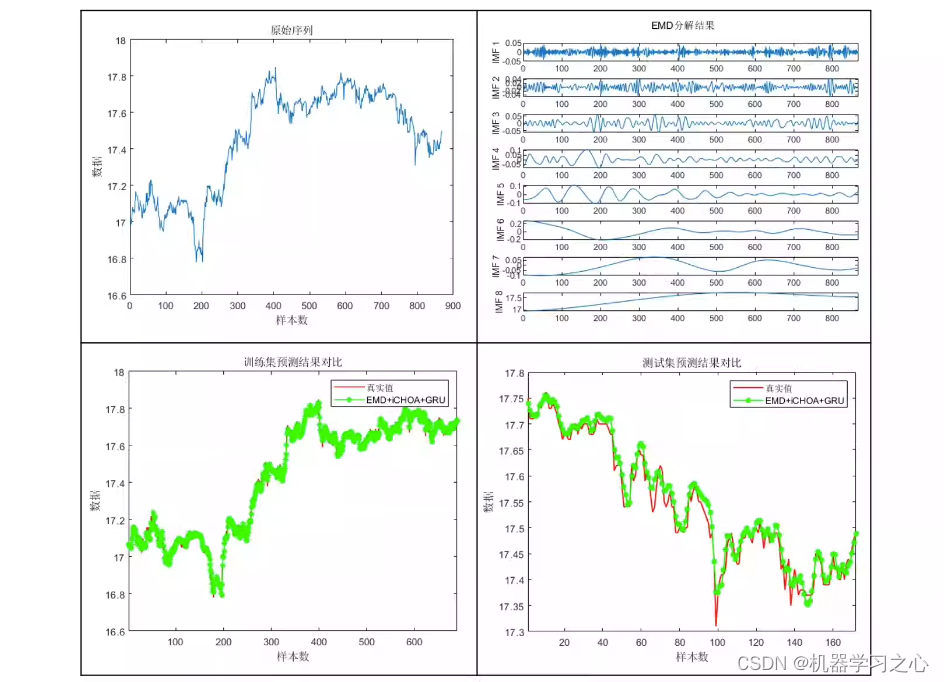
基本介绍
EMD-iCHOA+GRU基于经验模态分解-改进黑猩猩算法优化门控循环单元的时间序列预测
1.时间序列单列输入,如需多特征输入需额外付费。经过EMD分解后利用优化后的GRU对每个分量进行预测最后集成相加,算法新颖~EMD也可以换成其他分解方法,GRU也可以换成BiLSTM等其他预测模型。
2.iCHOA改进的黑猩猩优化算法改进点如下:
[1]利用Sobol序列初始化种群,增加种群的随机性和多样性,为算法全局寻优奠定基础;
[2]其次,引入基于凸透镜成像的反向学习策略,将其应用到当前最优个体上产生新的个体,提高算法的收敛精度和速度;
[3]最后,将水波动态自适应因子添加到攻击者位置更新处,增强算法跳出局部最优的能力。
3.直接替换Excel数据即可用,注释清晰,适合新手小白
4.附赠测试数据,输入格式如图3所示,可直接运行
程序设计
- 完整程序和数据下载方式私信博主回复:MATLAB实现EMD-iCHOA+GRU基于经验模态分解-改进黑猩猩算法优化门控循环单元的时间序列预测。
%% 参数设置
%% 训练模型
%% 模型预测%% 数据反归一化
T_sim1 = mapminmax('reverse', t_sim1, ps_output);
T_sim2 = mapminmax('reverse', t_sim2, ps_output);
function [IW,B,LW,TF,TYPE] = elmtrain(P,T,N,TF,TYPE)
% ELMTRAIN Create and Train a Extreme Learning Machine
% Syntax
% [IW,B,LW,TF,TYPE] = elmtrain(P,T,N,TF,TYPE)
% Description
% Input
% P - Input Matrix of Training Set (R*Q)
% T - Output Matrix of Training Set (S*Q)
% N - Number of Hidden Neurons (default = Q)
% TF - Transfer Function:
% 'sig' for Sigmoidal function (default)
% 'sin' for Sine function
% 'hardlim' for Hardlim function
% TYPE - Regression (0,default) or Classification (1)
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
% Output
% IW - Input Weight Matrix (N*R)
% B - Bias Matrix (N*1)
% LW - Layer Weight Matrix (N*S)
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
% Example
% Regression:
% [IW,B,LW,TF,TYPE] = elmtrain(P,T,20,'sig',0)
% Y = elmtrain(P,IW,B,LW,TF,TYPE)
% Classification
% [IW,B,LW,TF,TYPE] = elmtrain(P,T,20,'sig',1)
% Y = elmtrain(P,IW,B,LW,TF,TYPE)
% See also ELMPREDICT
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
if nargin < 2error('ELM:Arguments','Not enough input arguments.');
end
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
if nargin < 3N = size(P,2);
end
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
if nargin < 4TF = 'sig';
end
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
if nargin < 5TYPE = 0;
end
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
if size(P,2) ~= size(T,2)error('ELM:Arguments','The columns of P and T must be same.');
end
[R,Q] = size(P);
if TYPE == 1T = ind2vec(T);
end
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
[S,Q] = size(T);
% Randomly Generate the Input Weight Matrix
IW = rand(N,R) * 2 - 1;
% Randomly Generate the Bias Matrix
B = rand(N,1);
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
BiasMatrix = repmat(B,1,Q);
% Calculate the Layer Output Matrix H
tempH = IW * P + BiasMatrix;
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
switch TFcase 'sig'H = 1 ./ (1 + exp(-tempH));case 'sin'H = sin(tempH);case 'hardlim'H = hardlim(tempH);
end
% Calculate the Output Weight Matrix
LW = pinv(H') * T';
%--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------参考资料
[1] https://blog.csdn.net/article/details/126072792?spm=1001.2014.3001.5502
[2] https://blog.csdn.net/article/details/126044265?spm=1001.2014.3001.5502
这篇关于时序预测 | MATLAB实现EMD-iCHOA+GRU基于经验模态分解-改进黑猩猩算法优化门控循环单元的时间序列预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





