本文主要是介绍Gmapping 乱七八糟,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
笔记和总结:
void SlamGMapping::startLiveSlam()主要是订阅话题,主要有
scan_filter_-> registerCallback(boost::bind(&SlamGMapping::laserCallback,this, _1);
这句话就是要对激光雷达的数据进行处理的回调函数
接下来我们查看此回调函数
SlamGMapping::laserCallback(const sensor_msgs::LaserScan
::ConstPtr& scan)
//这个函数首先是调用initMapper(*scan)初始化函数,
//一些重要参数的初始化,将slam里的参数传递到 openslam 里 ,
//设定坐标系,坐标原点,以及采样函数随机种子的初始化,等等主
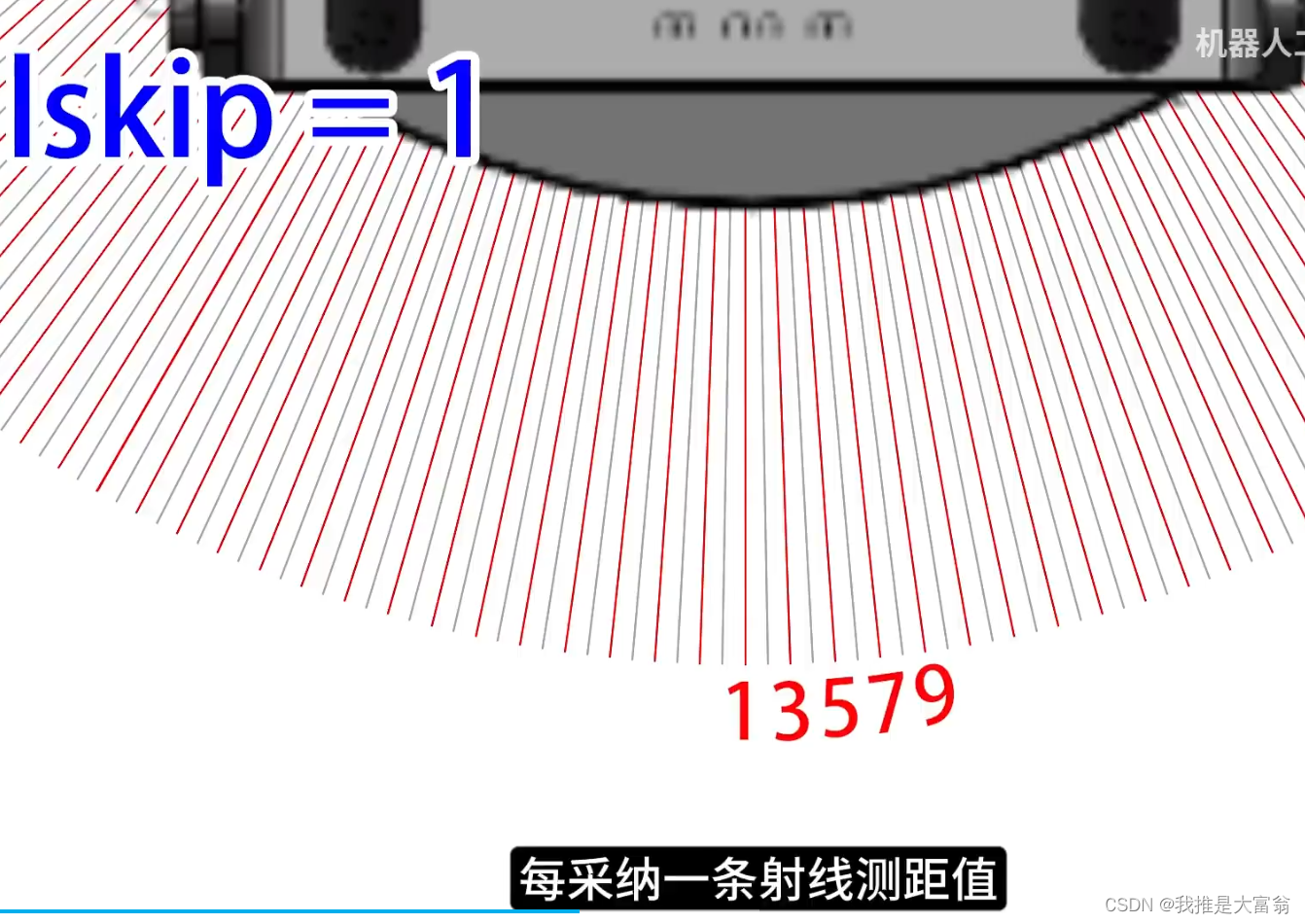
//要的调用有gsp_->setMatchingParameters(maxUrange_, maxRange_, sigma_, kernelSize_, lstep_, astep_, iterations_,lsigma_, ogain_, lskip_); //激光雷达数据匹配的参数gsp_->setUpdateDistances(linearUpdate_, angularUpdate_, resampleThreshold_); //设置更新距离的参数gsp_->setUpdatePeriod(temporalUpdate_); //设置更新的时间gsp_->GridSlamProcessor::init(particles_, xmin_, ymin_, //xmax_, ymax_, delta_, initialPose); //初始化粒子的大小gsp_->setllsamplestep(llsamplestep_); //设置激光雷达的步长
还有很多就不再意义举例这个函数*要转到pf的核心代码了将调用processScan 返回的值是一个bool判断是否更新成功现在进入函数addScan(*scan, odom_pose)看看用到了哪些函数,
此函数的输入是激光雷达的数据和里程计的信息,很明显这里面就要
用到了里程计模型,以及传说中的粒子滤波,通过粒子滤波更新机器
人的位姿。所以这一个函数是gmapping的核心代码。
读取位姿和激光数据,返回下面的函数,处理数据
return gsp_->processScan(reading); //处理激光数据也
//就是代码的核心都在这里 此函数在gridslamprocessor.cpp文
//件中,结束,回到laserCallback,还有最优一步updateMap1. 进入processScan(reading)就是要对运动模型采样的函数,
获取由运动采样获得的采样位
pose=m_motionModel.drawFromMotion(it->pose, relPose, m_odoPose); //第一个参数是输出,第二个参数是当前位姿,
m_odoPose是上一时刻的位姿
//现在我们就进入drawFromMotion 函数中查看实现代码
//具体的实现理论与代码的分析可查看之前的博客
//虽然写的不是很清楚 但是我已经尽力了更新位姿就是要计算机器人累计的平移和旋转
// accumulate the robot translation and rotation
OrientedPoint move=relPose-m_odoPose;
move.theta=atan2(sin(move.theta), cos(move.theta));
m_linearDistance+=sqrt(move*move);
m_angularDistance+=fabs(move.theta);
//在从运动模型采样后 也就是预测了粒子的位姿之后,
//接下来就是要根据测量数据对当前的粒子的位姿进行更新。2. 接下来就有另外一个重要函数
scanMatch(plainReading);//这个函数主要是根据测量
//数据与之前的地图比较更新粒子的位姿 以获得最优粒子位姿在这个函数中需要计算每个粒子的得分,如果得分低者将会被丢
弃或者权重下降,也就是为了寻找最优粒子。在程序中的顺序是scanMatch()此函数的具体是:GridSlamProcessor::scanMatch()//实现过程是在此函
//数的具体是:GridSlamProcessor.hxx文件中接下来就是在这里scanMatch()函数中的函数 第一个重要的函数:
(1)从每一次的激光数据中获取新的位姿。计算最优粒子的修正后
的位姿并返回其得分
score=m_matcher.optimize(corrected, it->map, it->pose, plainReading); //这里的corrected就是根据测量过得的修
正后的粒子位姿,那么在optimize 调用了 score 这个函数计算
粒子得分,具体理论的
//知识的研究详情查看《概率机器人》书中关于测量模型的解释在score 函数里,首先计算障碍物的坐标phit,然后将phit转换成网格坐标iPhit
计算光束上与障碍物相邻的非障碍物网格坐标pfree,pfree由phit沿激光束方向移动一个网格的距离得到,将pfree转换成网格坐标ipfree(增量,并不是实际值)
在iphit 及其附近8个(m_kernelSize:default=1)栅格(pr,对应自由栅格为pf)搜索最优可能是障碍物的栅格。
最优准则: pr 大于某一阈值,pf小于该阈值,且pr栅格的phit的平均坐标与phit的距离bestMu最小。得分计算:s +=exp(-1.0/m_gaussianSigma*bestMu*besMu) //距离越大,分数越小,分数的较大值集中在距离最小值处,符合正态分布模型
至此 score 函数结束并返回粒子(currentPose)得分,然后回到optimize函数所以optimize()的作用就是使用运动模型采样到的当前时刻的位姿 currentPose 进行微调,也就是传说中粒子滤波中的更新步骤。获得的位姿一定很接近正确位姿,所以该函数只是在之前粒子位姿的基础上对其进行前、后、左、右、左转、右转 共6次,然后选取得分最高的位姿,返回最终的得分
得到每个粒子的分数之后就是要判断粒子的得分是否满足要求,接下来是(2)现在我们返回到scanMatch()函数中在optimize函数 之后就是要根据当前粒子计算粒子的权重:并处理匹配失败的情况m_matcher.likelihoodAndScore(s, l, it->map, it->pose, plainReading);(3)在scanmatcher()函数中第三个重要的函数是根据粒子的权重,更新地图m_matcher.computeActiveArea(it->map, it->pose, plainReading); //用于计算每个粒子相应的位姿所扫描到的区域 , //计算过程首先考虑了每个粒子的扫描范围会不会超过子地图的大小,如果会,则resize地图的大小
//然后定义了一个activeArea 用于设置可活动区域,调用了gridLine() 函数,这个函数如何实现的,我不了解了
每次处理完一次的测量数据,之后还要进行权重更新。
updateTreeWeights(false);//权重更新
粒子集对目标分布的近似越差 权重的方差越大,在重采样的过程中还调用了registerScan ,这个函数和computeActive 函数有点像,不同的是,registerScan用于注册每个单元格的状态,自由、障碍,调用update()以及entroy()函数更新,最后是障碍物的概率 p=n/visits,障碍物的坐标用平均值来算完了后,又有一次权重计算。之后就是要重采样
到此处processScan 结束,回到laserCallback,还有最优一步updateMap
返回到laserCallback()函数之后就是要执行以下函数updateMap(*scan); //地图更新,先得到最优的粒子(用权重和 weightSum判断 ),得到机器人最优轨迹 这篇关于Gmapping 乱七八糟的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!