本文主要是介绍MATLAB-SSA-CNN-SVM,基于SSA麻雀优化算法优化卷积神经网络CNN结合支持向量机SVM数据分类(多特征输入多分类),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MATLAB-SSA-CNN-SVM,基于SSA麻雀优化算法优化卷积神经网络CNN结合支持向量机SVM数据分类(多特征输入多分类)
1.数据均为Excel数据,直接替换数据就可以运行程序。
2.所有程序都经过验证,保证程序可以运行。
3.具有良好的编程习惯,程序均包含简要注释。
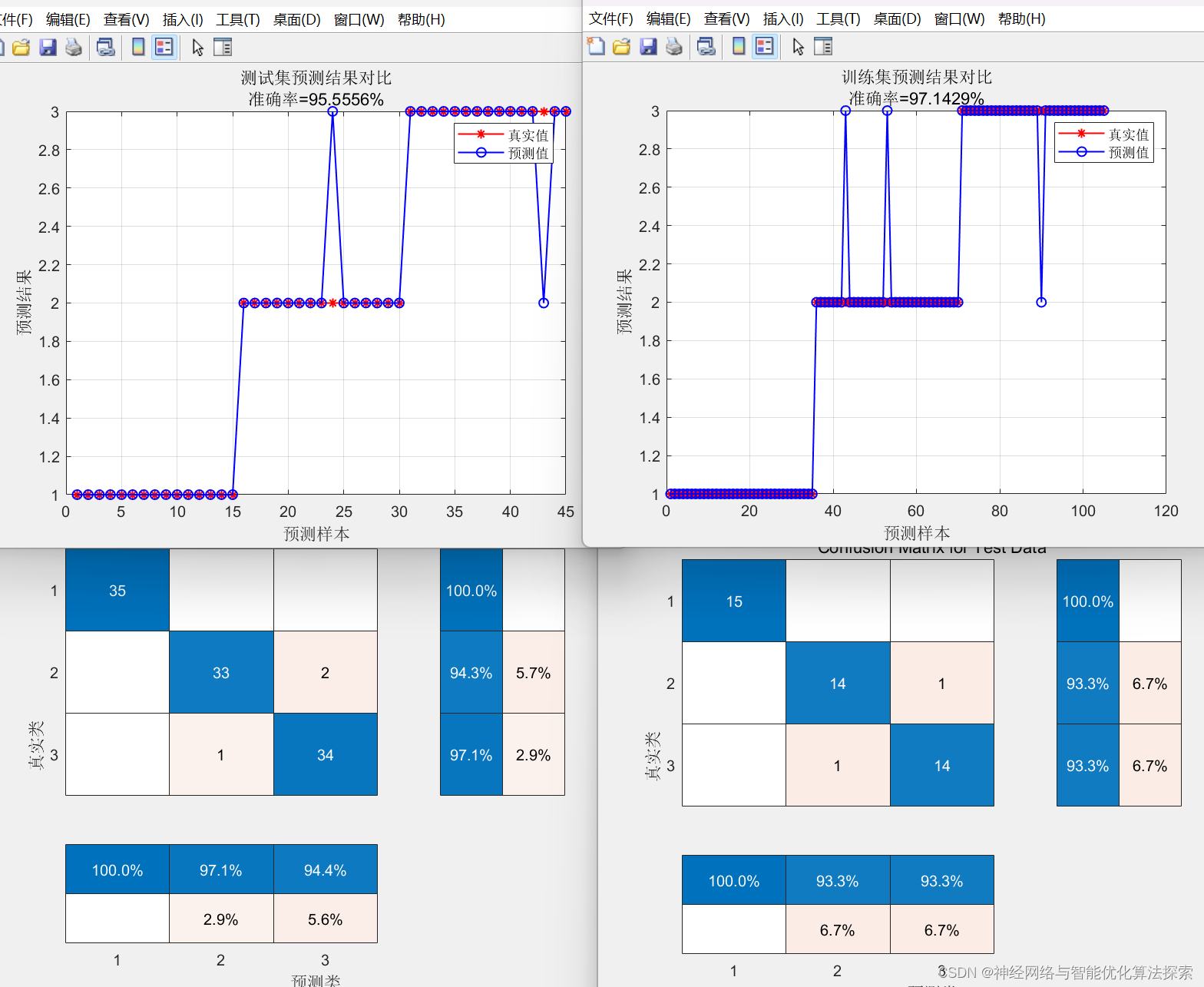
结果展示
获取方式
https://mbd.pub/o/bread/mbd-ZpeYkpZw这篇关于MATLAB-SSA-CNN-SVM,基于SSA麻雀优化算法优化卷积神经网络CNN结合支持向量机SVM数据分类(多特征输入多分类)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





