本文主要是介绍对红酒数据集,分别采用决策树算法和随机森林算法进行分类。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.导入所需要的包
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split2.导入数据,并且对随机森林和决策数进行对比
x_train,x_test,y_train,y_test=train_test_split(wine.data,wine.target,test_size=0.3)
clf=DecisionTreeClassifier(random_state=0)
rfc=RandomForestClassifier(random_state=0)
clf=clf.fit(x_train,y_train)
rfc=rfc.fit(x_train,y_train)
score_c=clf.score(x_test,y_test)
score_r=rfc.score(x_test,y_test)
print(score_c,score_r)运行结果:
0.8703703703703703 0.9259259259259259
3.数据可视化
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
%matplotlib inline
wine=load_wine()
rfc=RandomForestClassifier(n_estimators=25)
rfc_s=cross_val_score(rfc,wine.data,wine.target,cv=10)
clf=DecisionTreeClassifier()
clf_s=cross_val_score(clf,wine.data,wine.target,cv=10)
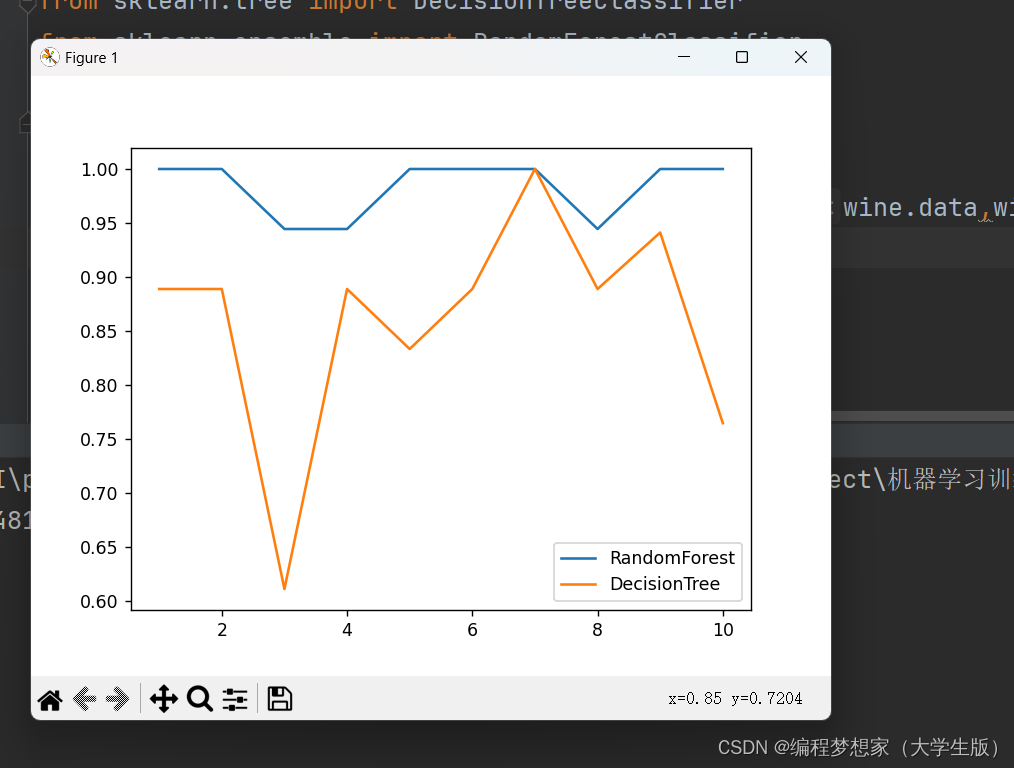
plt.plot(range(1,11),rfc_s,label='RandomForest')
plt.plot(range(1,11),clf_s,label='DecisionTree')
plt.legend()
plt.show()运行结果:
这篇关于对红酒数据集,分别采用决策树算法和随机森林算法进行分类。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





