本文主要是介绍Langchain中使用Ollama提供的Qwen大模型进行Function Call实现天气查询、网络搜索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Function Call,或者叫函数调用、工具调用,是大语言模型中比较重要的一项能力,对于扩展大语言模型的能力,或者构建AI Agent,至关重要。
Function Call的简单原理如下:
-
按照特定规范(这个一般是LLM在训练阶段构造数据的格式),定义函数,一般会包含函数名、函数描述,参数、参数描述、参数类型,必填参数,一般是json格式
-
将函数定义绑定的大模型上,这一步主要是让LLM感知到工具的存在,好在query来到时选取合适的工具
-
跟常规使用一样进行chat调用
-
检查响应中是否用tool、function之类的部分,如果有,则说明触发了函数调用,并且进行了参数解析
-
根据json中定义的函数名,找到Python中的函数代码,并使用大模型解析的参数进行调用,到这一步,一般已经拿到结果了
-
通常还会再增加一步,就是拿Python中调用函数的结果,和之前的历史记录,继续调用一次大模型,这样能让最终返回结果更自然
下面这张图简单描述了大语言模型函数调用的流程:
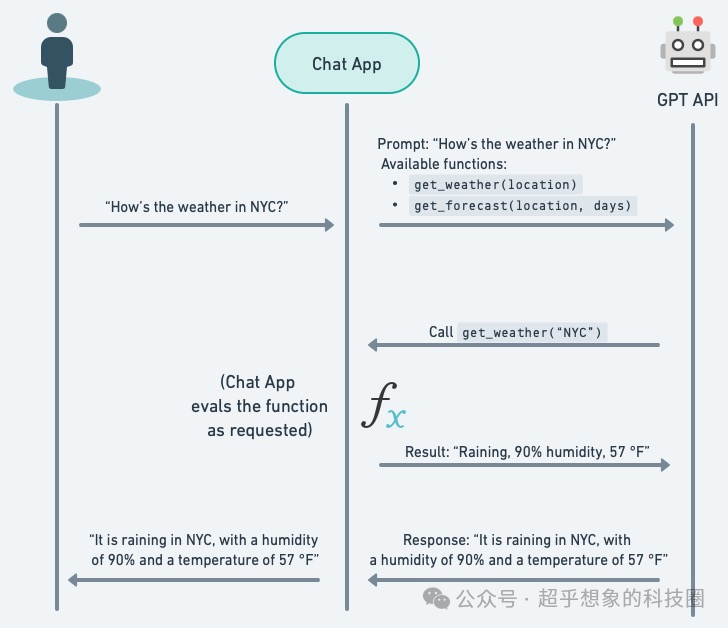
(图片来自:https://semaphoreci.com/blog/function-calling)
本文展示了如何使用Ollama中的Qwen大模型,进行函数调用。示例中共包含2个工具:
-
天气查询
-
搜索网络
预先准备工作:
-
安装Ollama
-
Ollama中下载大语言模型,通过
ollama pull qwen:14b即可下载,在本机运行这个模型推荐16G内存/显存,如果内存或显存不够,可以下载qwen:7b版本,但Function Call效果可能会下降 -
安装langchain, langchain-core, langchain-experimental
-
申请高德API,天气查询使用的是高德API
-
申请Tavily API Key,这是一个为LLM优化的搜索API,免费用户每月有1000次调用额度,地址https://tavily.com/,点击右上角的Try it out
请注意,更强大和更有能力的模型将在复杂的模式和/或多个功能下表现得更好。有关支持的模型和模型变体的完整列表,请访问此处https://ollama.ai/library。
pip install -q langchain\_experimental 为了保证可复现性,把使用到的核心库的版本打印如下:
import langchain\_experimental, langchain\_core for module in (langchain\_experimental, langchain\_core): print(f"{module.\_\_name\_\_:<20}\\t{module.\_\_version\_\_}") langchain_experimental 0.0.59langchain_core 0.2.0
0 准备API Key
amap\_api\_key = '此处填写高德API Key'
tavily\_api\_key = '此处填写Tavily API Key' 1 绑定工具
from langchain\_experimental.llms.ollama\_functions import OllamaFunctions model = OllamaFunctions(model='qwen:14b', base\_url='http://localhost:11434', format\='json') 1.1 定义工具
此处定义了2个工具,一个是网络搜索,一个是天气查询,其中天气查询要发送2次网络请求,首先根据城市名称拿到对应的行政区划码adcode,然后再使用adcode查询天气
def search\_web(query, k=5, max\_retry=3): import os from langchain\_community.retrievers import TavilySearchAPIRetriever os.environ\["TAVILY\_API\_KEY"\] = tavily\_api\_key retriever = TavilySearchAPIRetriever(k=5) documents = retriever.invoke(query) \# return \[{'title': doc.metadata\['title'\], 'abstract': doc.page\_content, 'href': doc.metadata\['source'\], 'score': doc.metadata\['score'\]} for doc in \# documents\] content = '\\n\\n'.join(\[doc.page\_content for doc in documents\]) prompt = f"""请将下面这段内容(<<<content>>><<</content>>>包裹的部分)进行总结:
<<<content>>>
{content}
<<</content>>>
""" print('prompt:') print(prompt) return model.invoke(prompt).content def get\_current\_weather(city): import requests from datetime import datetime url = f'https://restapi.amap.com/v3/config/district?keywords={city}&key={amap\_api\_key}' resp = requests.get(url) \# print('行政区划:') \# print(resp.json()) adcode = resp.json()\['districts'\]\[0\]\['adcode'\] \# adcode = '110000' url = f'https://restapi.amap.com/v3/weather/weatherInfo?city={adcode}&key={amap\_api\_key}&extensions=base' resp = requests.get(url) """样例数据 {'province': '北京', 'city': '北京市', 'adcode': '110000', 'weather': '晴', 'temperature': '26', 'winddirection': '西北', 'windpower': '4', 'humidity': '20', 'reporttime': '2024-05-26 13:38:38', 'temperature\_float': '26.0', 'humidity\_float': '20.0'} """ \# print('天气:') \# print(resp.json()) weather\_json = resp.json()\['lives'\]\[0\] return f"{weather\_json\['city'\]}{datetime.strptime(weather\_json\['reporttime'\], '%Y-%m-%d %H:%M:%S').strftime('%m月%d日')}{weather\_json\['weather'\]},气温{weather\_json\['temperature'\]}摄氏度,{weather\_json\['winddirection'\]}风{weather\_json\['windpower'\]}级" fn\_map = { 'get\_current\_weather': get\_current\_weather, 'search\_web': search\_web
} 1.2 绑定工具
使用下面的语句,将自定义的函数,绑定到大语言模型上
llm\_with\_tool = model.bind\_tools( tools=\[ { "name": "get\_current\_weather", "description": "根据城市名获取天气", "parameters": { "type": "object", "properties": { "city": { "type": "string", "description": "城市名,例如北京" } }, "required": \["city"\] } }, { "name": "search\_web", "description": "搜索互联网", "parameters": { "type": "object", "properties": { "query": { "type": "string", "description": "要搜素的内容" } }, "required": \["query"\] } }, \], \# function\_call={"name": "get\_current\_weather"}
) 2 使用工具
2.1 天气查询
from langchain\_core.messages import HumanMessage
import json ai\_msg = llm\_with\_tool.invoke("北京今天的天气怎么样")
kwargs = json.loads(ai\_msg.additional\_kwargs\['function\_call'\]\['arguments'\])
ai\_msg.additional\_kwargs {‘function_call’: {‘name’: ‘get_current_weather’,‘arguments’: ‘{“city”: “\u5317\u4eac”}’}}
kwargs {‘city’: ‘北京’}
fn\_map\[ai\_msg.additional\_kwargs\['function\_call'\]\['name'\]\](\*\*kwargs) ‘北京市05月26日晴,气温25摄氏度,西风≤3级’
下图是将函数调用集成到Chainlit中的效果
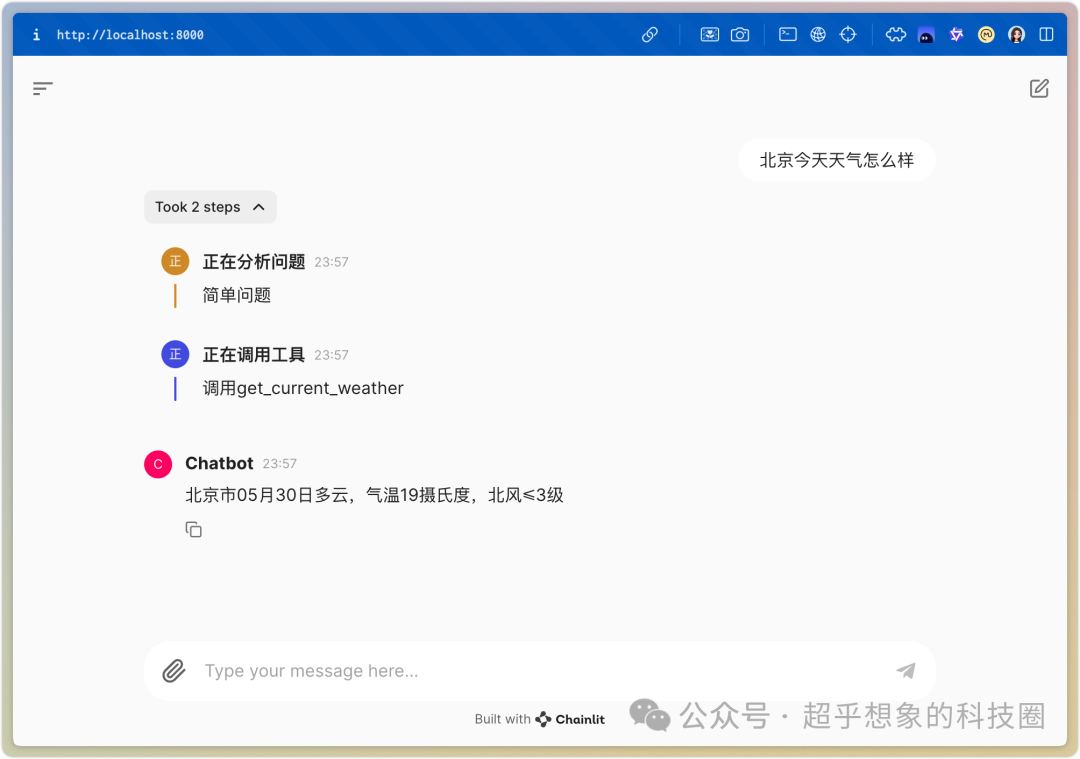
2.2 网络搜索
输入比较新的内容后,大语言模型会自动判断使用网络搜索工具
ai\_msg = llm\_with\_tool.invoke("庆余年2好看吗")
kwargs = json.loads(ai\_msg.additional\_kwargs\['function\_call'\]\['arguments'\]) ai\_msg AIMessage(content=‘’, additional_kwargs={‘function_call’: {‘name’: ‘search_web’, ‘arguments’: ‘{“query”: “\u5e86\u4f59\u5e742 \u597d\u770b\u5417 \u5f71\u8bc4”}’}}, id=‘run-15f85676-e800-40e1-88dc-eb99d1994091-0’)
kwargs {‘query’: ‘庆余年2 好看吗 影评’}
fn\_map\[ai\_msg.additional\_kwargs\['function\_call'\]\['name'\]\](\*\*kwargs) 输出结果:
prompt:请将下面这段内容(<<>><<>>包裹的部分)进行总结:<<>>庆余年2前5集观后感,优缺点浅评. 1~2集:前两集不太好看,因为看庆2之前我刚把第一季精编版刷完重温了一下剧情,感觉节奏和味道都不太对,没有庆1的节奏感,剧情很平,梗多,但是信息量很低,有些水,假死剧情逻辑上来说圆得很生硬,没什么必要 … 庆余年2开播这天,我给我自己放了一首《好日子》。因为点开第一集刚看了个开头,我就知道,属于我的2019年重新杀了回来。故事的接续感诚意十足,一点开就是张庆被催更,回扣整体的世界观,再跟随故事回到剧中,以同样的节奏同样的视角重现第一季的 … 微博讨论度也高得夸张,#庆余年 剧王#的词条直接登顶热搜,后面还挂了"爆"字,热度待遇堪比娱乐圈八卦,#庆余年2剧本写了约3年##庆余年 袁泉#等多个相关词条也一起上榜。微博讨论度 《庆余年2》书接上回,先需要揭开第一季结尾范闲被言冰云刺杀的悬念。 庆余年 第二季电视剧简介和剧情介绍,庆余年 第二季影评、图片、论坛 … 感觉这几年的期待就是个笑话,真的逃不脱第二季难看得宿命吗?… 庆余年2开播这天,我给我自己放了一首《好日子》。因为点开第一集刚看了个开头,我就知道,属于我的2019年重新杀 … 观众的打分和评价都一针见血_腾讯新闻. 《庆余年2》第一波真实口碑出炉!. 观众的打分和评价都一针见血. 等了5年,终于等到《 庆余年2 》惊喜开播了。. 而这部剧的首播当晚排面有多大呢?. 全网热度第一,热搜前十八个都和这部剧有关系。. 这个架势,不愧 …<<>> ‘《庆余年2》的开播似乎备受关注,首播当晚热度爆棚,登顶热搜榜首。观众们的反馈似乎既包含了期待又夹杂着对第一季结束后的剧情走向的揣测。然而,《庆余年2》能否延续并超越前作的口碑,还需时间给出答案。’
3 流式输出
与langchain_community.llms.ollama.Ollama中的Ollma类似,此处的OllamaFunctions依然支持流式输出,知识要注意,构造时如果传递了format参数,则会流式输出json
model = OllamaFunctions(model='qwen:14b', base\_url='http://localhost:11434', format\='json') for chunk in model.stream('介绍一下相对论'): print(chunk.content, end='') {“response”: [{“title”: “狭义相对论”,“description”: “由爱因斯坦提出,主要阐述物体在高速运动(接近光速)时的物理现象。它包括两个基本原理:相对性原理和光速不变原理。”},{“title”: “广义相对论”,“description”: “是狭义相对论的一个自然拓展,由爱因斯坦在1915年提出。它主要描述了引力的本质,将引力视为物体所处的时空弯曲的结果。广义相对论的成功预测包括水星近日点的进动以及光在强引力场中的偏折现象。”}]}
commmon\_model = OllamaFunctions(model='qwen:14b', base\_url='http://localhost:11434') for chunk in commmon\_model.stream('介绍一下相对论'): print(chunk.content, end='') 输出结果:
相对论是物理学中两个重要的理论体系:狭义相对论和广义相对论。 1. 狭义相对论(Special Relativity):- 由爱因斯坦在1905年提出,主要针对的是非加速运动的观察者。- 狭义相对论的主要结论包括:光速不变原理、时间膨胀效应和长度收缩效应。 2. 广义相对论(General Relativity):- 提出于1915年的爱因斯坦,是对狭义相对论的一个自然推广,用于描述引力。- 广义相对论的主要贡献包括:时空弯曲的概念、引力波的预言和黑洞理论的确立。 尽管广义相对论在许多情况下都取得了惊人的成功,但它仍然没有被完全接受。一些物理学家认为可能存在其他形式的引力,这些观点被称为量子引力理论。然而,这些问题目前仍然是物理学界的研究前沿。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。
这篇关于Langchain中使用Ollama提供的Qwen大模型进行Function Call实现天气查询、网络搜索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






