qwen专题

通义千问Qwen 2大模型的预训练和后训练范式解析
LLMs,也就是大型语言模型,现在已经发展得挺厉害的。记得最开始的时候,我们只有GPT这样的模型,但现在,我们有了一些更复杂的、开放权重的模型。以前,训练这些模型的时候,我们主要就是做预训练,但现在不一样了,我们还会加上后训练这个阶段。 咱们今天就以通义千问Qwen 2这个模型为例,来好好分析一下Qwen 2的预训练和后训练都是怎么搞的。它在大型语言模型界里算是挺能打的。不过,虽然它很强

LLM代码实现-Qwen(挂载知识库)
为什么要挂载知识库? LLM 在回答用户的问题时可能会产生幻觉,或者由于训练数据中不包含用户想要的内容而无法回答,通常情况下我们可以选择微调模型或者外挂知识库来缓解这类问题。微调模型的对数据和算力都有一定的要求,而知识库的门槛会更低一些,所以通常情况下会选择外挂知识库高效地来解决这类问题。 挂载知识库其实相当于引入外部知识,为了扩展语言模型以减少歧义,从大型文本数据库中检索相关文档。通常将输入

Qwen-7B-Chat大模型安装训练推理-helloworld
初始大模型之helloworld编写 开发环境:modelscope GPU版本上测试的,GPU免费36小时 ps:可以不用conda直接用环境自带的python环境使用 魔搭社区 安装conda wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh 1.2 bash Minicond

Qwen-VL模型微调及遇到的一些小问题
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。相比较前文提到的llava-llama3的模型,它相对更成熟一些,功能更强大一些。 比较有特点的功能: 多图交错对话:支持多图输入和比较,指定图片问答,多图文学创作等;
![[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇](https://i-blog.csdnimg.cn/direct/5cd8f3334ae74386b28c9736370a95f2.jpeg#pic_center)
[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇
[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - MultiModal篇 前情提要源码阅读导包逐行讲解 dataclass部分整体含义逐行解读 模型微调整体含义逐行解读 MultiModal类整体含义逐行解读 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 前情提要 有关多模态大模型架构中的语言模型部分
![[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - 语言模型篇(1)](/front/images/it_default.jpg)
[CLIP-VIT-L + Qwen] 多模态大模型源码阅读 - 语言模型篇(1)
多模态大模型源码阅读 - 语言模型篇(1) 吐槽今日心得MQwen.py 吐槽 想要做一个以Qwen-7B-Insturct为language decoder, 以CLIP-VIT-14为vision encoder的image captioning模型,找了很多文章和库的源码,但是无奈都不怎么看得懂,刚开始打算直接给language decoder加上cross attent
![[CLIP-VIT-L + Qwen] 多模态大模型学习笔记 - 5](/front/images/it_default2.jpg)
[CLIP-VIT-L + Qwen] 多模态大模型学习笔记 - 5
[CLIP-VIT-L + Qwen] 多模态大模型学习笔记 - 5 前情提要源码解读(visualModel类)init函数整体含义逐行解读 get_image_features函数(重构)整体含义逐行解读 main函数整体含义逐行解读 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 前情提要 有关多模态大模型架
Qwen-VL部署实操
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型的特点包括: 强大的性能:在四大类多模态任务的标准英文测评中(Zero-shot Captioning/VQA/DocVQA/Grounding)上,均取得同等通用模型大小下最好
CLIP-VIT-L + Qwen 多模态学习笔记 -3
多模态学习笔记 - 3 参考repo:WatchTower-Liu/VLM-learning; url: VLLM-BASE 吐槽 今天接着昨天的源码继续看,黑神话:悟空正好今天发售,希望广大coder能玩的开心~ 学习心得 前情提要 详情请看多模态学习笔记 - 2 上次我们讲到利用view()函数对token_type_ids、position_ids进行重新塑形,确保这些张量的最后

大模型应用实战3——开源大模型(以Qwen为例)实现多论对话功能
对于国内用户来说,一个比较稳定的下载和部署开源大模型的方法就是使用ModelScope的SDK进行下载,然后再Transformer库进行调用。在代码环境中,ollama则提供了openai API风格的大模型调用方法。在开启ollama服务情况下,我们只需要进一步在代码环境中安装openai库即可完成调用。目前都是用openai风格的api。 !pip install openai from

【多模态大模型教程】在自定义数据上使用Qwen-VL多模态大模型的微调与部署指南
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。 Qwen-VL-Chat = 大语言模型(Qwen-7B) + 视觉图片特征编码器(Openclip ViT-bigG) + 位置感知视觉语言适配器(可训练Adapter)+ 1.5B的图文数据

Langchain中使用Ollama提供的Qwen大模型进行Function Call实现天气查询、网络搜索
Function Call,或者叫函数调用、工具调用,是大语言模型中比较重要的一项能力,对于扩展大语言模型的能力,或者构建AI Agent,至关重要。 Function Call的简单原理如下: 按照特定规范(这个一般是LLM在训练阶段构造数据的格式),定义函数,一般会包含函数名、函数描述,参数、参数描述、参数类型,必填参数,一般是json格式 将函数定义绑定的大模型上,这一步主要是让LL

Qwen-VL图文多模态大模型LoRA微调指南
大模型相关目录 大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容 从0起步,扬帆起航。 大模型应用向开发路径:AI代理工作流大模型应用开发实用开源项目汇总大模型问答项目问答性能评估方法大模型数据侧总结大模型token等基本概念及参数和内存的关系大模型应用开发-华为大模型生态规划从零开始的LLaMA-Factor

Qwen-Agent:Qwen2加持,强大的多代理框架 - 函数调用、代码解释器以及 RAG!
✨点击这里✨:🚀原文链接:(更好排版、视频播放、社群交流、最新AI开源项目、AI工具分享都在这个公众号!) Qwen-Agent:Qwen2加持,强大的多代理框架 - 函数调用、代码解释器以及 RAG! 🌟 Qwen-Agent是一个开发框架。开发者可基于该框架开发 Agent应用 ,充分利用基于通义千问模型(Qwen)的指令遵循、工具使用、规划、记忆能力。该项目也提供了浏览器助手、代

【LLM Agent 长文本】Chain-of-Agents与Qwen-Agent引领智能体长文本处理革命
前言 大模型在处理长文本上下文任务时主要存在以下两个问题: 输入长度减少:RAG的方法可以减少输入长度,但这可能导致所需信息的部分丢失,影响任务解决性能。扩展LLMs的上下文长度:通过微调的方式来扩展LLMs的上下文窗口,以便处理整个输入。当窗口变长时,LLMs难以集中注意力在解决任务所需的信息上,导致上下文利用效率低下。 下面来看看两个有趣的另辟蹊径的方法,使用Agent协同来处理长上下文
Qwen等大模型使用 vLLM部署详解
部署Qwen时尝试使用 vLLM。易于使用且具有最先进的服务吞吐量、高效的注意力键值内存管理(通过PagedAttention实现)、连续批处理输入请求、优化的CUDA内核等功能。 参考链接https://qwen.readthedocs.io/zh-cn/latest/deployment/vllm.html 1 vLLM离线推理代码 Qwen2代码支持的模型都被vLLM所支持。 vLLM最
创新实训2024.06.03日志:完善Baseline Test框架、加入对Qwen-14B的测试
1. Baseline Test框架重构与完善 在之前的一篇博客中(创新实训2024.05.29日志:评测数据集与baseline测试-CSDN博客),我介绍了我们对于大模型进行基线测试的一些基本想法和实现,包括一些基线测试的初步结果。 后来的一段时间,我一直在试图让这个框架变得更加可用、可扩展、可移植,因为我们想加入更多的大模型(无论在线离线、无论哪个组织开源的、无论多少超参数)进行基线测试

Qwen-VL论文阅读
论文地址 其他同学的详细讲解 模型结构和参数大小 (1)LLM:Qwen-7B (2)Vision Encoder:ViT架构,初始化参数是 Openclip’s ViT-bigG。 在训练和推理过程中,输入的图像都被调整到特定的分辨率。 视觉编码器通过将图像分割成步长为14 的块来处理图像,从而生成一组图像特征。 「 224 / 14 = 16 16 x 16 = 256」 (3
Qwen 微调LoRA之后合并模型,使用 webui 测试
Qwen 微调LoRA之后合并模型 qwen_lora_merge.py : import osfrom peft import AutoPeftModelForCausalLMfrom transformers import AutoTokenizerdef save_model_and_tokenizer(path_to_adapter, new_model_directory):""
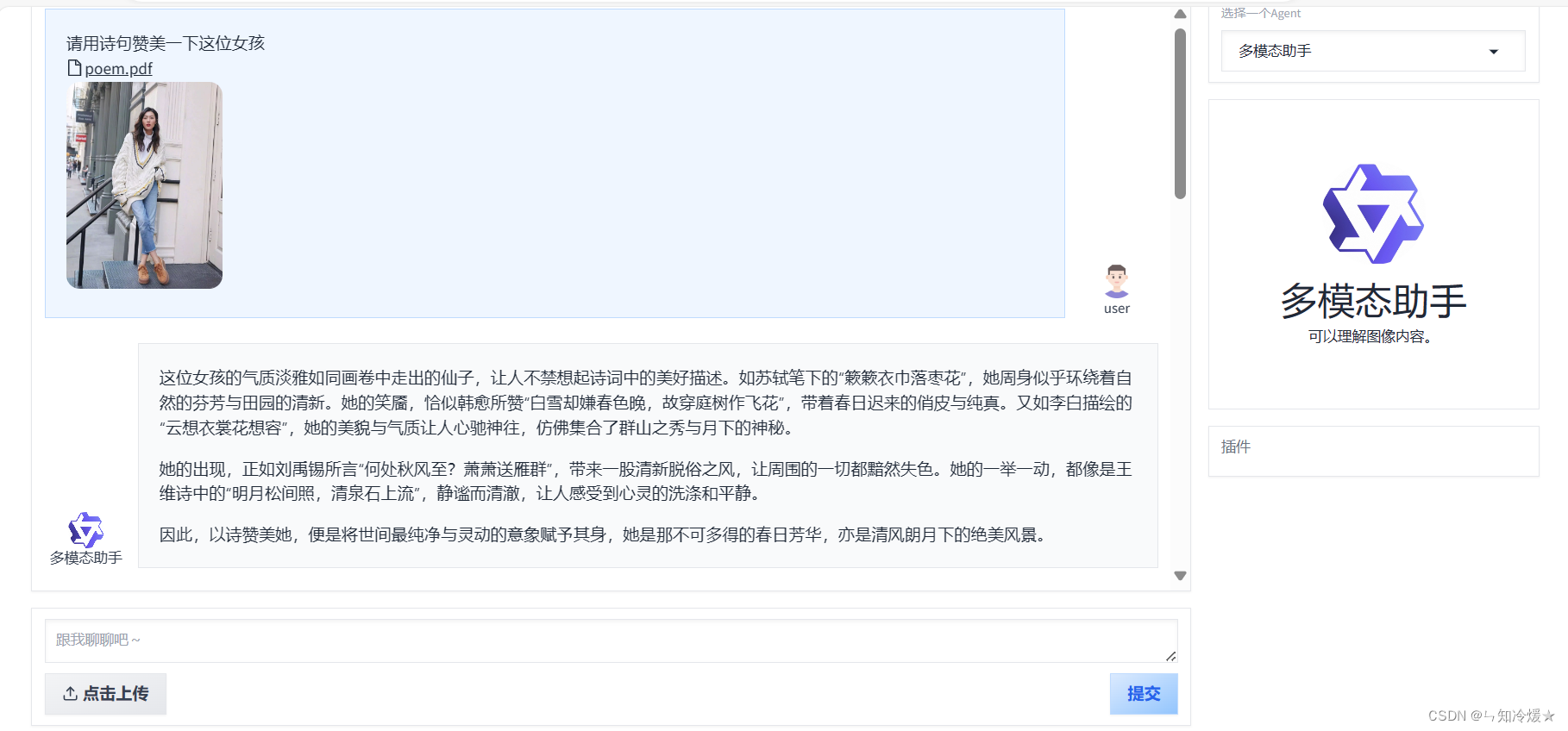
【通义千问—Qwen-Agent系列2】案例分析(图像理解图文生成Agent||多模态助手|| 基于ReAct范式的数据分析Agent)
目录 前言一、快速开始1-1、介绍1-2、安装1-3、开发你自己的Agent 二、基于Qwen-Agent的案例分析2-0、环境安装2-1、图像理解&文本生成Agent2-2、 基于ReAct范式的数据分析Agent2-3、 多模态助手 附录1、agent源码2、router源码 总结 前言 Qwen-Agent是一个开发框架。开发者可基于本框架开发Agent应用,充分利用基
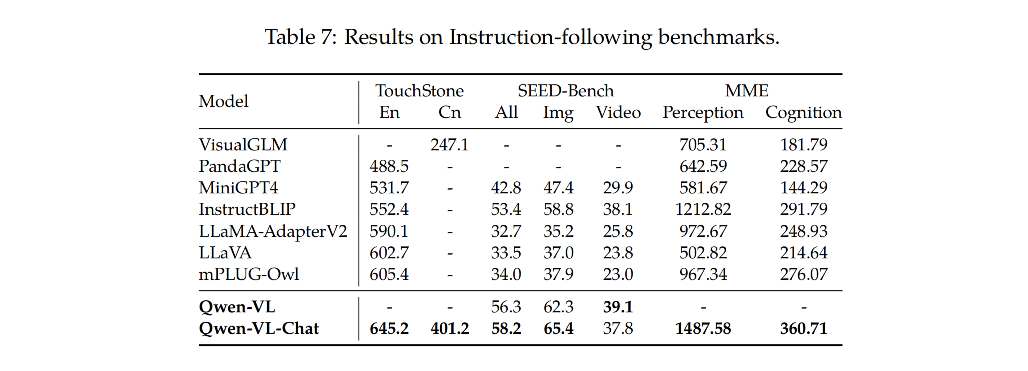
【多模态】31、Qwen-VL | 一个开源的全能的视觉-语言多模态大模型
文章目录 一、背景二、方法2.1 模型架构2.2 输入和输出2.3 训练 三、效果3.1 Image Caption 和 General Visual Question Answering3.2 Text-oriented Visual Question Answering3.3 Refer Expression Comprehension3.4 视觉-语言任务的少样本学习3.5 真实世

Qwen-VL环境搭建推理测试
引子 这几天阿里的Qwen2.5大模型在大模型圈引起了轰动,号称地表最强中文大模型。前面几篇也写了QWen的微调等,视觉语言模型也写了一篇CogVLM,感兴趣的小伙伴可以移步Qwen1.5微调-CSDN博客。前面也写过一篇智谱AI的视觉大模型(CogVLM/CogAgent环境搭建&推理测试-CSDN博客)。Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Langua

【通义千问系列】Qwen-Agent 从入门到精通【持续更新中……】
目录 前言一、快速开始1-1、介绍1-2、安装1-3、开发你自己的Agent 二、Qwen-Agent的使用和开发过程2-1、Agent2-1-1、Agent使用2-1-2、Agent开发 2-2、Tool2-2-1、工具使用2-2-2、工具开发 2-3、LLM2-3-1、LLM使用2-3-2、LLM开发 三、基于Qwen-Agent的案例分析3-1、3-2、 总结 前言
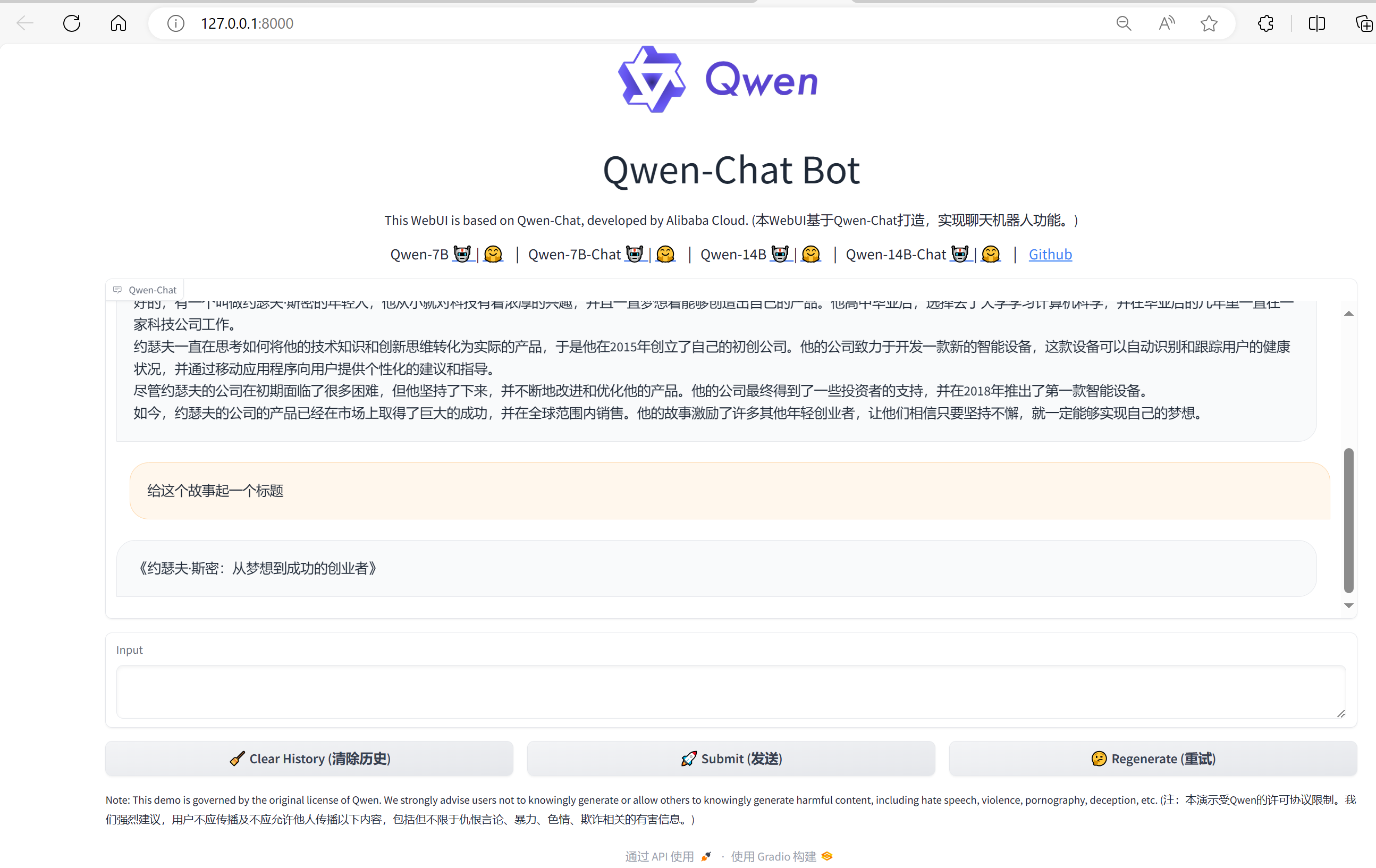
Qwen大模型实践之初体验
Qwen大模型实践之初体验 测试机器, 使用InternStudio提供的开发机,配置如下: 部分资源详细信息: # CPUIntel(R) Xeon(R) Platinum 8369B CPU @ 2.90GHz# GPU(base) root@intern-studio-50014188:~# studio-smi Running studio-smi by vgpu-smiWed M

Qwen大模型实践之量化
Qwen大模型实践之量化 接上篇内容。 1. AutoGPTQ量化 提供了基于AutoGPTQ的量化方案,并开源了Int4和Int8量化模型。量化模型的效果损失很小,但能显著降低显存占用并提升推理速度。 以下我们提供示例说明如何使用Int4量化模型。在开始使用前,请先保证满足要求(如torch 2.0及以上,transformers版本为4.32.0及以上,等等),并安装所需安装包: pip i