本文主要是介绍【纯干货级教程】深度学习/目标检测训练出的loss曲线应该怎么观察分析判断?——以YOLOv5/v7为例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
相信很多刚刚接触目标检测系列算法小伙伴跑深度学习算法时会有许多困惑,比如训练得出的loss曲线有什么意义?选择哪个算法模型作为baseline、选择哪个参数量/复杂度/深度的模型进行训练最为合适?
本文主要从训练过程中、训练得出的结果文件来进行阐述如何对自己的模型进行精进。
当然,本文在阐述的时候可能会存在结论。不全的情况,若你有相关疑问,欢迎在评论区批评指正、互相交流!我也会在后续持续进行更新完来完善该文章,欢迎关注。
一、训练得出的loss曲线有什么作用?
在训练结束后,通常会输出loss曲线,它是一种工具,能够帮助我们用以判断训练的好坏。
以yolov5/v7为例,loss曲线通常输出trainloss和valloss
输出的loss曲线通常会有以下特征。
1.正常收敛
现象描述:train和val的曲线均趋于平缓,指标的值也趋于平缓,虽然train看起来还未收敛(主要原因是我没认真去调~)。同时,示例图片有些波动,但这其实是数据集较少的原因导致,此情况见第6点。

2.没有完全收敛(欠拟合)
现象描述:曲线没有下降到趋于平缓的情况。此处的val乍一看开始是下降了然后趋于平缓,但这是视觉上的问题,本质上忽略掉前几个epoch则可发现val仍在下降,且下降地不完全明显。同时,四个指标的趋势仍在上升,将其数据单独拿出则可明白仍未收敛。
解决方法:加大epoch、加大batchsize、换用更深的模型、很难拟合的情况尝试加载预训练权重、加大数据集评估结果较差的那个类别的图片数量。


3.过拟合
现象描述:如图,指标的曲线正常下降趋于平缓甚至逐渐降低,而val由正常下降再平缓再趋于上升,这是一个典型的过拟合情况。
解决方法:减少epoch、减少batchsize、增加数据集数据量(一般不这样做)、减小网络复杂度、减小层数、更换参数量较低的模型如YOLOv5x转YOLOv5s测试。
4.过早收敛
现象描述:乍一看曲线很平滑,也趋于收敛。但仔细观察,在约第20个epoch时,模型快速收敛,这或许说明采用的模型深度太深、数据集太过简单(也侧面反映了模型深度深过于复杂)、batchsize过高。
解决方法:降低batchsize、换参数量、深度较小的模型或对某些模块进行删除修改或替换轻量化模块等、降低学习率。
若你的数据集本来就很简单,则属于正常收敛,但若你的数据集并不小,如有几千、几万张,则考虑上述解决方法。

5.训练失败
(此处就不配图了,博主暂时没遇到这种情况,请根据现象描述进行判断)
现象描述:曲线乱跳、没有指标输出(均为0)
这种情况的train和val的曲线趋势相同,几乎都是一条水平的直线,并且虽然花了时间训练、训练过程中没有报什么错,但模型在本次训练中几乎没有学习到什么。该现象存在以下原因:
当在不对拉取的项目文件做修改时,往往是数据集的原因,数据集出现了严重的标注错误、类别混淆等。
数据集数量太小,选择的epoch也很少,不足以支持学习。
检测的类别的模样相差很大,但却标注了同一类名称,目标较难识别。这种情况需要对数据集进行重新设计。
项目文件存在缺陷,这种情况通过
解决方法:先检查数据集,这通常绝大部分原因是数据集的问题(尤其是数量、质量)。确认无误后尝试更换优化器。再测试别的对比试验,实在不行就放弃该实验采用别的实验,节约时间。
6.曲线震荡幅度大
现象描述:曲线不是很平滑规整、同时指标也不是很平滑规整。
解决方法:加大数据集的数据量,略微增加epoch。
7.train和val均升高
现象描述:这种情况通常train和val的loss图像都是向上的,指标很差或直接为0。这种情况博主也没遇到过,故不配图。
解决方法:若是自己设计的网络,检查模型是否存在问题,是否合理。检查自己配置文件的参数设置是否正常。检测数据集是否存在严重质量上的问题。
正常会遇到的情况绝大多数是:过拟合、欠拟合。
很多时候盲目增大batchsize、epoch反而会降低评估的结果。
同时,看loss曲线的变化并不能百分百判断出遇到的情况,博主建议大家一点一点地做修改,一次解决一个问题测试后再解决,一步一步排错,方能完美地解决问题。
二、一些心得:如何最大情况地避免训练过程中出现问题?我们在训练前应该做到什么?
1.明确目的
意思是你进行训练要做什么用?工业或是科研?以科研为例,分析你的场景需求是否适合讲故事,自己能否说得通等,分析比如你在疫情期间去写检测口罩的论文会更好通过,现在显然作用没有之前那么大。
2.选择合适的数据集
选择数据集的时候重点关注数据集是否存在标注错误、图像质量如何、图像数量是否足够支撑一篇论文所需的量、数据文件大小是否适合你的机器等。
及时排除能省不少事。如RSOD数据集就存在标注错误,这很可能会对你的训练结果产生一定影响。
3.先测对比试验
选择合适的baseline作为你的改进基础,据此进行改进。笔者曾在SSDD进行实验,当我测试其在YOLOv7-tiny的训练结果时在83左右正常收敛,输出曲线也并无什么异常,于是直接进行魔改,测试了一段时间涨点百分之11后一测对比试验,结果只打过了YOLOv5-n,于是惨遭失败。因此,为了节约时间,一定要注意自己的步骤。
4.制定计划
改进过程中,最好自己先制定一个计划,设计一个表格来展示你的Precision、Recall、map@0.5、map@0.5:.95、F1分数以及GFLOPS,据此做出对比与参考,同时对实验出的文件进行留样,选择必要的文件进行存储,并用以说明实验时发现的问题等。
5.详细分析
对自己的baseline进行分析,主要是对自己的loss曲线做分析,根据第一大点分析收敛地是否合理,曲线是否足够平滑。
完成上述步骤后,则可以尽量减少实验出现的失误以节约时间。
三、补充:我们在训练过程中得出的文件重点要关注什么?——以YOLOv5/v7为例
若直接以YOLOv7的项目文件为基础不做多余的修改进行训练,将会得出以下文件

其中我们需要重点关注的文件有:
1.weights文件夹下的best.pt/last.pt
如图所示,其中best.pt用于存放你目前评估结果最佳的模型权重,last.pt用于存放你训练中断或结束后的最后一个已经评估完成的epoch,主要用于断点重训,在项目文件的train.py中将resume设为true即可断点重训。当你需要这么做的时候请看点

2.confusion_matrix
混淆矩阵通过计算基于混淆矩阵的各种性能指标,如准确率、召回率、精确率、F1分数以及mAP(Mean Average Precision)等,可以全面评估目标检测模型在不同类别上的表现。
也能够直接展示出哪些类别被频繁误分类或漏检,有助于识别模型在特定类别上的弱点,尤其是在类别分布不均的数据集中。
通过分析混淆矩阵,我们可以针对性地优化模型,比如对频繁产生假正例的类别调整分类阈值,或对特定类别增加训练数据以提高模型的泛化能力。
通常只有完全训练结束后才会生成这个文件(即中途中断训练又不断点重训则不会生成)

3.F1_curve
F1分数作为精确率和召回率的调和平均值,能够综合评估模型在这两方面的表现,帮助找到一个二者之间的平衡点。
有些时候,某些类别的对象可能远多于其他类别,导致模型倾向于预测该类别而忽视其他数量较少的类别。F1分数在这种情况下尤为有用,因为它不会像准确率那样受到类别频率的影响,可以更公平地评估模型在所有类别上的表现。
同时,在比较不同的目标检测算法或模型时,F1分数提供了一个统一的标准,使得不同方法的性能可以直接进行对比。
通常只有完全训练结束后才会生成这个文件(即中途中断训练又不断点重训则不会生成)
如图的F1分数最佳值为0.76,而0.618应为面积比。

4.hyp.yaml/opt.yaml
用于存放你训练过程中设置的参数。

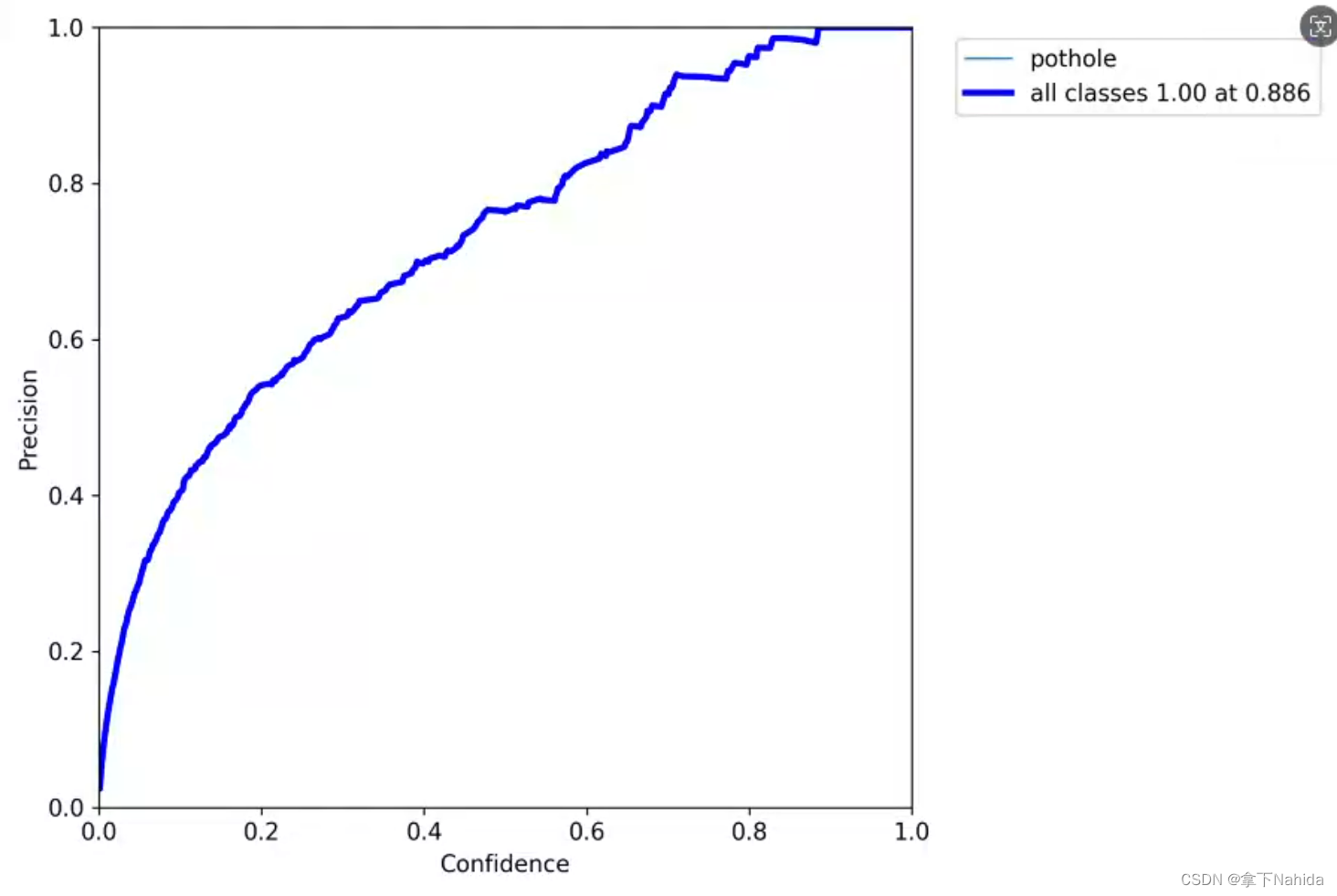
5.P_curve
通常只有完全训练结束后才会生成这个文件(即中途中断训练又不断点重训则不会生成)
展示了你的Precision曲线。
6.R_curve
通常只有完全训练结束后才会生成这个文件(即中途中断训练又不断点重训则不会生成)
展示了你的Recall曲线。

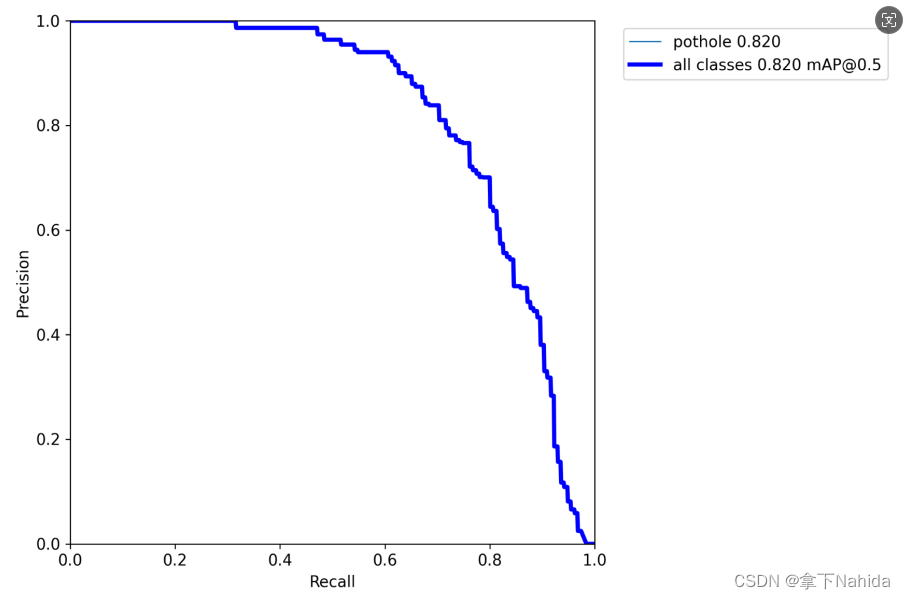
7.PR_curve
通常只有完全训练结束后才会生成这个文件(即中途中断训练又不断点重训则不会生成)
展示了你的P-R曲线。
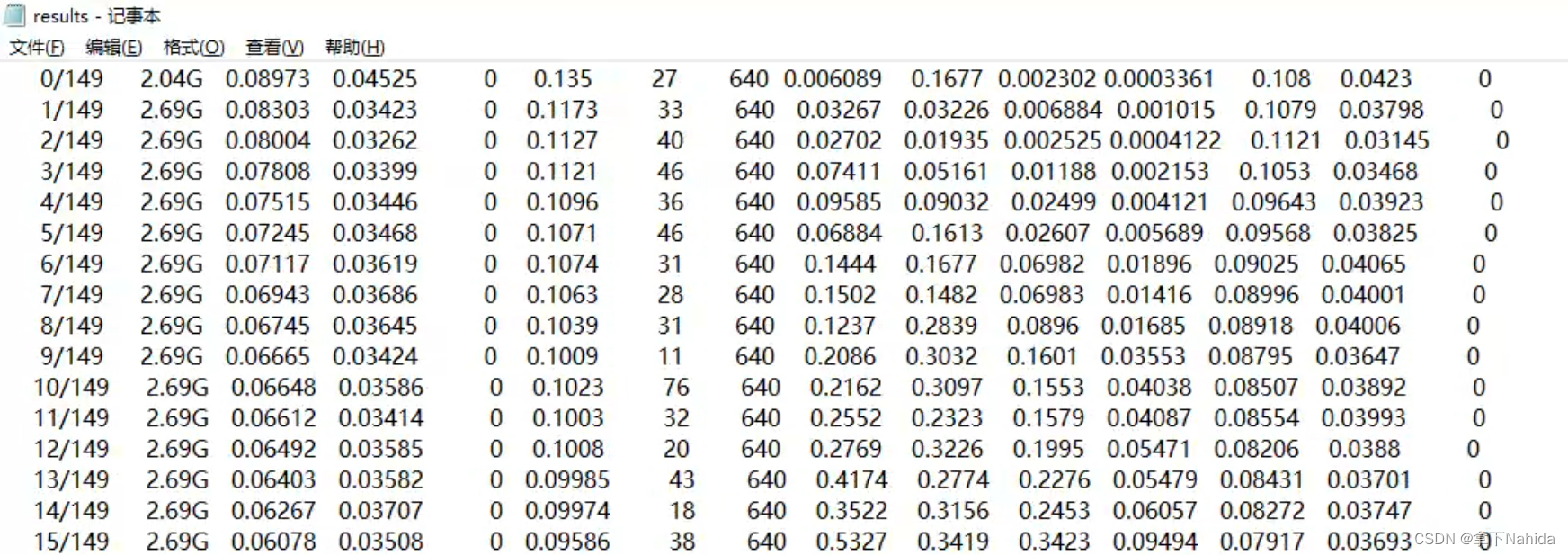
8.results.txt
用于展示你训练过程中的各个数据输出,比如train_loss、val_loss以及四个指标Precision、Recall、map@0.5、map@0.5:.95,输入图像尺寸以及epoch结束的最后一个标签加载数(该数字可用于定位是否发生了断点训练)
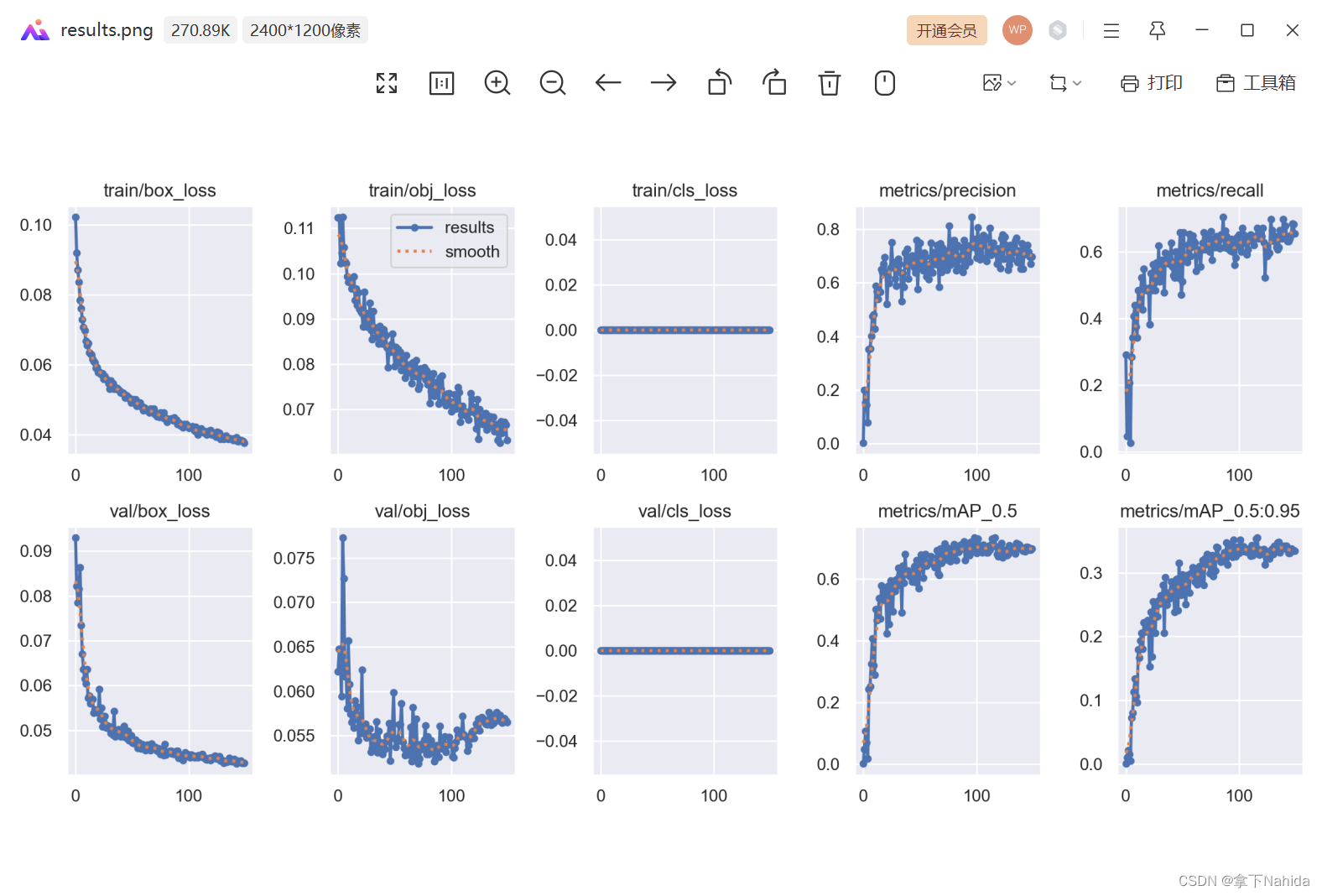
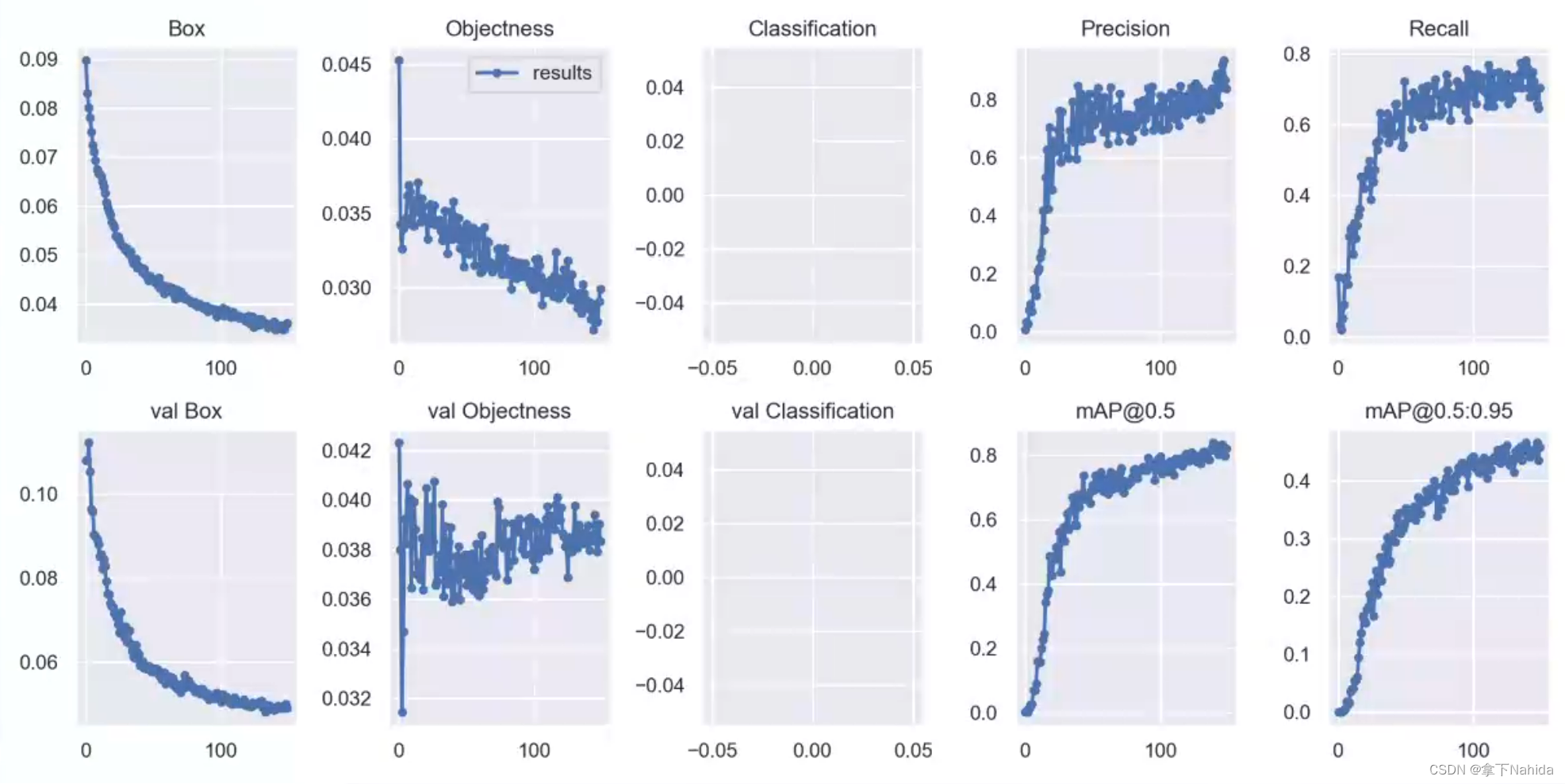
9.results.png
用于展示results.txt的文件,通常只有完全训练结束后才会生成这个文件(即中途中断训练又不断点重训则不会生成)。
当你的类别数为1时,classification则为一条直线或如图所示的情况
这篇关于【纯干货级教程】深度学习/目标检测训练出的loss曲线应该怎么观察分析判断?——以YOLOv5/v7为例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






