本文主要是介绍Stable Diffusion: ControlNet Openpose,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一文已经介绍了ControlNet的安装,点击右边的三角箭头。
-
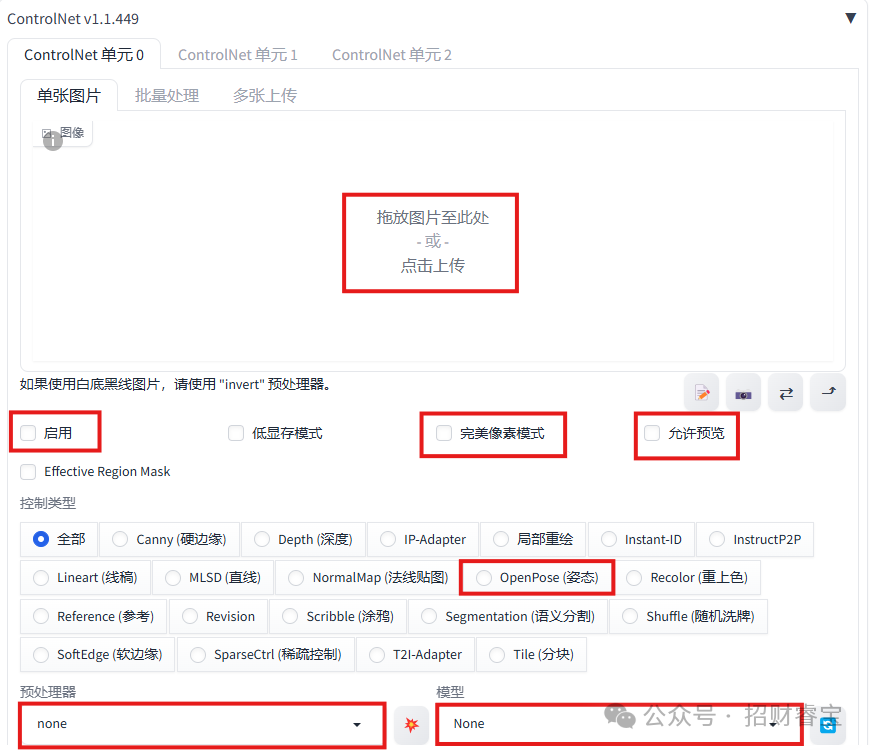
拖放原始姿态图片。
-
勾选“启用”,“完美像素模式”,“允许预览”
-
控制类型选择“OpenPose(姿态)”
-
预处理器选“openpose_full”,会对原始姿态图片做整体分析
(也可以选“openpose_face”,“openpose_hand”等,就会有选择地分析识别,而忽略手部或脸部识别等)
-
模型部分会自动选择(例如control_v11p_sd15_openpose ),取决于已经下载并保存在models\ControlNet目录下有哪些相关的模型。
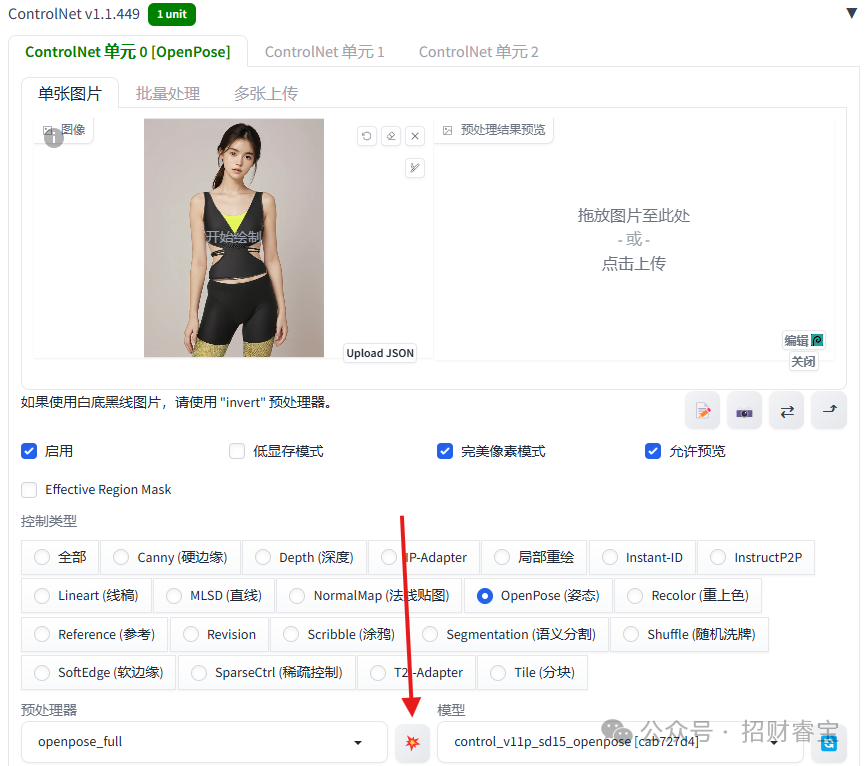
这个时候看起来是这个样子的,点击预处理器旁边的按钮
系统会自动生成骨骼图(包括脸部的关键点都是识别得非常清楚)
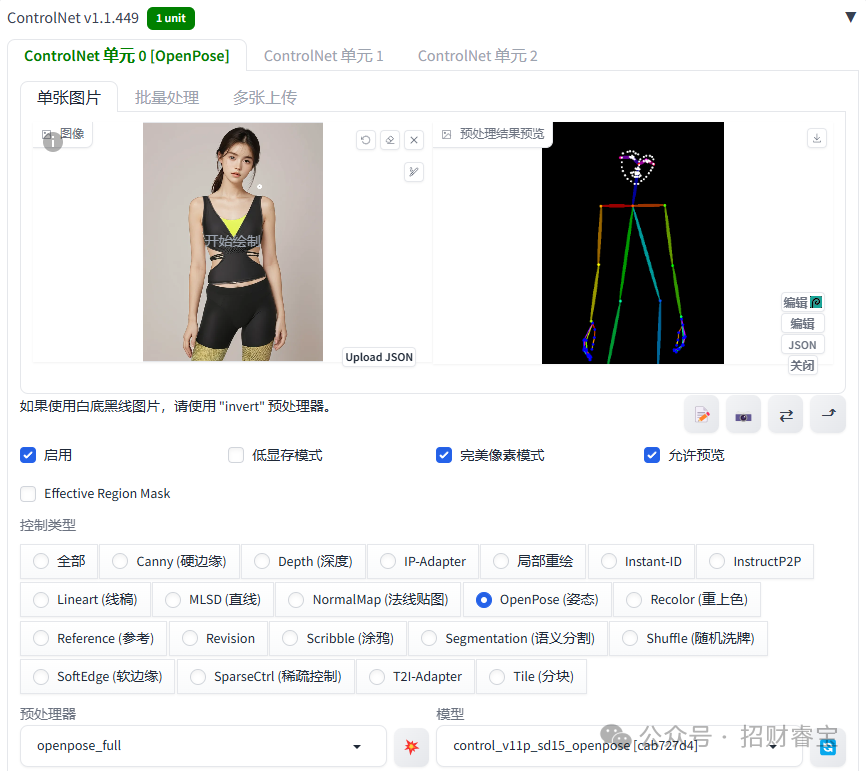
填入提示词,注意修改宽度和高度,与原始姿态图保持一致。
点击生成按钮。

这篇关于Stable Diffusion: ControlNet Openpose的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!