本文主要是介绍StyleGAN和Diffusion结合能擦出什么火花?PreciseControl:实现文本到图像生成中的精确属性控制!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
之前给大家介绍过CycleGAN和Diffusion结合的一项优秀的工作,感兴趣的小伙伴可以点击以下链接阅读~
图像转换新风尚!当CycleGAN遇到Diffusion能擦出什么火花?CycleGAN-Turbo来了!
今天给大家介绍StyleGAN和Diffusion结合的一项工作PreciseControl,通过结合扩散模型和 StyleGAN 实现文本到图像生成中的精确属性控制,该文章已经发表在ECCV2024.

亮点直击
-
通过在丰富的 W+ 潜在空间上调节 T2I,首次将大型文本到图像模型与 StlyeGAN2 相结合。
-
使用单个肖像图像的有效个性化方法,可在 W+ 空间中进行细粒度属性编辑,并使用文本提示进行粗略编辑。
-
将多个个性化模型与链式扩散过程融合在一起,实现多人构图的新颖方法。
相关链接
论文链接:https://arxiv.org/pdf/2408.05083
工程主页:https://rishubhpar.github.io/PreciseControl.home/
git链接:https://github.com/rishubhpar/PreciseControl
论文阅读

PreciseControl:通过细粒度属性控制增强文本到图像的扩散模型
摘要
最近,我们看到大量个性化方法用于文本到图像 (T2I) 扩散模型,这些模型使用少量图像来学习概念。现有方法在用于人脸个性化时,难以在保留身份的情况下实现令人信服的反转,并且依赖于对生成的脸部进行基于语义文本的编辑。但是,面部属性编辑需要更细粒度的控制,而仅使用文本提示很难实现这一点。相比之下,StyleGAN 模型可以学习丰富的面部先验知识,并通过潜在操作实现对细粒度属性编辑的平滑控制。
这项工作使用 StyleGAN 解开的W +空间来调节 T2I 模型。这种方法使我们能够精确地操纵面部属性,例如平滑地引入微笑,同时保留 T2I 模型固有的现有粗略文本控制。为了在W +空间上调节 T2I 模型,我们训练了一个潜在映射器,将潜在代码从W +转换为 T2I 模型的标记嵌入空间。所提出的方法在保留属性的情况下对人脸图像进行精确反转方面表现出色,并且有助于对细粒度属性编辑进行持续控制。此外,我们的方法可以轻松扩展以生成涉及多个个体的合成图。我们进行了大量实验来验证我们的方法在人脸个性化和细粒度属性编辑方面的有效性。
方法
方法概述

个性化框架。 给定一张肖像图像,我们从编码器 EGAN 中提取其w 潜在表示。潜在 w 连同扩散时间步长t通过潜在适配器 M生成一对时间相关的 token 嵌入 (v1t, v2t),代表输入主题。最后,将 token 嵌入与任意提示相结合以生成定制图像。
个性化

给定一张肖像图像,我们从编码器E GAN中提取其w潜在表征。潜在w连同扩散时间步长t一起通过潜在适配器M生成一对表示输入主题的时间相关标记嵌入 ( v t 1 , v t 2 )。最后,将标记嵌入与任意提示相结合以生成定制图像。
属性编辑/控制

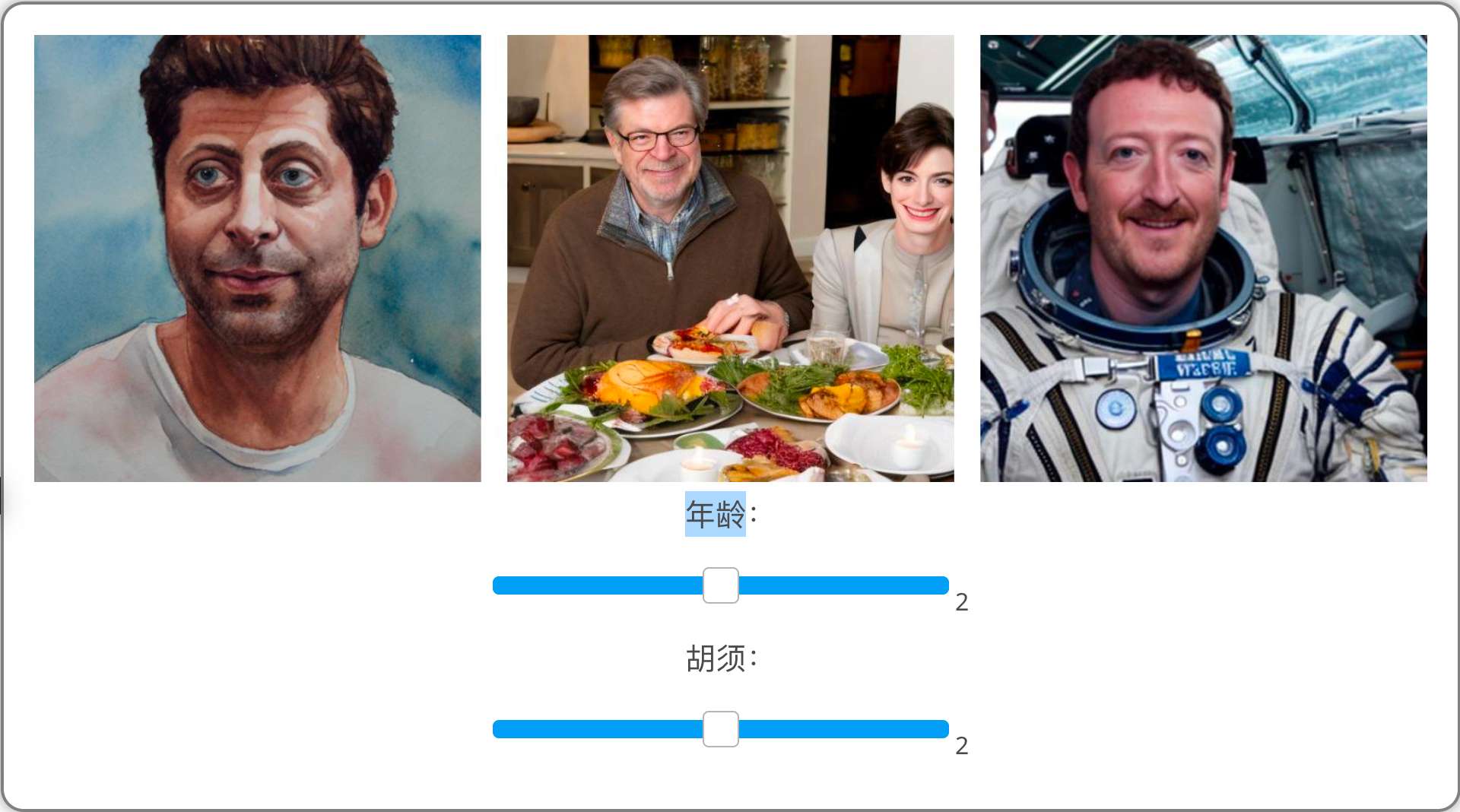
将给定的输入图像映射到w个潜在代码,然后按全局线性属性编辑方向移动该潜在代码以获得已编辑的潜在代码w *。然后将已编辑的潜在代码w *传递到 T2I 模型以获得细粒度的属性编辑。标量编辑强度参数β可以更改以获得连续的属性控制。我们的方法对各种属性执行解开的编辑,同时保留身份并推广到自然人脸、风格和多人。身份插值。我们可以通过在相应的w代码之间进行插值来在身份之间执行平滑插值。
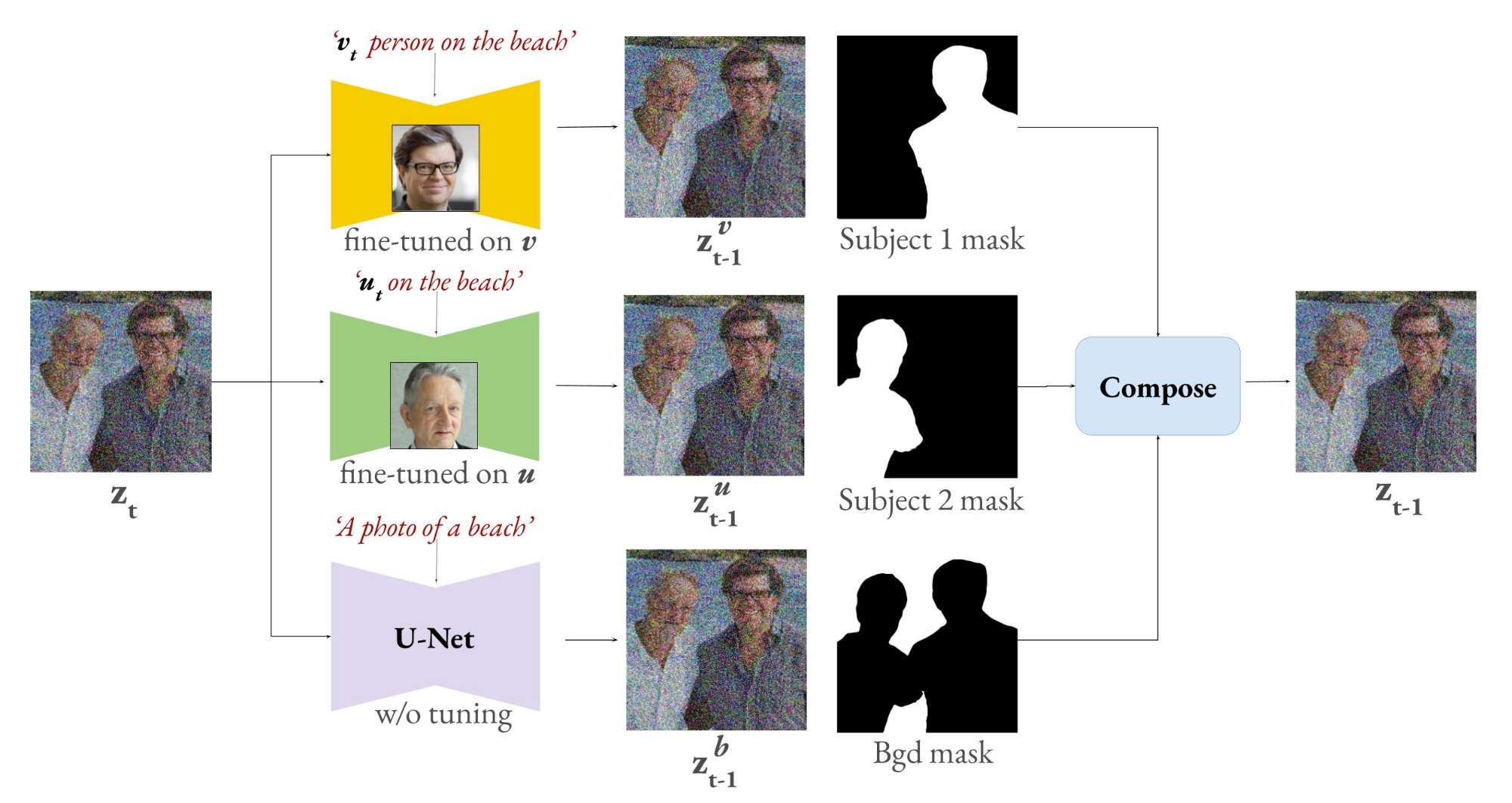
创作多个主题
我们运行多个并行扩散过程,每个主体一个,背景一个,并在每个去噪步骤中使用实例分割掩码将它们融合。实例掩码可以由用户提供,也可以通过同一 T2I 模型分割两个主体的生成图像来获得。请注意,每个主体的扩散过程都会通过其相应的微调模型,从而实现出色的身份保存。
实验
虚拟人像生成

编辑身份属性信息
多人物结合

附加编辑说明
使用从 InterfaceGAN 获得的编辑方向执行属性编辑。编辑方向在 T2I 模型中具有良好的泛化能力,表明任何现成的 StyleGAN 编辑方法都可轻松集成到我们的框架中。

多人属性控制
我们可以在场景中以最小的纠缠对单个角色进行连续编辑。观察不同属性的平滑编辑转换,同时保留身份。

面部修复

解开的W +潜在空间是 StyleGAN 中出色的面部先验。利用这一点,我们使用 StyleGAN 编码器将损坏的面部图像投影到W +潜在空间中来调节 T2I 模型,从而执行面部恢复。生成的图像看起来很逼真,可以使用 T2I 功能嵌入和编辑。对此类损坏图像进行个性化设置具有挑战性,因为模型很容易过度拟合给定的单脸图像。
草图到图像
我们使用经过训练的 psp StyleGAN 编码器将边缘图像映射到W +潜在空间,以生成草图到图像。然后可以使用获得的 𝕊 潜在代码来调节 T2I 模型以生成真实图像。

结论
结论。 我们提出了一个新颖的框架,用于在 StyleGAN2 模型的 W+ 空间上对 T2I 扩散模型进行条件化,以实现细粒度属性控制。具体来说,我们学习了一个潜在映射器,它将潜在代码从 W+ 投影到使用去噪、正则化和身份保留损失学习的 T2I 模型的输入标记嵌入空间。该框架提供了一种自然的方式来嵌入真实面部图像,方法是使用 GAN 编码器模型获取其潜在代码。然后可以以两种方式编辑嵌入的面部 - 基于粗略文本的编辑和通过 W+ 中的潜在操作进行细粒度属性编辑。
限制。 主要限制是 W+ 中基于编码器的反转在某些信息上比较松散,因此我们需要进行几次迭代的测试时间微调以恢复类似于关键调整的身份。此外,当前方法利用多重扩散来组合多个人,这需要多个扩散过程。在当前方法中有效地组合两个以上具有一致身份的个体具有挑战性 并且是一个值得探索的有趣未来方向。
这篇关于StyleGAN和Diffusion结合能擦出什么火花?PreciseControl:实现文本到图像生成中的精确属性控制!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



