本文主要是介绍SDAU训练日志第24篇----------图论算法(基本概念Prim)(2018年5月22日),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
省赛结束啦,接着写博客。
在准备比赛的期间没有学习树形结构,回来之后发现大家已经开始学图论了,那我也先学图论,树形结构以后在补上。
开始被图论血虐的过程吧
(版权免责声明:以下图论基本内容整理改编https://blog.csdn.net/saltriver/article/details/54428685,仅供本人学习使用。)
图(graph)是数据结构和算法学中最强大的框架之一(或许没有之一)。图几乎可以用来表现所有类型的结构或系统,从交通网络到通信网络,从下棋游戏到最优流程,从任务分配到人际交互网络,图都有广阔的用武之地。
而要进入图论的世界,清晰、准确的基本概念是必须的前提和基础。下面对其最核心和最重要的概念作出说明。关于图论的概念异乎寻常的多,先掌握下面最核心最重要的,足够开展一些工作了,其它的再到实践中不断去理解和熟悉吧。
图(graph)并不是指图形图像(image)或地图(map)。通常来说,我们会把图视为一种由“顶点”组成的抽象网络,网络中的各顶点可以通过“边”实现彼此的连接,表示两顶点有关联。注意上面图定义中的两个关键字,由此得到我们最基础最基本的2个概念,顶点(vertex)和边(edge)。直接上图吧。
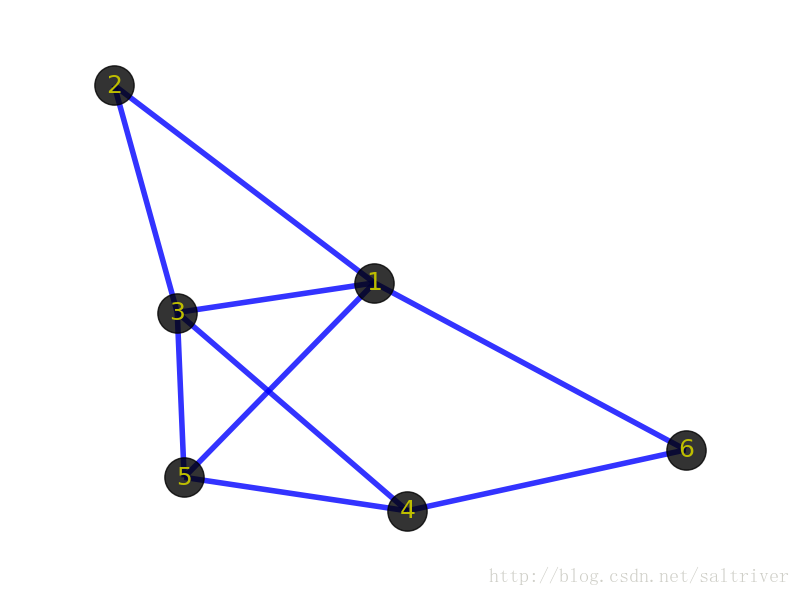
一、顶点(vertex)
上图中黑色的带数字的点就是顶点,表示某个事物或对象。由于图的术语没有标准化,因此,称顶点为点、节点、结点、端点等都是可以的。叫什么无所谓,理解是什么才是关键。
二、边(edge)
上图中顶点之间蓝色的线条就是边,表示事物与事物之间的关系。需要注意的是边表示的是顶点之间的逻辑关系,粗细长短都无所谓的。包括上面的顶点也一样,表示逻辑事物或对象,画的时候大小形状都无所谓。
三、同构(Isomorphism )
先看看下面2张图: 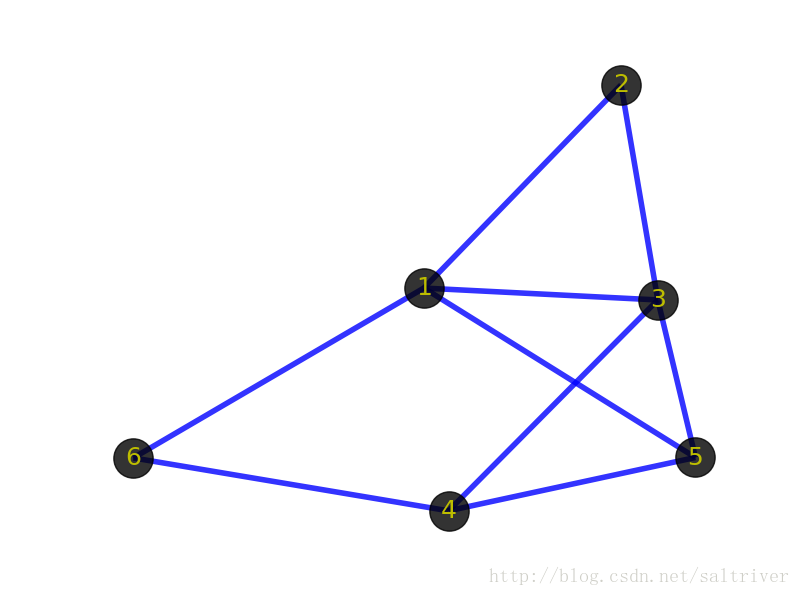
首先你的感觉是这2个图肯定不一样。但从图(graph)的角度出发,这2个图是一样的,即它们是同构的。前面提到顶点和边指的是事物和事物的逻辑关系,不管顶点的位置在哪,边的粗细长短如何,只要不改变顶点代表的事物本身,不改变顶点之间的逻辑关系,那么就代表这些图拥有相同的信息,是同一个图。同构的图区别仅在于画法不同。
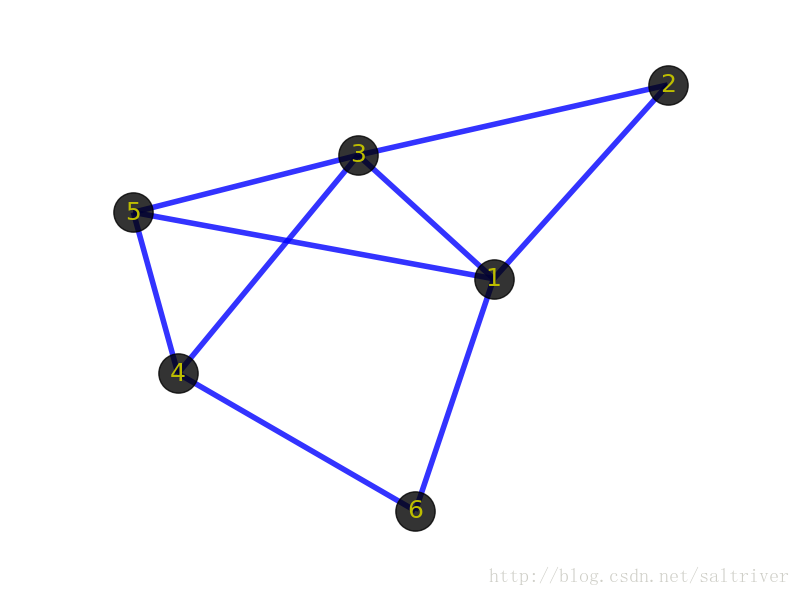
四、有向/无向图(Directed Graph/ Undirected Graph)
最基本的图通常被定义为“无向图”,与之对应的则被称为“有向图”。两者唯一的区别在于,有向图中的边是有方向性的。下图即是一个有向图,边的方向分别是:(1->2), (1-> 3), (3-> 1), (1->5), (2->3), (3->4), (3->5), (4->5), (1->6), (4->6)。要注意,图中的边(1->3)和(3->1)是不同的。有向图和无向图的许多原理和算法是相通的。
五、权重(weight)
边的权重(或者称为权值、开销、长度等),也是一个非常核心的概念,即每条边都有与之对应的值。例如当顶点代表某些物理地点时,两个顶点间边的权重可以设置为路网中的开车距离。下图中顶点为4个城市:Beijing, Shanghai, Wuhan, Guangzhou,边的权重设置为2城市之间的开车距离。有时候为了应对特殊情况,边的权重可以是零或者负数,也别忘了“图”是用来记录关联的东西,并不是真正的地图。
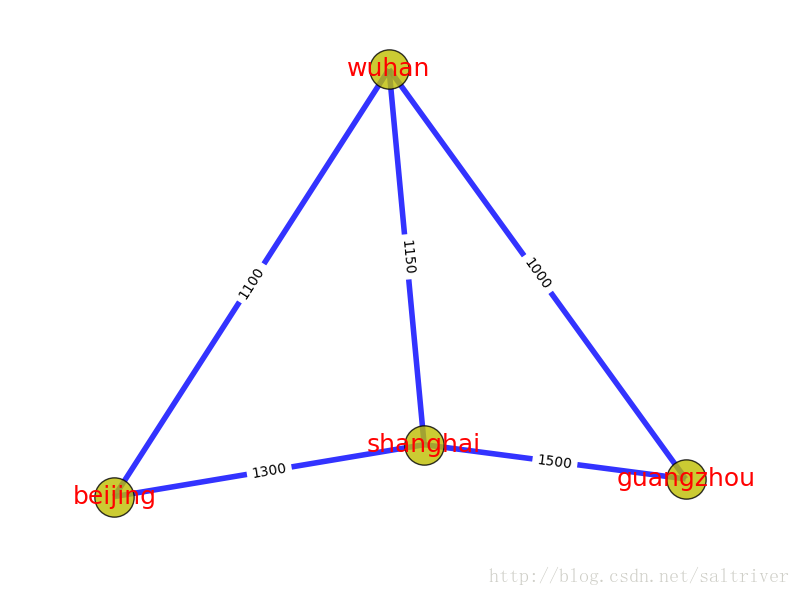
六、路径/最短路径(path/shortest path)
在图上任取两顶点,分别作为起点(start vertex)和终点(end vertex),我们可以规划许多条由起点到终点的路线。不会来来回回绕圈子、不会重复经过同一个点和同一条边的路线,就是一条“路径”。两点之间存在路径,则称这2个顶点是连通的(connected)。
还是上图的例子,北京->上海->广州,是一条路径,北京->武汉->广州,是另一条路径,北京—>武汉->上海->广州,也是一条路径。而北京->武汉->广州这条路径最短,称为最短路径。
路径也有权重。路径经过的每一条边,沿路加权重,权重总和就是路径的权重(通常只加边的权重,而不考虑顶点的权重)。在路网中,路径的权重,可以想象成路径的总长度。在有向图中,路径还必须跟随边的方向。
值得注意的是,一条路径包含了顶点和边,因此路径本身也构成了图结构,只不过是一种特殊的图结构。
七、环(loop)
环,也成为环路,是一个与路径相似的概念。在路径的终点添加一条指向起点的边,就构成一条环路。通俗点说就是绕圈。 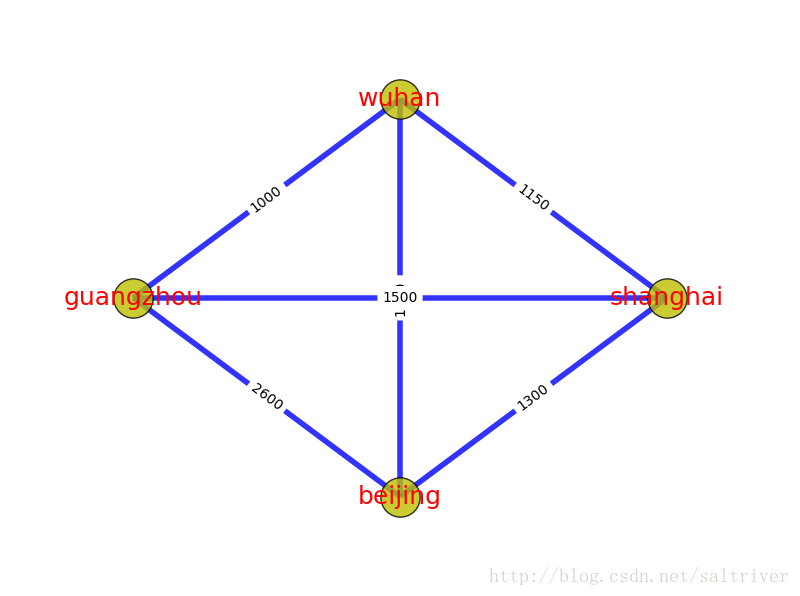
上图中,北京->上海->武汉->广州->北京,就是一个环路。北京->武汉->上海->北京,也是一个环路。与路径一样,有向图中的环路也必须跟随边的方向。环本身也是一种特殊的图结构。
八、连通图/连通分量/强连通分量
如果在图G中,任意2个顶点之间都存在路径,那么称G为连通图(注意是任意2顶点)。上面那张城市之间的图,每个城市之间都有路径,因此是连通图。而下面这张图中,顶点8和顶点2之间就不存在路径,因此下图不是一个连通图,当然该图中还有很多顶点之间不存在路径。 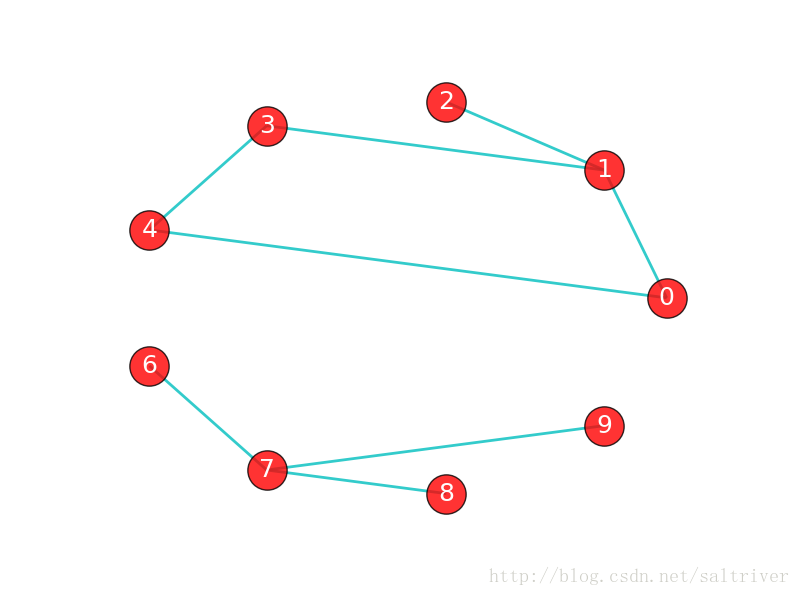
上图虽然不是一个连通图,但它有多个连通子图:0,1,2顶点构成一个连通子图,0,1,2,3,4顶点构成的子图是连通图,6,7,8,9顶点构成的子图也是连通图,当然还有很多子图。我们把一个图的最大连通子图称为它的连通分量。0,1,2,3,4顶点构成的子图就是该图的最大连通子图,也就是连通分量。连通分量有如下特点:
1)是子图;
2)子图是连通的;
3)子图含有最大顶点数。
注意:“最大连通子图”指的是无法再扩展了,不能包含更多顶点和边的子图。0,1,2,3,4顶点构成的子图已经无法再扩展了。
显然,对于连通图来说,它的最大连通子图就是其本身,连通分量也是其本身。
有向图强连通分量:在有向图G中,如果两个顶点vi,vj间(vi>vj)有一条从vi到vj的有向路径,同时还有一条从vj到vi的有向路径,则称两个顶点强连通(strongly connected)。如果有向图G的每两个顶点都强连通,称G是一个强连通图。有向图的极大强连通子图,称为强连通分量(strongly connected components)。
九、生成树/最小生成树
生成树:
最小生成树:
一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边。 [1] 最小生成树可以用kruskal(克鲁斯卡尔)算法或prim(普里姆)算法求出。
精确定义:
在一给定的无向图G = (V, E) 中,(u, v) 代表连接顶点 u 与顶点 v 的边(即),而 w(u, v) 代表此边的权重,若存在 T 为 E 的子集(即)且为无循环图,使得的 w(T) 最小,则此 T 为 G 的最小生成树。
最小生成树其实是最小权重生成树的简称。
Prim算法简述
1).输入:一个加权连通图,其中顶点集合为V,边集合为E;
2).初始化:Vnew= {x},其中x为集合V中的任一节点(起始点),Enew= {},为空;
3).重复下列操作,直到Vnew= V:
a.在集合E中选取权值最小的边<u, v>,其中u为集合Vnew中的元素,而v不在Vnew集合当中,并且v∈V(如果存在有多条满足前述条件即具有相同权值的边,则可任意选取其中之一);
b.将v加入集合Vnew中,将<u, v>边加入集合Enew中;
4).输出:使用集合Vnew和Enew来描述所得到的最小生成树。
伪代码:PrimMST(G,T,r){ //求图G的以r为根的MST,结果放在T=(U,TE)中 InitCandidateSet(…);//初始化:设置初始的轻边候选集,并置T=({r},¢) for(k=0;k<n-1;k++){ //求T的n-1条树边(u,v)=SelectLiShtEdge(…);//选取轻边(u,v); T←T∪{(u,v)};//扩充T,即(u,v)涂红加入TE,蓝点v并人红点集U ModifyCandidateSet(…); //根据新红点v调整候选轻边集 }

Kruskal算法简述
Kruskal算法是基于贪心的思想得到的。首先我们把所有的边按照权值先从小到大排列,接着按照顺序选取每条边,如果这条边的两个端点不属于同一集合,那么就将它们合并,直到所有的点都属于同一个集合为止。至于怎么合并到一个集合,那么这里我们就可以用到一个工具——-并查集。换而言之,Kruskal算法就是基于并查集的贪心算法。
假设 WN=(V,{E}) 是一个含有 n 个顶点的连通网,则按照克鲁斯卡尔算法构造最小生成树的过程为:先构造一个只含 n 个顶点,而边集为空的子图,若将该子图中各个顶点看成是各棵树上的根结点,则它是一个含有 n 棵树的一个森林。之后,从网的边集 E 中选取一条权值最小的边,若该条边的两个顶点分属不同的树,则将其加入子图,也就是说,将这两个顶点分别所在的两棵树合成一棵树;反之,若该条边的两个顶点已落在同一棵树上,则不可取,而应该取下一条权值最小的边再试之。依次类推,直至森林中只有一棵树,也即子图中含有 n-1条边为止。

先写到这吧,下一篇再详细写最小生成树和最短路径。
这篇关于SDAU训练日志第24篇----------图论算法(基本概念Prim)(2018年5月22日)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






