本文主要是介绍【python】python化妆品销售logistic逻辑回归预测分析可视化(源码+课程论文+数据集)【独一无二】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

系列文章目录
目录
- 系列文章目录
- 一、功能设计
- 项目代码设计重点提取
- 二、数据可视化
- 三、逻辑回归模型构建与评估
一、功能设计
项目代码设计重点提取
-
目标:对化妆品销售数据进行深入分析与挖掘,通过数据可视化和逻辑回归模型,为商家提供市场洞察和决策支持。
-
数据加载和预处理:
- 使用Pandas库读取Excel文件并预览数据。
- 处理日期格式不统一和数值字段包含非数值字符的问题,编写自定义日期解析函数和正则表达式。
- 确保所有字段均为有效的数值类型,移除缺失值行。
-
数据可视化:
- 使用Matplotlib库绘制多种图表,展示数据特征和趋势:
- 折线图:展示订单金额随日期的变化,揭示销售的时间趋势。
- 散点图:分析订购数量与金额的关系,显示订购数量对总金额的影响。
- 柱状图:显示各省份的总金额分布,为区域销售策略的制定提供依据。
- 饼状图:展示各省份的订单数量占比,直观了解不同区域的市场份额。
- 雷达图:比较各商品编号的订购数量、订购单价和金额,评估不同商品的销售表现。
- 箱线图:展示订购数量和金额的分布情况,识别数据中的异常值和分布特征。
- 使用Matplotlib库绘制多种图表,展示数据特征和趋势:
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “化妆品逻辑” 获取。👈👈👈
-
逻辑回归模型:
- 通过定义高金额订单的阈值,将目标变量分为高金额和低金额两类。
- 使用LabelEncoder将分类变量转换为数值。
- 将数据分为训练集和测试集,利用逻辑回归模型进行训练和预测。
- 评估模型性能,计算准确率、混淆矩阵和分类报告。
- 绘制热力图和目标变量分布图,分析特征间的相关性和目标变量的分布情况。
-
整体设计思路:
- 注重数据清理、可视化和建模三部分的紧密结合。
- 通过系统化的分析方法,从多角度挖掘数据价值,为商家提供全面的市场分析和决策支持。
- 确保分析结果的准确性和可靠性,为后续的模型优化和应用拓展提供坚实基础。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “化妆品逻辑” 获取。👈👈👈
二、数据可视化
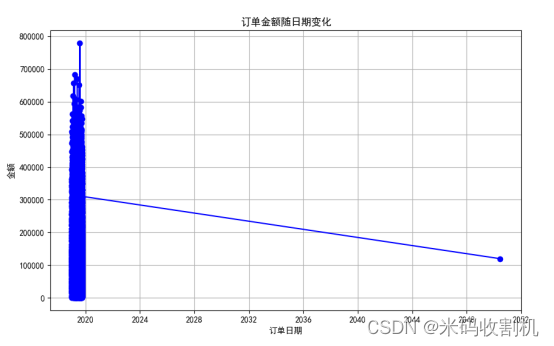
折线图:展示订单金额随日期变化的趋势,帮助分析销售的时间变化。
plt.plot(df['订单日期'], df['金额'], marker='o', linestyle='-', color='b')
折线图展示了订单金额随日期的变化趋势,帮助了解销售的时间分布和变化规律。通过识别销售高峰期和低谷期,可以优化销售策略、安排促销活动和调整库存管理,提升销售效率。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “化妆品逻辑” 获取。👈👈👈
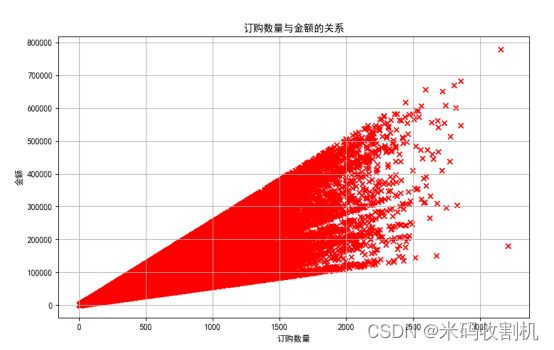
散点图:分析订购数量与金额之间的关系,揭示数量对总金额的影响。
plt.scatter(df['订购数量'], df['金额'], c='r', marker='x')
散点图揭示了订购数量与订单金额之间的关系,帮助理解不同订购数量对销售金额的影响。通过观察散点的分布情况,可以发现订购数量与销售金额的相关性,识别出表现异常的订单,并为商品定价策略和销售预测提供依据。
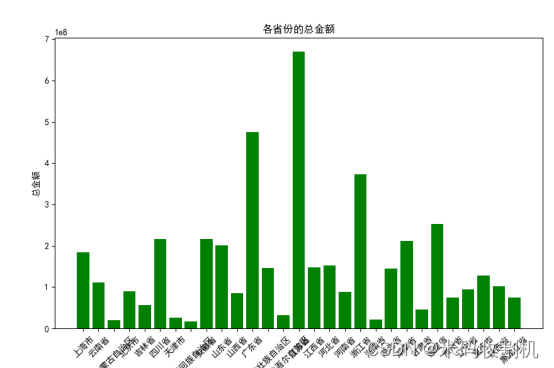
柱状图:显示各省份的总金额分布,为区域销售策略提供依据。
plt.bar(province_amount['所在省份'], province_amount['金额'], color='g')
柱状图显示了各省份的总销售金额,为提供了区域销售的概览。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “化妆品逻辑” 获取。👈👈👈
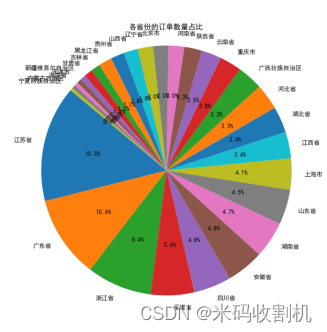
饼状图:展示各省份的订单数量占比,直观了解不同区域的市场份额。
plt.pie(province_count, labels=province_count.index, autopct='%1.1f%%', startangle=140)
饼状图直观展示了各省份订单数量在总订单中的占比,帮助了解不同区域的市场份额和客户分布情况。通过比较各省份的占比,可以发现市场渗透率较高的区域和潜在的增长区域,为市场扩展和推广活动提供指导。
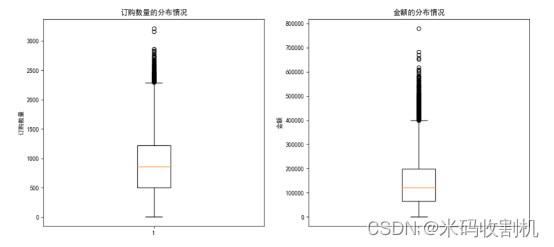
箱线图:展示订购数量和金额的分布情况,识别数据中的异常值和分布特征。
axes[0].boxplot(df['订购数量'])
axes[1].boxplot(df['金额'])
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “化妆品逻辑” 获取。👈👈👈
三、逻辑回归模型构建与评估
功能:构建逻辑回归模型,预测高金额订单,评估模型性能。
具体操作: 定义目标变量(高金额订单),并使用LabelEncoder将分类变量转换为数值。将数据分为训练集和测试集,确保模型的训练和评估过程科学合理。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
模型训练:
使用逻辑回归模型对训练集进行训练,构建预测模型。
model = LogisticRegression()
model.fit(X_train, y_train)
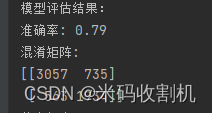
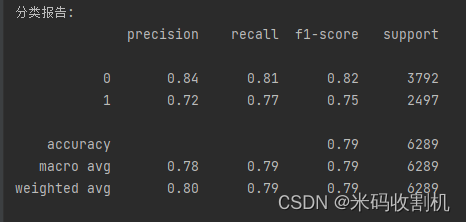
模型评估:
进行预测并评估模型性能,计算准确率、混淆矩阵和分类报告,全面评估模型的预测效果。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “化妆品逻辑” 获取。👈👈👈
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
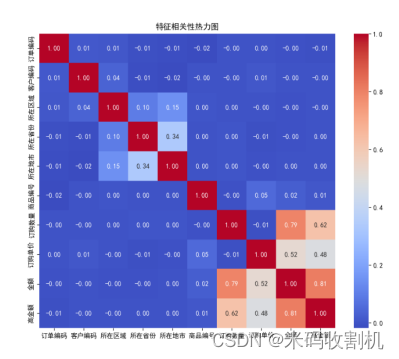
热力图:展示特征之间的相关性,帮助理解特征间的相互关系。热力图展示了各特征之间的相关性,帮助理解特征间的相互关系和对目标变量的影响。
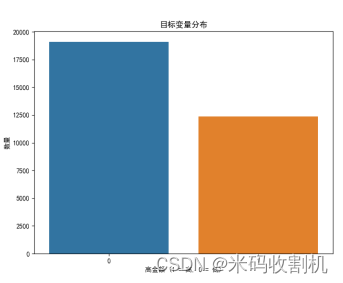
目标变量分布图:展示高金额和低金额订单的数量分布,帮助理解目标变量的分布情况。目标变量分布图展示了高金额和低金额订单的数量分布情况,帮助直观了解目标变量的分布特征。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “化妆品逻辑” 获取。👈👈👈
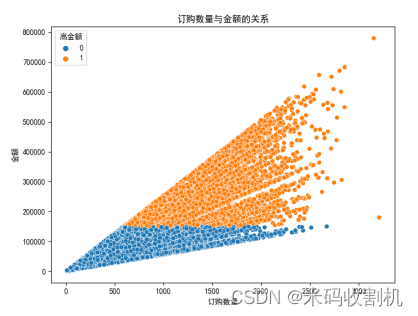
订购数量与金额关系图:展示不同金额订单的订购数量分布。订购数量与金额关系图展示了不同金额订单的订购数量分布,并通过颜色区分高金额和低金额订单。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “化妆品逻辑” 获取。👈👈👈
这篇关于【python】python化妆品销售logistic逻辑回归预测分析可视化(源码+课程论文+数据集)【独一无二】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




