本文主要是介绍【ARM Cache 及 MMU 系列文章 6.3 -- ARMv8/v9 Cache Tag数据读取及分析】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
请阅读【ARM Cache 及 MMU/MPU 系列文章专栏导读】
及【嵌入式开发学习必备专栏】
文章目录
- Cache Tag 数据读取
- 测试代码
Cache Tag 数据读取
在处理器中,缓存是一种快速存储资源,用于减少访问主内存时的延迟。缓存通过存储主内存中经常访问的数据来实现这一点。为了有效地管理这些数据,缓存被组织成行(lines)或块(blocks),每个行或块包含了一段连续的内存数据。每个缓存行都与一个缓存标签(cache tag)相关联,这个标签用于标识存储在缓存行中的数据属于内存的哪个位置。本文将介绍如何读取Cache Tag 中的数据。
读取命令:
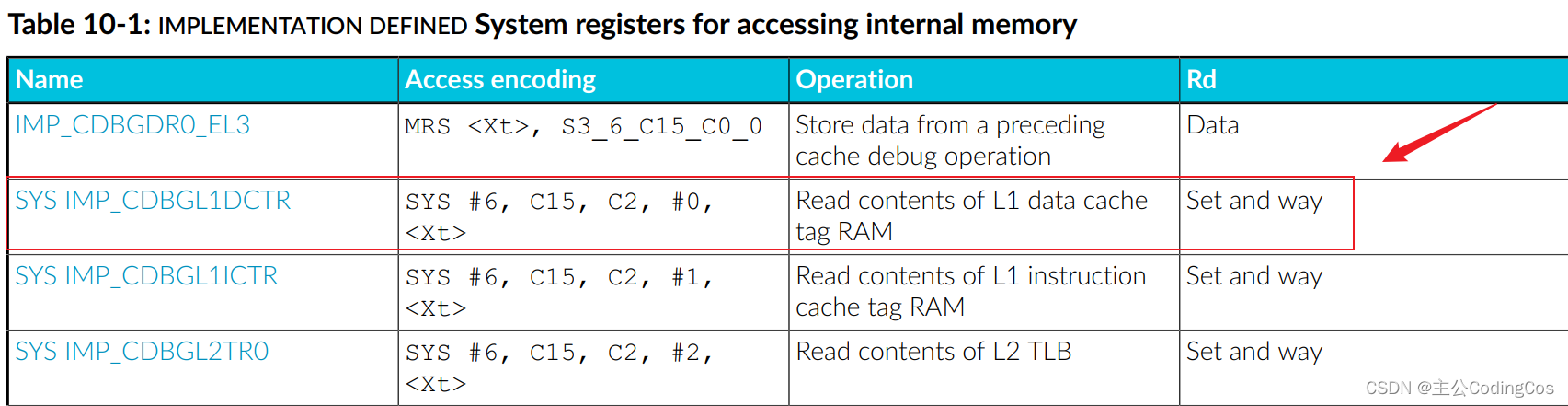
选择读取的路和组:

读取tag数据并解析:
这篇关于【ARM Cache 及 MMU 系列文章 6.3 -- ARMv8/v9 Cache Tag数据读取及分析】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









