armv8专题
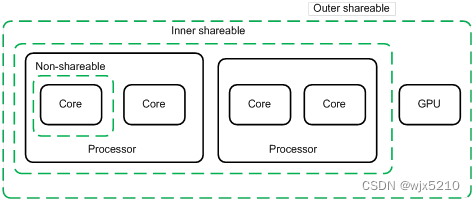
armv8 memory model概述
概述 在armv8 架构中,它引入了更多的维度来描述内存模型,从而在此基础上进行硬件优化(但其中一些并未被主流的软件所接受),在此做一些简单的整理,更多信息请参考 Arm spec 以及 AMBA 协议。下文主要是对Memory 和 Device 两大类的模型进行解释,个人言论难免有误,如有谬误请不吝指正。 首先将物理地址空间映射分成两大类: Memory, Device。 两者最大的区别在于

rsyslog交叉编译(armv7、armv8、aarch64、arm32平台通用)
文章目录 1、依赖库列表2、编译建议3、编译3.1、编译libestr3.2、编译libfastjson3.3、编译zlib3.4、编译libuuid3.5、编译libgpg-error3.6、编译libgcrypt3.7、编译openssl3.8、编译curl3.9、编译rsyslog 该文档描述了如何交叉编译rsyslog到arm64嵌入式平台。 1、依赖库列表 lib

ARMv8架构下程序运行时栈帧布局
结合ARM相关文档和在飞腾机器上使用gdb调试实际程序来研究ARM的指令和运行时栈帧布局。主要参考了三篇文档。 1. Procedure Call Standard for the ARM 64-bit Architecture。参考其中的过程调用标准和运行时栈帧布局。 2. ARMv8 Instruction Set Overview。参考其中的指令概述。 3. ARM Compil

【ARMv8/v9 GIC 系列 4.1 -- GIC CPU Interface 访问支持情况】
文章目录 GIC CPU Interface 访问支持Bit[27:24]: GIC CPU接口汇编代码实现访问小结 GIC CPU Interface 访问支持 在ARMv8架构中,ID_AA64PFR0_EL1是一个系统寄存器,提供了有关处理器功能的详绀信息。这个寄存器的位[27:24]专门用于描述GIC(通用中断控制器)CPU接口的系统寄存器接口支持情况。以下是对这些位

【ARMv8/ARMv9 硬件加速系列 2.3 -- ARM NEON 的四舍五入指令】
文章目录 NEON 的四舍五入SRSHLR 指令格式SRSHLR 操作说明SRSHLR 示例解释 NEON 的四舍五入 SRSHR指令是ARMv8 NEON SIMD指令集中的一部分,用于对向量中的每个元素进行向右的算术位移操作,并将结果四舍五入。SRSHR指令的全称是Signed Rounding Shift Right,适用于带符号的整数。这个指令对于进行数据尺度缩小、平

【ARMv8/ARMv9 硬件加速系列 2.2 -- ARM NEON 的加减乘除(左移右移)运算】
文章目录 NEON 加减乘除 NEON 加减乘除 下面代码是使用ARMv8汇编语言对向量寄存器v0-v31执行加、减、乘以及左移和右移操作的示例。 ARMv8的SIMD指令集允许对向量寄存器中的多个数据进行并行操作。v0和v1加载数据,对它们进行加、减和乘,左移和右移操作。最后,我们会将结果存储到内存地址0xb0000000处, 方便观察结果。 func neon_calc_

【ARMv8/ARMv9 硬件加速系列 4.1 -- Cryptographic Extension 解密指令 AESD】
文章目录 Cryptographic Extension 解密指令 AESDAESD 指令详解AES 工作原理AESD 使用条件 AESD 示例场景 Cryptographic Extension 解密指令 AESD ARMv9架构引入了对先进加密标准(AES)操作的改进和加速,AESD指令是这些改进之一,专门用于AES解密操作。这个指令通过对数据执行一系列变换,实现了AES

【ARMv8/ARMv9 硬件加速系列 3.4 -- SVE 复制指令CPY 使用介绍】
文章目录 SVE 复制指令CPYSVE 指令格式SVE 使用语法SVE CPY 使用示例SVE CPY 小结 SVE 复制指令CPY CPY <Zd>.<T>, <Pg>/M, #<imm>{, <shift>} cpy 指令在 ARMv9 的

【ARMv8/ARMv9 硬件加速系列 3.3 -- SVE LD2D 和 ST2D 使用介绍】
文章目录 SVE 多向量操作LD2D(加载)LD2D 操作说明LD2D 使用举例ST2D(存储)ST2D 使用举例ST2D 存储示例代码 ld2d 和 st2d 小结 SVE 多向量操作 在ARMv8/9的SVE (Scalable Vector Extension) 指令集中,st2d和ld2d指令用于向量化的存储和加载操作,具体地,它们允许同时对两个向量寄存器进行连续的存

【ARMv8/ARMv9 硬件加速系列 3 -- SVE 硬件加速向量运算 1】
文章目录 SVE 使用介绍SVE 特点SVE2 特点 SVE 寄存器扩展的向量寄存器可扩展的谓词寄存器.d 与 .b 后缀的区别举例介绍使用 .d 后缀进行64位元素操作使用 .b 后缀进行8位元素操作 ptrue 指令小结 FFR 寄存器 SVE 使用介绍 前面文章:【ARMv8/ARMv9 硬件加速系列 1 – SVE | NEON | SIMD | VFP | MVE

【ARMv8/ARMv9 硬件加速系列 1 -- SVE | NEON | SIMD | VFP | MVE | MPE 基础介绍】
文章目录 ARM 扩展功能介绍VFP (Vector Floating Point)SIMD (Single Instruction, Multiple Data)NEONSVE (Scalable Vector Extension)SME (Scalable Matrix Extension)CME (Compute Matrix Engine)MVE (M-profile Vector

NDK r21编译FFmpeg 4.2.2(x86、x86_64、armv7、armv8)
文章目录 1.编译FFmpeg2.使用FFmpeg的so库 1.编译FFmpeg 准备Ununtu、ndk r21(linux)、FFmpeg。 准备编译脚本,这里有两个,其中一个是专门针对armv7的。 armv7 #!/bin/bashAPI=21#armv7-aARCH=armv7 PREFIX=./SO/$ARCHTOOLCHAIN=/home/qwe/andr

【ARM Cache 及 MMU 系列文章 6.4 -- ARMv8/v9 如何读取 Cache Tag 及分析其数据?】
请阅读【ARM Cache 及 MMU/MPU 系列文章专栏导读】 及【嵌入式开发学习必备专栏】 文章目录 Cache Tag 数据读取测试代码 Cache Tag 数据读取 在处理器中,缓存是一种快速存储资源,用于减少访问主内存时的延迟。缓存通过存储主内存中经常访问的数据来实现这一点。为了有效地管理这些数据,缓存被组织成行(lines)或块(blocks),每个行或块包
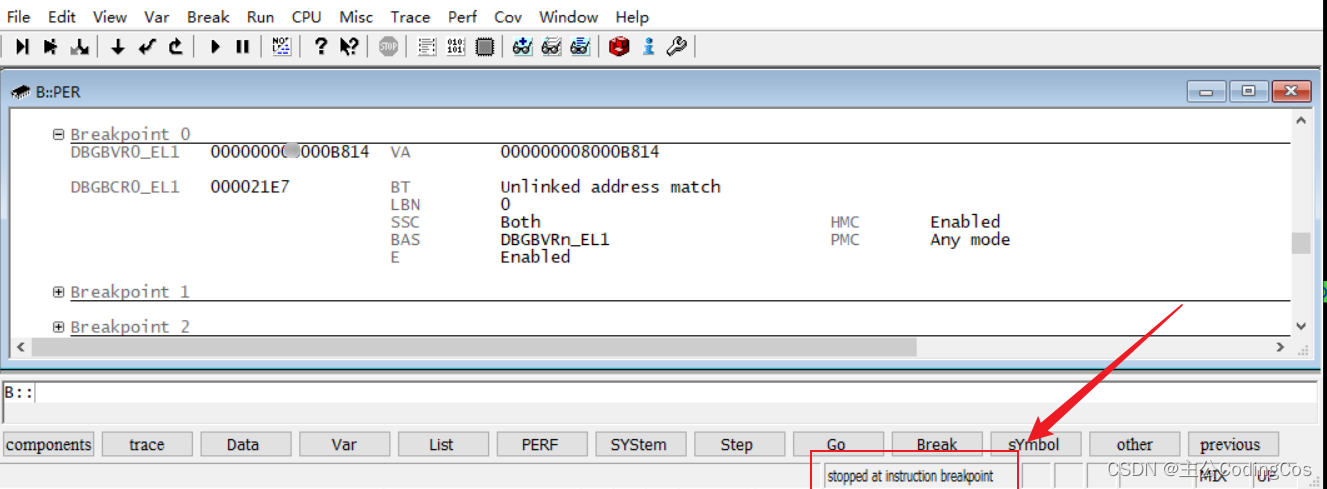
【ARM Coresight Debug 系列 -- ARMv8/v9 软件实现断点地址设置】
请阅读【嵌入式开发学习必备专栏 】 文章目录 ARMv8/v8 软件设置段带你断点地址软件配置流程代码实现 ARMv8/v8 软件设置段带你 在ARMv8/9架构中,可以通过寄存器 DBGBVR0_EL1 设置断点。这个寄存器是一系列调试断点值寄存器中的第一个DBGBVRn_EL1,其中n表示寄存器编号,对于ARMv8/9,通常可以有多个这样的寄存器,具体数量取决于实现
【ARM Cache 及 MMU 系列文章 6.3 -- ARMv8/v9 Cache Tag数据读取及分析】
请阅读【ARM Cache 及 MMU/MPU 系列文章专栏导读】 及【嵌入式开发学习必备专栏】 文章目录 Cache Tag 数据读取测试代码 Cache Tag 数据读取 在处理器中,缓存是一种快速存储资源,用于减少访问主内存时的延迟。缓存通过存储主内存中经常访问的数据来实现这一点。为了有效地管理这些数据,缓存被组织成行(lines)或块(blocks),每个行或块包

【ARM64 常见汇编指令学习 19.3 -- ARMv8 三目运算指令 csel 详细介绍】
文章目录 三目运算指令 csel地址获取条件选择用途 三目运算指令 csel 本篇文章以下面汇编代码介绍三目运算指令csel: adr x0, pass_messageadr x1, fail_messagecsel x1, x0, x1, pl 下面是对这几行代码的详解: 地址获取 adr x0, pass_messageadr x1, f
【ARM 常见汇编指令学习 6.2 -- ARMv8 汇编指令 SDIV 详细介绍】
文章目录 SDIV指令格式使用示例注意事项总结 SDIV ARMv8 架构中的 SDIV 指令用于执行带符号整数除法操作。这意味着它可以处理负数除法,与 UDIV(执行无符号整数除法)形成对比。SDIV 将两个寄存器中的带符号整数相除,将除法结果存储在目标寄存器中。 指令格式 SDIV 的基本语法如下: SDIV <Xd>, <Xn>, <Xm> 或者对于 32 位
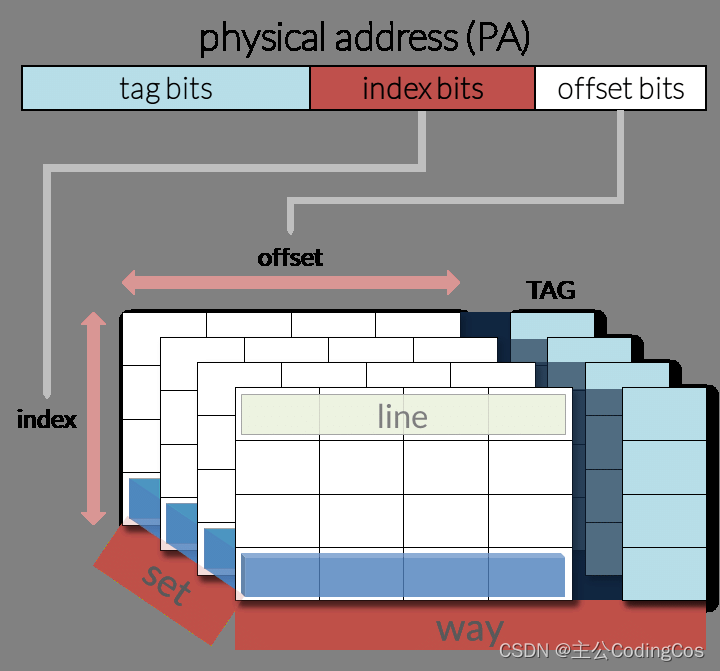
【ARM Cache 及 MMU 系列文章 6.2 -- ARMv8/v9 Cache 内部数据读取方法详细介绍】
请阅读【ARM Cache 及 MMU/MPU 系列文章专栏导读】 及【嵌入式开发学习必备专栏】 文章目录 Direct access to internal memoryL1 cache encodingsL1 Cache Data 寄存器 Cache 数据读取代码实现 Direct access to internal memory 在ARMv8架构中,缓存(Cach

【ARM Cache 系列文章 7.2 – ARMv8/v9 MMU 页表配置详细介绍 03 】
请阅读【ARM Cache 及 MMU/MPU 系列文章专栏导读】 及【嵌入式开发学习必备专栏】 文章目录 表描述符 Table descriptor52-bit OA 颗粒为4KB 和16KB52-bit OA 颗粒为64KB48-bit OA 颗粒为4KB 和16KB Stage 1 和 Stage 2 介绍第一阶段(Stage 1)转换的表描述符属性字段第二阶段(Stage 2)
ARMv8 Power Management
能源消耗分类静态功耗:每当核心逻辑或RAM块通电时,就会发生静态功耗,也称为泄漏。一般来说,漏电流与总硅面积成正比,这意味着芯片越大,漏电流越高。随着制造几何尺寸的减小,泄漏造成的功耗比例显著增加。动态功耗:是由于晶体管切换而产生的,是核心时钟速度和每个周期改变状态的晶体管数量的函数。显然,更高的时钟速度和更复杂的内核会消耗更多的功率。 基础:OSPM操作系统电源管理(Operating
ARMv8 big.LITTLE
big.LITTLEbit.LITTLE 产生原因现代软件栈对移动系统提出了相互冲突的要求。一方面是对游戏等任务的高性能要求,另一方面是对音频播放等低强度应用的节能要求。单处理器设计不可能既具有高峰值性能又具有高能效。当高性能的核心将用于低强度任务,大量能源被浪费,导致电池寿命缩短。性能本身会受到堆芯可以持续运行的热极限的影响。big.LITTLE技术通过将节能的小内核与高性能的大内核耦合在一起,
ARMv8 Multi-core processors
MPMP框架单处理器 : 一个单处理器多处理器 :1. a cluster with multi-core2. many clusters which contain multi-core如何分辨当前运行的core的IDMPIDR_EL1 // DDI0487E_armv8_A_architecture_reference_manual P3216// 在 riscv中,可以通过读 csr MH
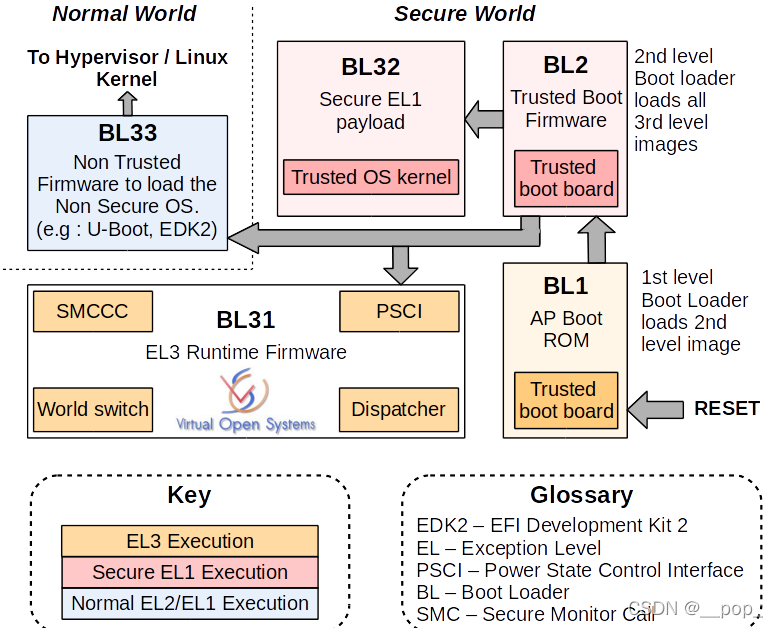
ARMv8 Security
内容来自 DEN0024A_v8_architecture_PG.pdf 本质 ARMv8 Security 是什么 本质增加了一个 Secure world , 该体系结构的增加意味着单个物理内核可以以时间切片的方式执行来自正常世界和安全世界的代码定义了 硬件实现 , 规范了 软件实现 软件实现 : TrustZone安全扩展硬件实现 : 安全外围设备ARM安全模型将设备硬件和软件资源进
【ARM 嵌入式 C 入门及渐进 6.2 -- ARMv8 C 内嵌汇编读系统寄存器的函数实现】
请阅读【嵌入式开发学习必备专栏】 文章目录 ARMv8 C 内嵌汇编读系统寄存器 ARMv8 C 内嵌汇编读系统寄存器 要在ARMv8架构中通过C代码和内嵌汇编来读取系统寄存器s3_0_c15_c5_5的值,并将其返回,可以按照以下方式实现system_read_reg函数: #include <stdint.h>uint64_t system_read_reg(voi
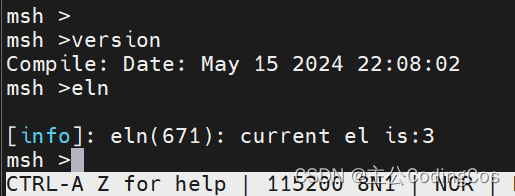
【ARMv8/v9 系统寄存器 6 -- EL 异常等级判定寄存器 CurrentEL 使用详细将介绍】
文章目录 ARMv8/v9 EL 等级获取EL 等级获取函数实现EL 等级获取测试 ARMv8/v9 EL 等级获取 下面这个宏定义是用于ARMv8/v9架构下,通过汇编语言检查当前执行在哪个异常级别(Exception Level,EL)并据此跳转到不同的标签。 异常级别是ARM架构中定义的用于隔离和保护系统资源的机制,不同的级别有不同的权限,一般来说: EL0是用户模
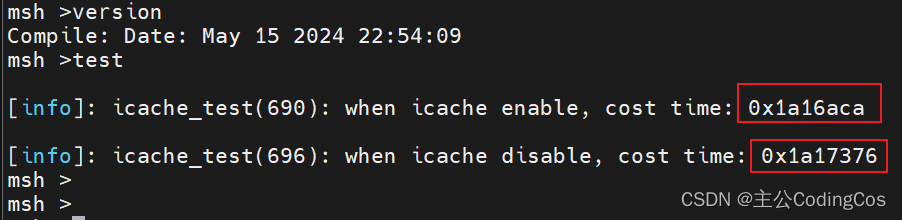
【ARMv8/v9 系统寄存器 5 -- ARMv8 Cache 控制寄存器 SCTRL_EL1 使用详细介绍】
关于ARM Cache 详细学习推荐专栏: 【ARM Cache 专栏】 【ARM ACE Bus 与 Cache 专栏】 文章目录 ARMv8/v9 Cache 设置寄存器ARMv8 指令 Cache 使能函数测试代码 ARMv8/v9 Cache 设置寄存器 关于寄存器SCTRL_EL1 的详细介绍见文章:【ARMv8/v9 异常模型入门及渐进2 - 系统控制寄存器