本文主要是介绍NVIDIA 与 Hugging Face 合作简化生成式 AI 模型部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NVIDIA 与 Hugging Face 合作简化生成式 AI 模型部署

随着生成式 AI 的快速发展,社区已采取两种重要方式来促进这种扩展:迅速发布最先进的基础模型,并简化它们与应用程序开发和生产的集成。
NVIDIA 通过优化基础模型来提高性能,帮助企业更快地生成代币,降低运行模型的成本,并通过 NVIDIA NIM 改善最终用户体验,从而为这一努力提供帮助。
NVIDIA NIM
NVIDIA NIM 推理微服务旨在简化和加速在任何地方(包括云、数据中心和工作站)的 NVIDIA 加速基础设施中部署生成式 AI 模型。
NIM 利用 TensorRT-LLM 推理优化引擎、行业标准 API 和预构建容器来提供低延迟、高吞吐量的 AI 推理,并根据需求进行扩展。它支持各种 LLM,包括 Llama 3、Mixtral 8x22B、Phi-3 和 Gemma,以及针对语音、图像、视频、医疗保健等领域特定领域应用的优化。
NIM 提供卓越的吞吐量,使企业能够以高达 5 倍的速度生成代币。对于生成式 AI 应用程序,代币处理是关键性能指标,而代币吞吐量的提高直接转化为企业更高的收入。
通过简化集成和部署流程,NIM 使企业能够快速从 AI 模型开发转向生产,从而提高效率、降低运营成本,并让企业专注于创新和增长。
现在,我们更进一步,推出了 Hugging Face,帮助开发人员在几分钟内运行模型。
只需单击几下即可在 Hugging Face 上部署 NIM
Hugging Face 是领先的 AI 模型平台,由于它提高了 AI 模型的可访问性,已成为 AI 开发人员的首选目的地。
利用 NVIDIA NIM 的无缝部署功能,从 Llama 3 8B 和 Llama 3 70B 开始,在您首选的云服务提供商上,所有这些都可以直接从 Hugging Face 访问。
NIM 提供卓越的吞吐量,并在多个并发请求下实现接近 100% 的利用率,使企业能够以 3 倍的速度生成文本。对于生成式 AI 应用程序,令牌处理是关键的性能指标,而令牌吞吐量的提高直接转化为企业更高的收入。
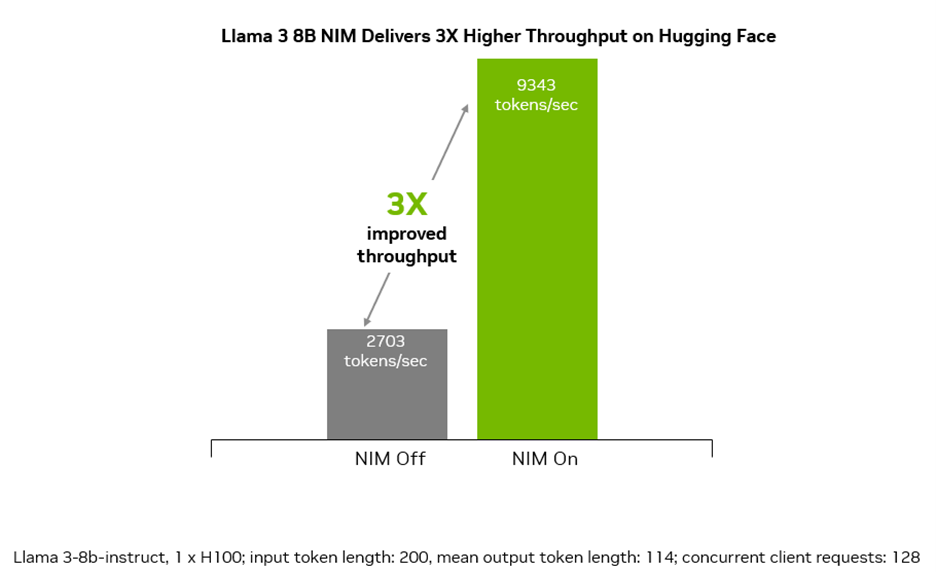
Hugging Face 上的专用 NIM 端点会在您首选的云上启动实例,自动获取和部署 NVIDIA 优化模型,只需点击几下鼠标即可开始推理,所有操作只需几分钟即可完成。
让我们仔细看看。
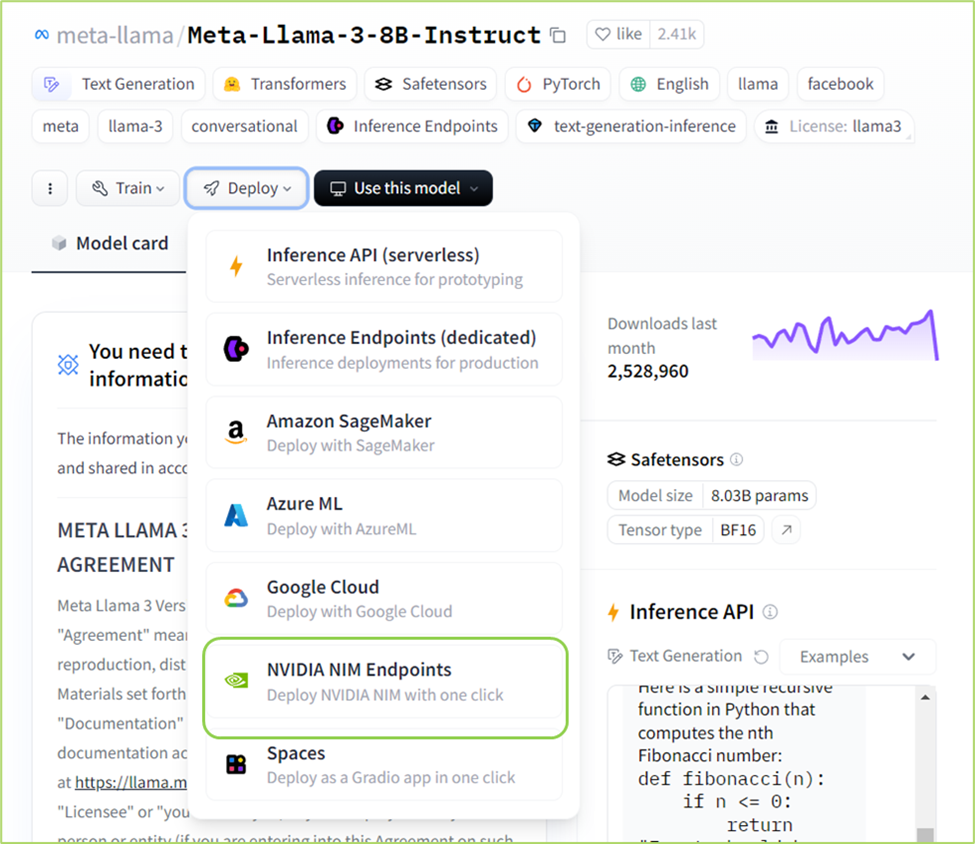
步骤 1:导航到 Hugging Face 上的 Llama 3 8B 或 70B 指令模型页面,单击“部署”下拉菜单,然后从菜单中选择“NVIDIA NIM 端点”。
第 2 步:出现一个新页面,其中显示“使用 NVIDIA NIM 创建新的专用端点”。选择您喜欢的 CSP 实例类型来运行模型。AWS 上的 A10G/A100 和 GCP 实例上的 A100/H100 利用 NVIDIA 优化的模型引擎来获得最佳性能。
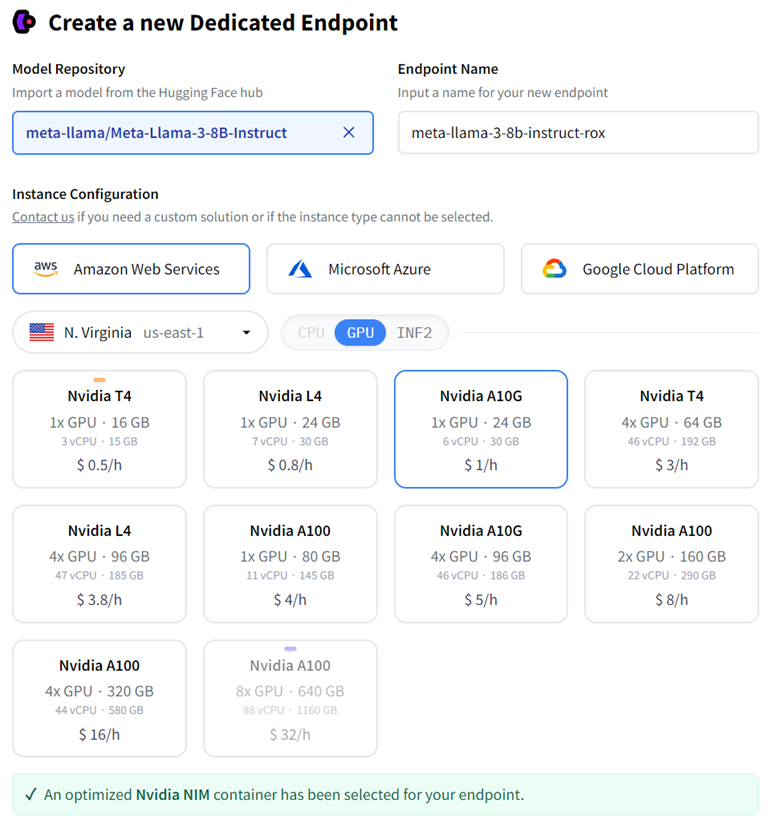
步骤 3:在“高级配置”部分,从容器类型下拉菜单中选择“NVIDIA NIM”,然后单击“创建端点”。

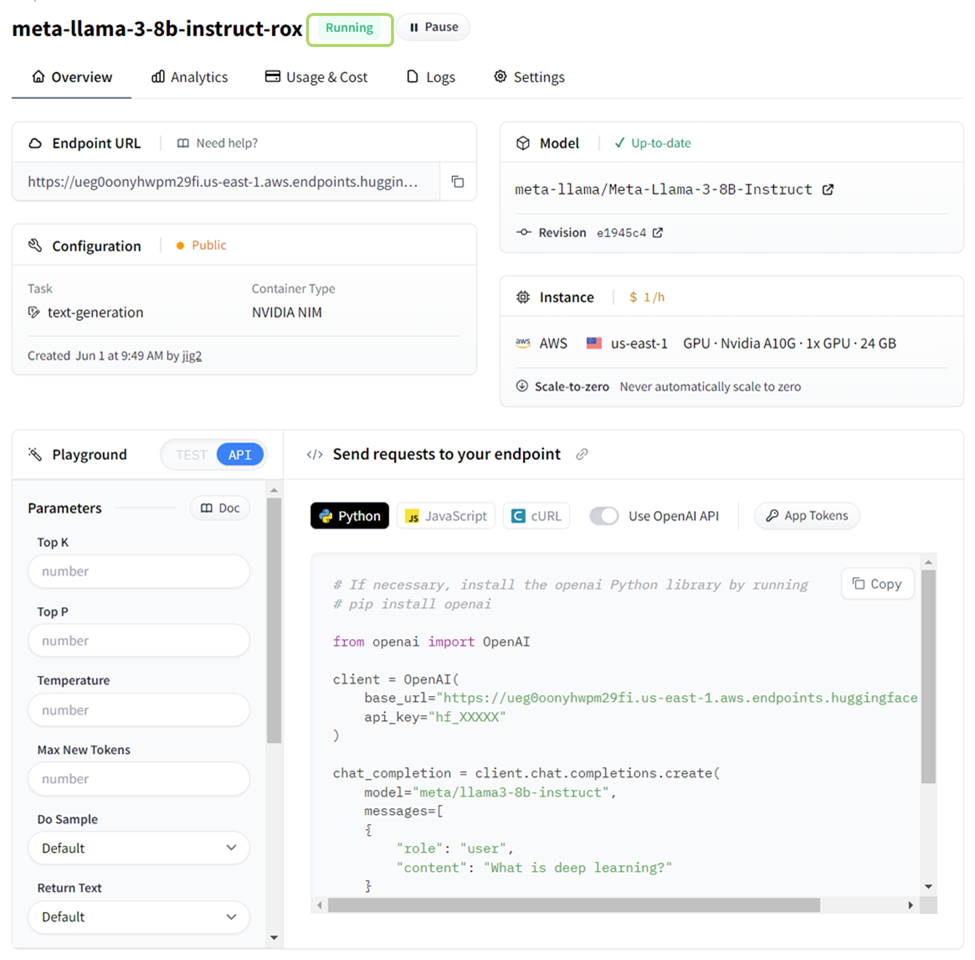
步骤 4:几分钟内,推理端点即可启动并运行。
这篇关于NVIDIA 与 Hugging Face 合作简化生成式 AI 模型部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








