本文主要是介绍[书生·浦语大模型实战营]——第三节:茴香豆:搭建你的 RAG 智能助理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0.RAG 概述
定义:RAG(Retrieval Augmented Generation)技术,通过检索与用户输入相关的信息片段,并结合外部知识库来生成更准确、更丰富的回答。解决 LLMs 在处理知识密集型任务时可能遇到的挑战, 如幻觉、知识过时和缺乏透明、可追溯的推理过程等。提供更准确的回答、降低推理成本、实现外部记忆。
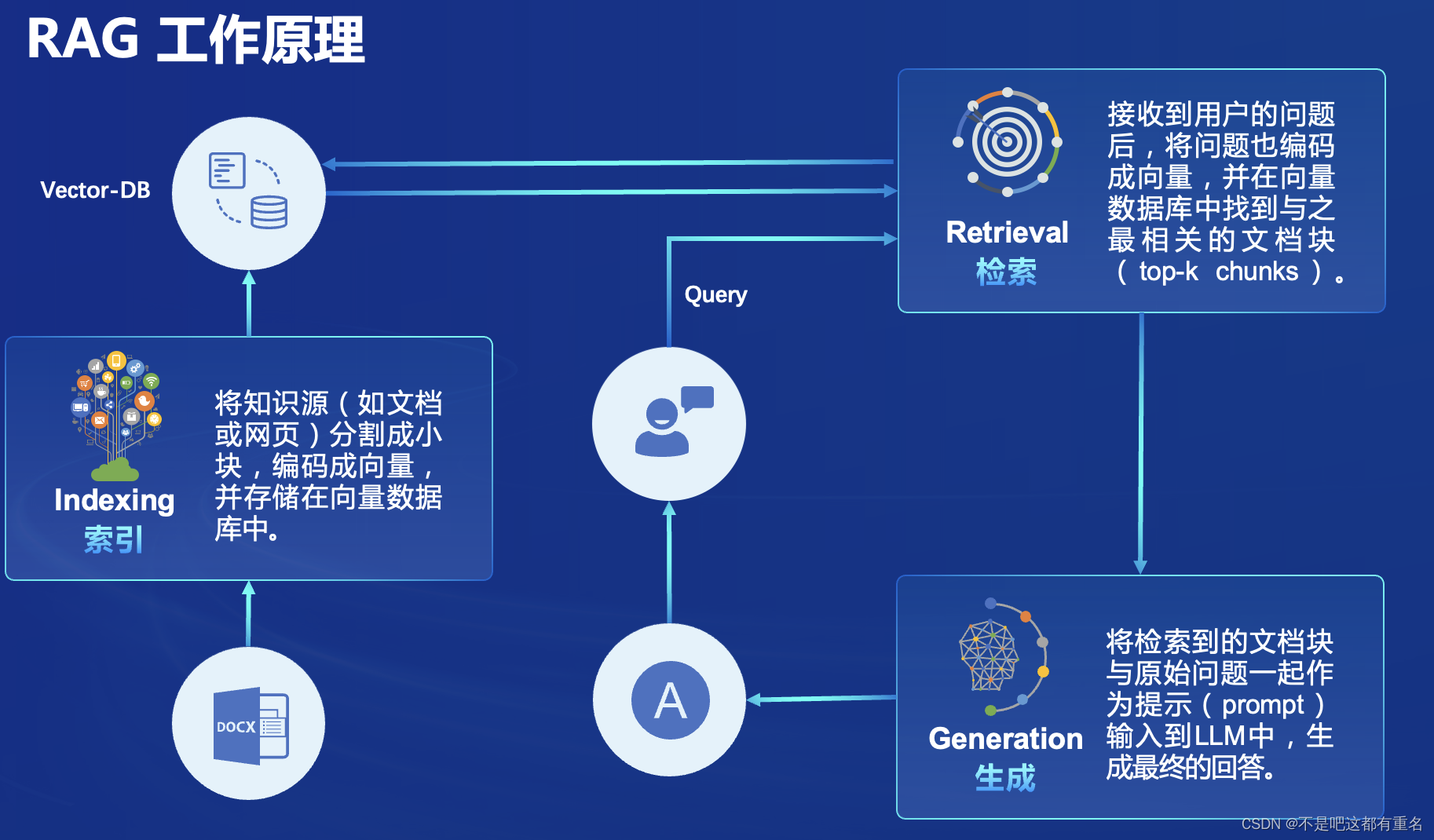
RAG 能够让基础模型实现非参数知识更新,无需训练就可以掌握新领域的知识。本次课程选用的茴香豆应用,就应用了 RAG 技术,可以快速、高效的搭建自己的知识领域助手。
1.环境配置
1.1 配置基础环境
和上一章基本一致,创建环境的命令如下:
studio-conda -o internlm-base -t InternLM2_Huixiangdou
激活
conda activate InternLM2_Huixiangdou
1.2 下载基础文件
所使用的模型都已经在share文件夹中了,这里直接创建软链接
# 复制BCE模型
ln -s /root/share/new_models/maidalun1020/bce-embedding-base_v1 /root/models/bce-embedding-base_v1
ln -s /root/share/new_models/maidalun1020/bce-reranker-base_v1 /root/models/bce-reranker-base_v1# 复制大模型参数(下面的模型,根据作业进度和任务进行**选择一个**就行)
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b /root/models/internlm2-chat-7b安装其他依赖
pip install protobuf==4.25.3 accelerate==0.28.0 aiohttp==3.9.3 auto-gptq==0.7.1 bcembedding==0.1.3 beautifulsoup4==4.8.2 einops==0.7.0 faiss-gpu==1.7.2 langchain==0.1.14 loguru==0.7.2 lxml_html_clean==0.1.0 openai==1.16.1 openpyxl==3.1.2 pandas==2.2.1 pydantic==2.6.4 pymupdf==1.24.1 python-docx==1.1.0 pytoml==0.1.21 readability-lxml==0.8.1 redis==5.0.3 requests==2.31.0 scikit-learn==1.4.1.post1 sentence_transformers==2.2.2 textract==1.6.5 tiktoken==0.6.0 transformers==4.39.3 transformers_stream_generator==0.0.5 unstructured==0.11.2
从github克隆茴香豆
cd /root
# 克隆代码仓库
git clone https://github.com/internlm/huixiangdou && cd huixiangdou
git checkout ded0551
2. 使用茴香豆搭建 RAG 助手
2.1修改配置文件
用已下载模型的路径替换 /root/huixiangdou/config.ini 文件中的默认模型,需要修改 3 处模型地址,分别是:
命令行输入下面的命令,修改用于向量数据库和词嵌入的模型:
sed -i '6s#.*#embedding_model_path = "/root/models/bce-embedding-base_v1"#' /root/huixiangdou/config.ini
用于检索的重排序模型
sed -i '7s#.*#reranker_model_path = "/root/models/bce-reranker-base_v1"#' /root/huixiangdou/config.ini
选用的大模型
sed -i '31s#.*#local_llm_path = "/root/models/internlm2-chat-7b"#' /root/huixiangdou/config.ini
注意:这里教程写的是29行,推荐自己点开文件看看是多少行,我这里是31行
2.2创建知识库
使用 InternLM 的 Huixiangdou 文档作为新增知识数据检索来源,在不重新训练的情况下,打造一个 Huixiangdou 技术问答助手。
(1)下载Huixiangdou 语料
cd /root/huixiangdou && mkdir repodir
git clone https://github.com/internlm/huixiangdou --depth=1 repodir/huixiangdou
(2)提取知识库特征,创建向量数据库。
数据库向量化的过程应用到了 LangChain (一个大模型编程框架)的相关模块,默认嵌入和重排序模型调用的网易 BCE 双语模型。
此外茴香豆还会建立接受和拒答两个向量数据库,用来在检索的过程中更加精确的判断提问的相关性,这两个数据库的来源分别是:
- 接受问题列表(希望茴香豆助手回答的示例问题):
存储在 huixiangdou/resource/good_questions.json 中 - 拒绝问题列表(希望茴香豆助手拒答的示例问题):
存储在 huixiangdou/resource/bad_questions.json 中
增加茴香豆相关的问题到接受问题示例中,运行代码如下
cd /root/huixiangdou
mv resource/good_questions.json resource/good_questions_bk.jsonecho '["mmpose中怎么调用mmyolo接口","mmpose实现姿态估计后怎么实现行为识别","mmpose执行提取关键点命令不是分为两步吗,一步是目标检测,另一步是关键点提取,我现在目标检测这部分的代码是demo/topdown_demo_with_mmdet.py demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py checkpoints/faster_rcnn_r50_fpn_1x_coco_20200130-047c8118.pth 现在我想把这个mmdet的checkpoints换位yolo的,那么应该怎么操作","在mmdetection中,如何同时加载两个数据集,两个dataloader","如何将mmdetection2.28.2的retinanet配置文件改为单尺度的呢?","1.MMPose_Tutorial.ipynb、inferencer_demo.py、image_demo.py、bottomup_demo.py、body3d_pose_lifter_demo.py这几个文件和topdown_demo_with_mmdet.py的区别是什么,\n2.我如果要使用mmdet是不是就只能使用topdown_demo_with_mmdet.py文件,","mmpose 测试 map 一直是 0 怎么办?","如何使用mmpose检测人体关键点?","我使用的数据集是labelme标注的,我想知道mmpose的数据集都是什么样式的,全都是单目标的数据集标注,还是里边也有多目标然后进行标注","如何生成openmmpose的c++推理脚本","mmpose","mmpose的目标检测阶段调用的模型,一定要是demo文件夹下的文件吗,有没有其他路径下的文件","mmpose可以实现行为识别吗,如果要实现的话应该怎么做","我在mmyolo的v0.6.0 (15/8/2023)更新日志里看到了他新增了支持基于 MMPose 的 YOLOX-Pose,我现在是不是只需要在mmpose/project/yolox-Pose内做出一些设置就可以,换掉demo/mmdetection_cfg/faster_rcnn_r50_fpn_coco.py 改用mmyolo来进行目标检测了","mac m1从源码安装的mmpose是x86_64的","想请教一下mmpose有没有提供可以读取外接摄像头,做3d姿态并达到实时的项目呀?","huixiangdou 是什么?","使用科研仪器需要注意什么?","huixiangdou 是什么?","茴香豆 是什么?","茴香豆 能部署到微信吗?","茴香豆 怎么应用到飞书","茴香豆 能部署到微信群吗?","茴香豆 怎么应用到飞书群","huixiangdou 能部署到微信吗?","huixiangdou 怎么应用到飞书","huixiangdou 能部署到微信群吗?","huixiangdou 怎么应用到飞书群","huixiangdou","茴香豆","茴香豆 有哪些应用场景","huixiangdou 有什么用","huixiangdou 的优势有哪些?","茴香豆 已经应用的场景","huixiangdou 已经应用的场景","huixiangdou 怎么安装","茴香豆 怎么安装","茴香豆 最新版本是什么","茴香豆 支持哪些大模型","茴香豆 支持哪些通讯软件","config.ini 文件怎么配置","remote_llm_model 可以填哪些模型?"
]' > /root/huixiangdou/resource/good_questions.json
创建测试用问询列表,用来测试拒答流程是否起效
cd /root/huixiangdouecho '[
"huixiangdou 是什么?",
"你好,介绍下自己"
]' > ./test_queries.json
运行下面的命令,创建 RAG 检索过程中使用的向量数据库:
# 创建向量数据库存储目录
cd /root/huixiangdou && mkdir workdir # 分别向量化知识语料、接受问题和拒绝问题中后保存到 workdir
python3 -m huixiangdou.service.feature_store --sample ./test_queries.json
检索流程:
检索过程中,茴香豆会将输入问题与两个列表中的问题在向量空间进行相似性比较,判断该问题是否应该回答,避免群聊过程中的问答泛滥。确定的回答的问题会利用基础模型提取关键词,在知识库中检索 top K 相似的 chunk,综合问题和检索到的 chunk 生成答案。
问题:
ModuleNotFoundError: No module named 'duckduckgo_search'
解决方案:
pip安装就好了
pip install duckduckgo_search
2.3 运行茴香豆知识助手
运行命令行
# 填入问题
sed -i '74s/.*/ queries = ["huixiangdou 是什么?", "茴香豆怎么部署到微信群", "今天天气怎么样?"]/' /root/huixiangdou/huixiangdou/main.py# 运行茴香豆
cd /root/huixiangdou/
python3 -m huixiangdou.main --standalone
RAG相当于外挂了一个额外的知识数据库,优点在于可以非参数化的模型调优。
运行截图

3.茴香豆进阶
3.1加入网络搜索
添加网络搜索需要用到Serper提供的API。
流程如下:
1.登录Serper,注册
2.进入 Serper API 界面,复制自己的 API-key:
3.替换 /huixiangdou/config.ini 中的 ${YOUR-API-KEY} 为自己的API-key
注意是[web_search]块的API
Tips:通过调整domain_partial_order 可以设置网络搜索的范围

3.2使用远程模型
目前茴香豆支持Kimi,GPT-4,Deepseek 和 GLM 等常见大模型API。
1.启用远端模型,修改 /huixiangdou/config.ini 文件中

2.修改 remote_ 相关配置,填写 API key、模型类型等参数。
这里可以选择kimi,去官网注册一个账号就可以申请到API

3.3 利用 Gradio 搭建网页 Demo
1.首先,安装 Gradio 依赖组件:
pip install gradio==4.25.0 redis==5.0.3 flask==3.0.2 lark_oapi==1.2.4
2.运行脚本,启动茴香豆对话 Demo 服务:
cd /root/huixiangdou
python3 -m tests.test_query_gradio
3.结果展示

问题:
回答的不正确,有很多问题没法回答,且回答很慢


这篇关于[书生·浦语大模型实战营]——第三节:茴香豆:搭建你的 RAG 智能助理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








