apriori专题
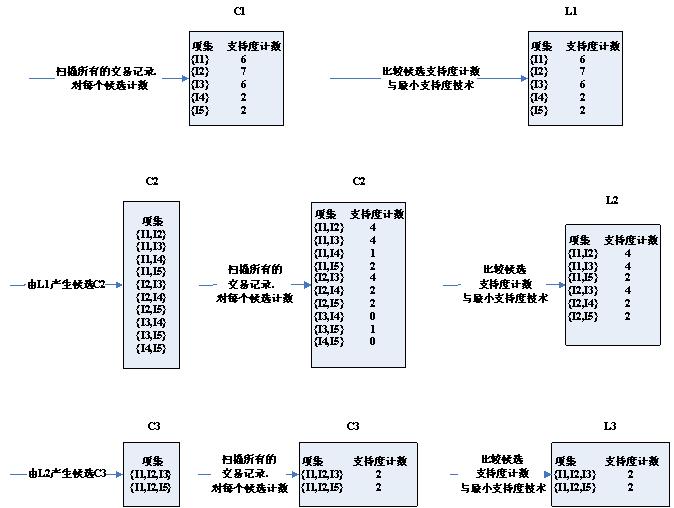
关联规则(一)Apriori算法
此篇文章转自 http://blog.sina.com.cn/s/blog_6a17628d0100v83b.html 个人觉得比课本上讲的更通俗易懂! 1. 挖掘关联规则 1.1 什么是关联规则 一言蔽之,关联规则是形如X→Y的蕴涵式,表示通过X可以推导“得到”Y,其中X和Y分别称为关联规则的先导(antecedent或left-hand-side, LHS)和后

每天一个数据分析题(四百九十八)- Apriori算法
Apriori算法中,候选序列的个数比候选项集的个数大得多,产生更多候选的原因有? A. 一个项在项集中最多出现一次,但一个事件可以在序列中出现多次 B. 一个事件在序列中最多出现一次,但一个项在项集中可以出现多次 C. 次序在序列中和项集中都是重要的 D. 序列不可以合并 数据分析认证考试介绍:点击进入 题目来源于CDA模拟题库 点击此处获取答案 数据分析专项练习题库 内容涵盖

机器学习实战学习笔记 --- Apriori算法
关联分析是一种在大规模数据集中寻找有趣关系的任务。这些关系可以有两种形式: 频繁项集 (frequent item sets):经常出现在一块的物品集合。 关联规则(associational rules):暗示两种物品之间可能存在很强的关系。 相关术语: 关联分析(关联规则学习):从大规模数据集中寻找物品之间的隐含关系被称作关联分析(associati analysis)或

Apriori 处理ALLElectronics事务数据
通过Apriori算法挖掘以下事务集合的频繁项集: 流程图 代码 # 导入必要的库from itertools import combinations# 定义Apriori算法函数def apriori(transactions, min_support, min_confidence):# 遍历数据,统计每个项的支持度 item_support = {}for transa
数据挖掘的Apriori算法
该算法是经典的频繁项集的挖掘算法,主要用的是一个先验性质,任何频繁项集的自己都是频繁的。反过来说,一个项集的有一个子集不是频繁的,那这个项集也不是频繁的。 算法的输入:(1)事务数据库D ID 购买的产品的编号 T100 1,2,3,4 T200 2,3,4,5 T300 1,2,7,5,4 T400 1,2,3,4,5,6,7,8

weka实战005:基于HashSet实现的apriori关联规则算法
这个一个apriori算法的演示版本,所有的代码都在一个类。仅供研究算法参考 package test;import java.util.Collections;import java.util.HashMap;import java.util.HashSet;import java.util.Iterator;import java.util.Vector;//用set写的a

weka实战003:apriori关联规则算法的实现
weka实现的apriori算法是在weka.associations包的Apriror类。 在这个类,挖掘关联规则的入口函数是public void buildAssociations(Instances instances),而instances就是数据集,检查数据,设置参数,初始化变量,然后,用一个do-while循环计算关联规则。如果你看过上一篇,就知道其实就是从一项频繁集开始,逐
weka实战002:apriori关联规则算法
关联规则算法最出名的例子就是啤酒和尿布放一起卖。 假如我们去超市买东西,付款后,会拿到一张购物清单。这个清单就是一个Transaction。对关联规则算法来说,每个产品的购买数量是无意义的,不参与计算。 许许多多的人买东西,生成了N个购物清单,也就是N个Transaction。 那么,这些Transaction上的货物之间有什么有用的关系呢?这些关系可以用什么方式表达出来呢
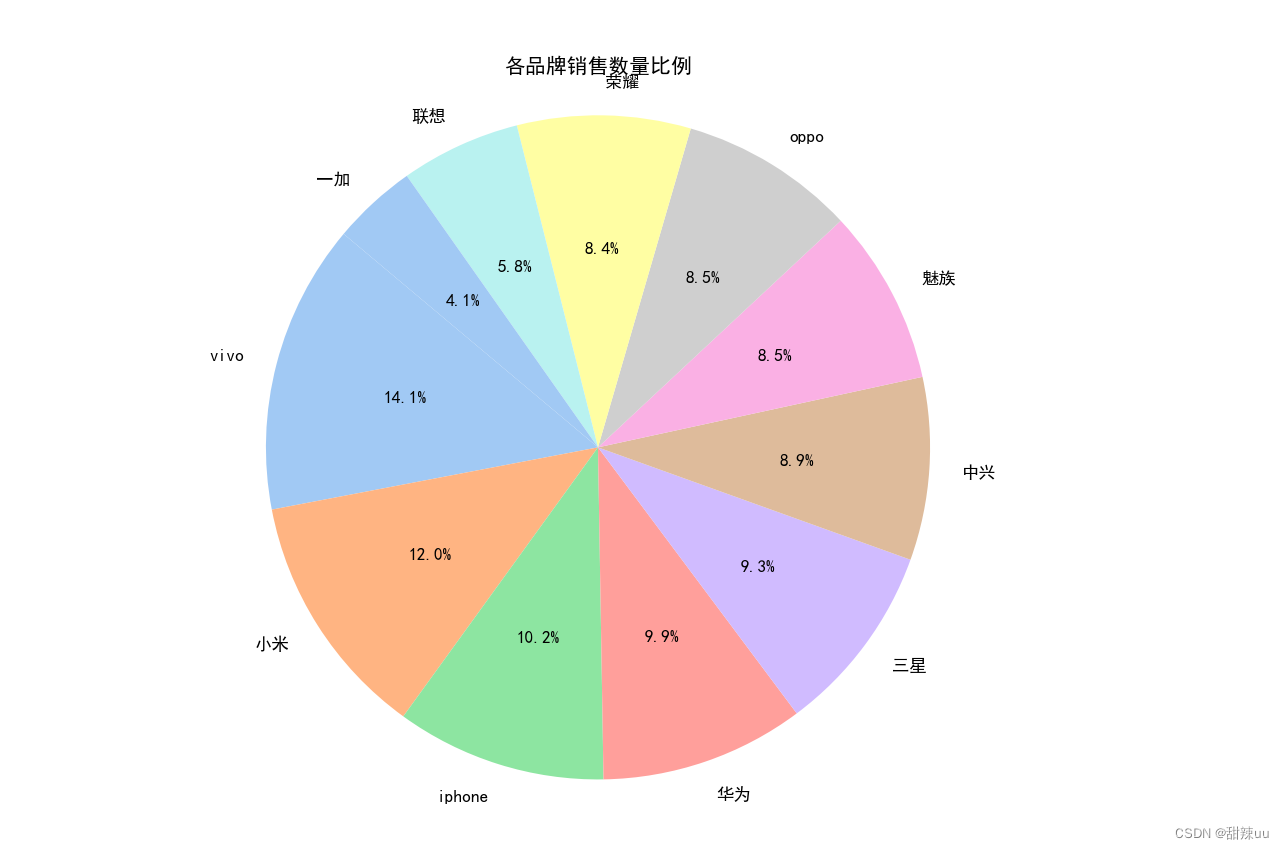
实战16:基于apriori关联挖掘FP-growth算法挖掘关联规则的手机销售分析-代码+数据
直接看视频演示: 基于apriori关联挖掘关联规则的手机销售分析与优化策略 直接看结果: 这是数据展示: 挖掘结果展示: 数据分析展示:

数据挖掘算法之 Apriori
一、什么是Apriori算法? Apriori算法是寻找所有支持度不小于minsup的项集。项集的支持度指的是包含该项集的事务占所有事务的比例。频繁项集指的是满足给定最下支持度的项集 Apriori算法是由Agrawal等人于1993提出的,它采用逐层搜索策略(层次搜索策略)产生所有的频繁项集。 Apriori性质:

【机器学习】Apriori算法在关联规则学习中的应用
探索数据背后的奥秘:Apriori算法在关联规则学习中的魅力 一、关联规则学习的崛起二、Apriori算法的王者之路三、Apriori算法的实际应用 在数字时代的浪潮中,数据正逐渐成为推动社会发展的新引擎。如何从海量数据中挖掘出有价值的信息,成为了各行各业关注的焦点。关联规则学习,作为一种数据挖掘技术,以其独特的“如果…那么…”逻辑结构,在揭示数据之间潜在关系方面发挥着重
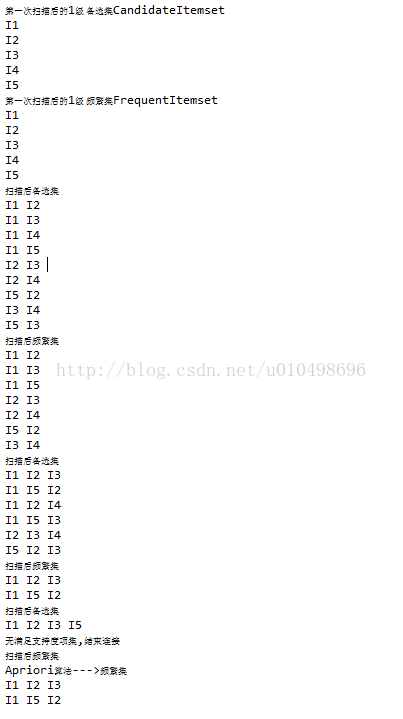
Apriori算法学习和java实现
关联规则挖掘可以发现大量数据中项集之间有趣的关联或相关联系。一个典型的关联规则挖掘例子是购物篮分析,即通过发现顾客放入其购物篮中的不同商品之间的联系,分析顾客的购物习惯,从而可以帮助零售商指定营销策略,引导销售等。国外有"啤酒与尿布"的故事,国内有泡面和火腿的故事。本文以Apriori算法为例介绍关联规则挖掘并以java实现。 什么是关联规则: 对于记录的集合D和记录A,记录B,A,B属于D:

《机器学习实战》笔记之十一——使用Apriori算法进行关联分析
第十一章 使用Apriori算法进行关联分析 Apriori算法频繁项集生成关联规则生成 从大规模数据集中寻找物品间的隐含关系被称作为关联分析(association analysis)和关联规则学习(association rule learning)。 11.1 关联分析 关联分析有两种形式:频繁项集、关联规则。频繁项集(frequent item sets)是经常出现
Apriori算法是关联规则挖掘中很基础也很经典的一个算法
首先,Apriori算法是关联规则挖掘中很基础也很经典的一个算法。 所以做如下补充: 关联规则:形如X→Y的蕴涵式,其中, X和Y分别称为关联规则的先导(antecedent或left-hand-side, LHS)和后继(consequent或right-hand-side, RHS) 。其中,关联规则XY,存在支持度和信任度。 支持度:规则前项LHS和规则后项RHS所包括的商品都同时出现
关联挖掘分析(Apriori算法)
DMQL;16SCREEN中心化趋势度量;离散化趋势度量 https://www.cnblogs.com/en-heng/p/5719101.html
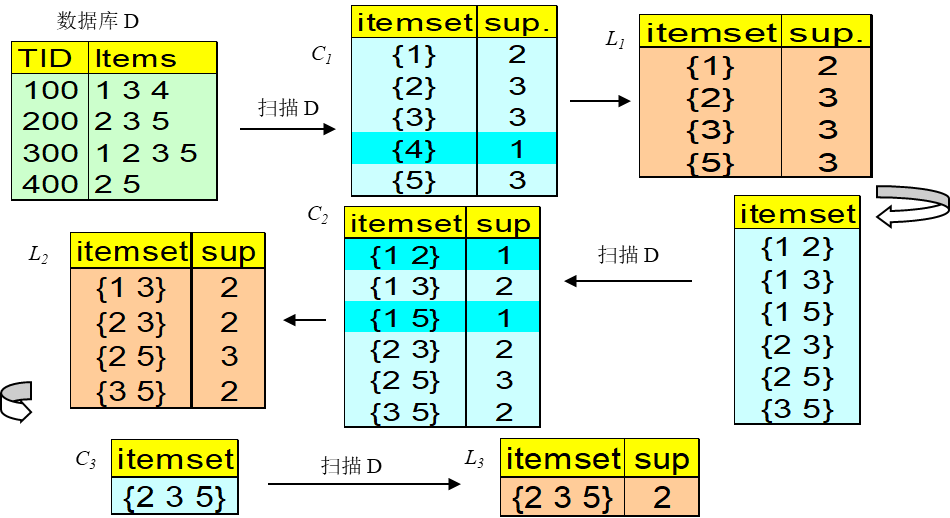
数据挖掘|关联分析与Apriori算法详解
数据挖掘|关联分析与Apriori算法 1. 关联分析2. 关联规则相关概念2.1 项目2.2 事务2.3 项目集2.4 频繁项目集2.5 支持度2.6 置信度2.7 提升度2.8 强关联规则2.9 关联规则的分类 3. Apriori算法3.1 Apriori算法的Python实现3.2 基于mlxtend库的Apriori算法的Python实现 1. 关联分析 关联规则分析
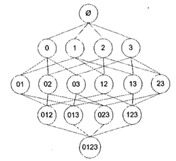
Apriori算法(频繁集发现以及关联分析)
我们在网上购物的时候都会收到一些相关产品的推荐,这些被推荐的东西是怎么来的呢?如果我们买了一个鱼竿,那么推荐鱼线,鱼饵什么的是很正常的,毕竟这些产品都是相关性比较大的,收到推荐也不足为奇;但是仅限于此吗?之前不是有个很出名的例子,啤酒和尿布的例子,在没被发现这个规律之前,谁能想到他们两个有一定的联系?所以除过去那些关联性特别明显的东西,还有许多隐藏的有相关性的关系被隐藏在大量的数据

【关联分析挖掘的Apriori算法】Python自行实现+应用实例
实验分析与设计思路 1.算法原理简述 (1)发现频繁项目集 通过用户给定的最小支持度,寻找所有频繁项目集,即满足support不小于Minsupport的所有项目子集。一般地,我们只关心那些不被其他频繁项目集所包含的所谓最大频繁项目集的集合。发现所有的频繁项目集是形成关联规则的基础。 (2)生成关联规则 通过用户给定的最小可信度,在每个最大频繁项目集中,寻找confidence不小于minco
关联分析 Apriori算法
在日常生活中,我们每个人都会去超市、商场、电商平台购物,每次的购物记录都会进入商家的用户数据库中。商家希望从这些海量的消费记录中,发现一些有价值的规律,来提高自己的盈利水平。 当我们在Amazon上购买图书时,会经常看到下面两个提示:1.这些书会被消费者一起购买,并且价格上有一定的折扣;2.购买了这本书的人,也会购买其他书。Amazon对平台中海量的用户记录进行挖掘,发现了这些规律,然后将这

R语言改进关联规则挖掘Apriori在超市销售数据可视化
全文链接:https://tecdat.cn/?p=33364 超市业已成为商业领域最具活力的商业业态,竞争也变得日益激烈。数据挖掘技术越来越多地服务于超市营销战略,本文在数据挖掘的基础上,深入分析了关联规则算法,研究算法的基本思想、算法的性质,并对算法进行详细的性能分析,比较了Apriori算法和改进Apriori算法。最后,采用R软件对超市数据进行挖掘,为超市营销提供策略(点击文末“阅读原
十七、Apriori算法原理
支持度、置信度和提升度 支持度:是个百分比,指的是某个商品组合出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的频率越大 置信度:是个条件概念,指的是当你购买了商品A,会有多大的概率购买商品B 提升度:商品A的出现,对商品B的出现概率提升的程度,商品A的出现,对商品B的出现概率提升的程度 提升度(A→B)=置信度(A→B)/支持度(B) 提升度(A→B)>1:代表有提升;提升度(
Apriori 与 FP-growth 算法
关联规则挖掘:Apriori 与 FP-growth 算法 关联规则挖掘概述Apriori 算法基本原理应用实例 FP-growth 算法基本原理应用实例 其他机器学习算法:机器学习实战工具安装和使用 关联规则挖掘是数据挖掘领域中的一个重要任务,旨在发现数据集中不同项之间的关联关系。Apriori 算法和 FP-growth 算法是两种常用的关联规则挖掘算法,它们在挖掘频繁项集和
数据挖掘十大经典算法之——Apriori 算法
数据挖掘十大经典算法系列,点击链接直接跳转: 数据挖掘简介及十大经典算法(大纲索引) 1. 数据挖掘十大经典算法之——C4.5 算法 2. 数据挖掘十大经典算法之——K-Means 算法 3. 数据挖掘十大经典算法之——SVM 算法

Apriori算法--关联分析算法(一)
在实际生产生活我们经常会遇到一些“关联分析”(Association Analyse)的任务。举几个实际例子。 1.人们的购物清单里面的各个商品有没有什么关联呢?就像下面这个购物清单写的那样子,右边是各个顾客所买的东西。 有的时候我们想问,顾客购买商品的时候会不会多个商品组合起来买呢?顾客会不会倾向于豆奶和尿布这两样商品一起买?我们怎么从一份购物清单里面发现这种往往会一起出现的商品组合呢?
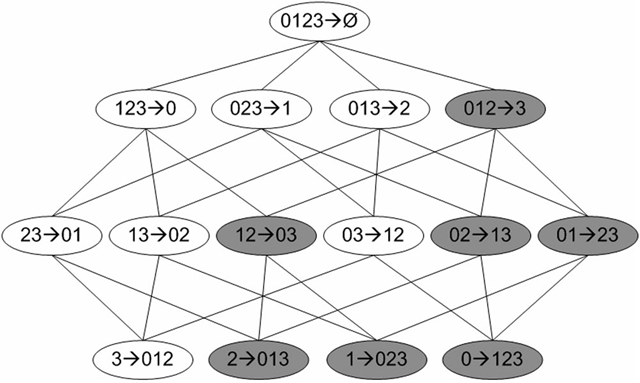
机器学习(二)Apriori算法
最近看了《机器学习实战》中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集)。正如章节标题所示,这两章讲了无监督机器学习方法中的关联分析问题。关联分析可以用于回答”哪些商品经常被同时购买?”之类的问题。书中举了一些关联分析的例子: 通过查看哪些商品经常在一起购买,可以帮助商店了解用户的购买行为。这种从数据海洋中抽取的知识可以用于