霍夫曼专题


算法篇_C语言实现霍夫曼编码算法
一、前言 霍夫曼编码(Huffman Coding)是一种广泛使用的数据压缩算法,特别适用于无损数据压缩。它是由David A. Huffman在1952年提出的,并且通常用于文件压缩和传输中减少数据量。霍夫曼编码的核心思想是使用变长编码表对源数据进行编码,其中较频繁出现的数据项会被赋予较短的编码,而较少出现的数据项则会被赋予较长的编码。 该编码方法通过构建一种特殊的二叉树——霍夫曼树,为数据

数据结构-非线性结构-树形结构:有序树 ->二叉树 ->哈夫曼树 / 霍夫曼树(Huffman Tree)【根据所有叶子节点的权值构造出的 -> 带权值路径长度最短的二叉树,权值较大的结点离根较近】
哈夫曼树概念:给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。 哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。 一、相关概念 二叉树:每个节点最多有2个子树的有序树,两个子树分别称为左子树、右子树。有序的意思是:树有左右之分,不能颠倒 叶子节点:一棵树当中没有子结点的结点称为叶子
java 霍夫曼解码
Huffman Tree 进行解码 示例图 c语言:c语言 霍夫曼编码 | 贪婪算法(Huffman Coding | Greedy Algo)_霍夫曼的贪婪c语言-CSDN博客 c++:c++ 霍夫曼编码 | 贪婪算法(Huffman Coding | Greedy Algo)_霍夫曼的贪婪算法设计核心代码-CSDN博客 c#:C# 霍夫曼编码 | 贪婪算法(Huffman Cod

霍夫曼树教程(个人总结版)
背景 霍夫曼树(Huffman Tree)是一种在1952年由戴维·霍夫曼(David A. Huffman)提出的数据压缩算法。其主要目的是为了一种高效的数据编码方法,以便在最小化总编码长度的情况下对数据进行编码。霍夫曼树通过利用出现频率较高的字符用较短的编码,频率较低的字符用较长的编码,从而实现数据的压缩。 霍夫曼树的思想源于信息论中的熵编码理论,即在保证无损数据传输的前提下,最大限度地减

九度 1107 - 霍夫曼树 - 搬水果
这道题目一开始我用排序来做,每次选择最小的两个,相当于构建了霍夫曼树,最后统计所有非叶子结点之和。但是因为每次排序的基数太大,所以会一直超时。 所以我们用优先队列模拟一个堆,利用最小堆的特征来快速得到最小的两个数。STL带有优先队列-priority_queue。 priority_queue 对于基本类型的使用方法相对简单。他的模板声明带有三个参数: priority_queue<Ty
微软人工智能在伦敦设立新中心,由前 Inflection 和 Deepmind 科学家乔丹-霍夫曼(Jordan Hoffmann)担任负责人
微软宣布为其新近成立的消费人工智能部门设立一个新的伦敦中心。该中心将由乔丹-霍夫曼(Jordan Hoffmann)领导,他是微软最近从备受瞩目的人工智能初创公司Inflection AI(微软去年投资了该公司)挖来的一名人工智能科学家和工程师。 这一消息是在微软首席执行官萨蒂亚-纳德拉(Satya Nadella)发布由Inflection AI创始人领导的新消费人工智能部门约三周后发布的,I
完全二叉树与满二叉树 霍夫曼树
http://blog.csdn.net/yelbosh/article/details/8043476 其实满二叉树是完全二叉树的特例,因为满二叉树已经满了,而完全并不代表满。所以形态你也应该想象出来了吧,满指的是出了叶子节点外每个节点都有两个孩子,而完全的含义则是最后一层没有满,并没有满。 满二叉树(Full Binary Tree):除最后一层无任何子节点外,每一层上的所有结点都有
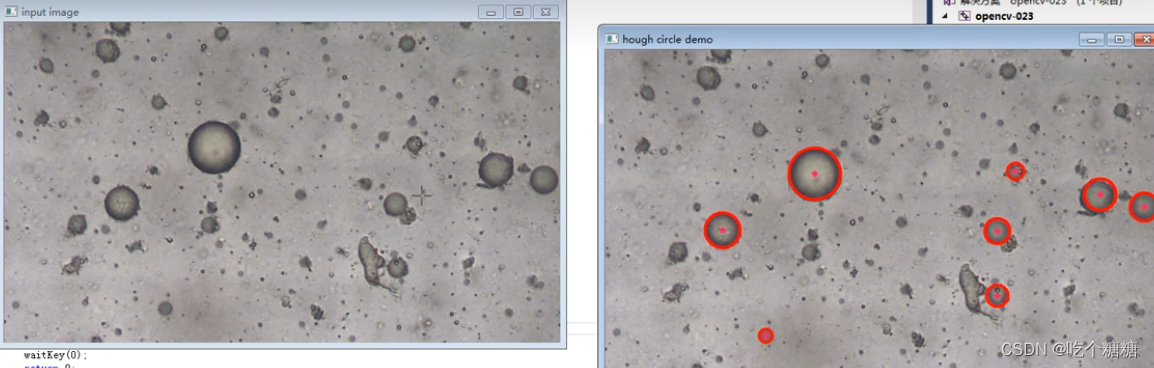
19 OpenCV 霍夫曼变换检测圆
文章目录 cv::HoughCircles算子参数示例 cv::HoughCircles 因为霍夫圆检测对噪声比较敏感,所以首先要对图像做中值滤波。 基于效率考虑,Opencv中实现的霍夫变换圆检测是基于图像梯度的实现,分为两步: 检测边缘,发现可能的圆心基于第一步的基础上从候选圆心开始计算最佳半径大小 算子参数 HoughCircles(InputArray ima

哈夫曼树、霍夫曼树、最优二叉树
哈夫曼树、霍夫曼树、最优二叉树 前言哈夫曼树的算法思想总结 前言 霍夫曼树一般为哈夫曼树,而最优二叉树,也是哈夫曼树,他们的最终目的都只有一个,要确定最短的编码长度,即频次高的编码长度少,频率低的编码长度长。 哈夫曼树的算法思想 例如: 一组数据的频次为[1,3,5,7,9]则我们在建立哈夫曼树的时候,需要从底向上的依次建立。取出数据中权值(频次)最小的两个数据,将

统一编码-香浓编码-霍夫曼编码
香浓编码中所谓的从上到下的编码方式的意思就是说:首先是符号按照其出现的频率从小到大(或从大到小)进行排序,然后按照中出现的频率一半一半地分,最后得到的编码就是香浓编码。例如:先有符号A:12,B:9,C:5,D:4,E:2,F:2 那么按照香浓编码,先分组:(A,B),(C,D,E,F)因为这时为21:13两边较为均衡,然后再左右分(C),(D,E,F),再分(D),(E,F)最后就得到了这棵树
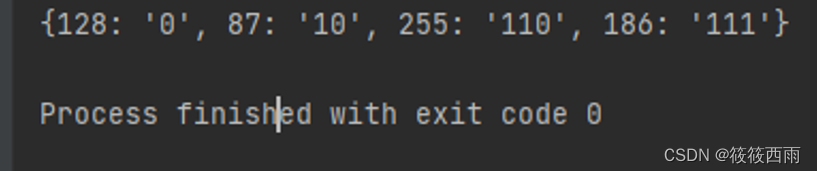
无失真编码之霍夫曼编码的python实现——数字图像处理
原理 无失真编码是一种数据压缩技术,其中原始数据在压缩后可以完全无损地恢复。霍夫曼编码是一种广泛使用的无失真编码方法。它基于字符出现的频率构建一个最优的前缀编码树,其中没有任何编码是另一个编码的前缀。这样,即使在压缩后,原始数据也可以完全无误地被解码和恢复。霍夫曼编码的原理可以分为以下几个步骤: 1. 统计字符频率 首先,统计待编码数据中每个字符的出现频率。这个频率信息是构建霍夫曼树的基础。
压缩算法,对霍夫曼编码的改进
背景 霍夫曼编码是理论上的最优编码,但是,它依赖于“分割点”。例如,在源代码里,有大量的"if",把多个字母合并成一个符号,似乎更好。 霍夫曼编码的极端情况,以1比特为单位进行编码。只有两个符号,用1比特表示这两个符号,用0表示0,用1表示1。结果是,并没有被压缩。 算法 压缩前的串为A,压缩后的串为B。 首先,对A进行统计。 按1字节统计,得到256个概率值; 按2字节统计,得到2562个
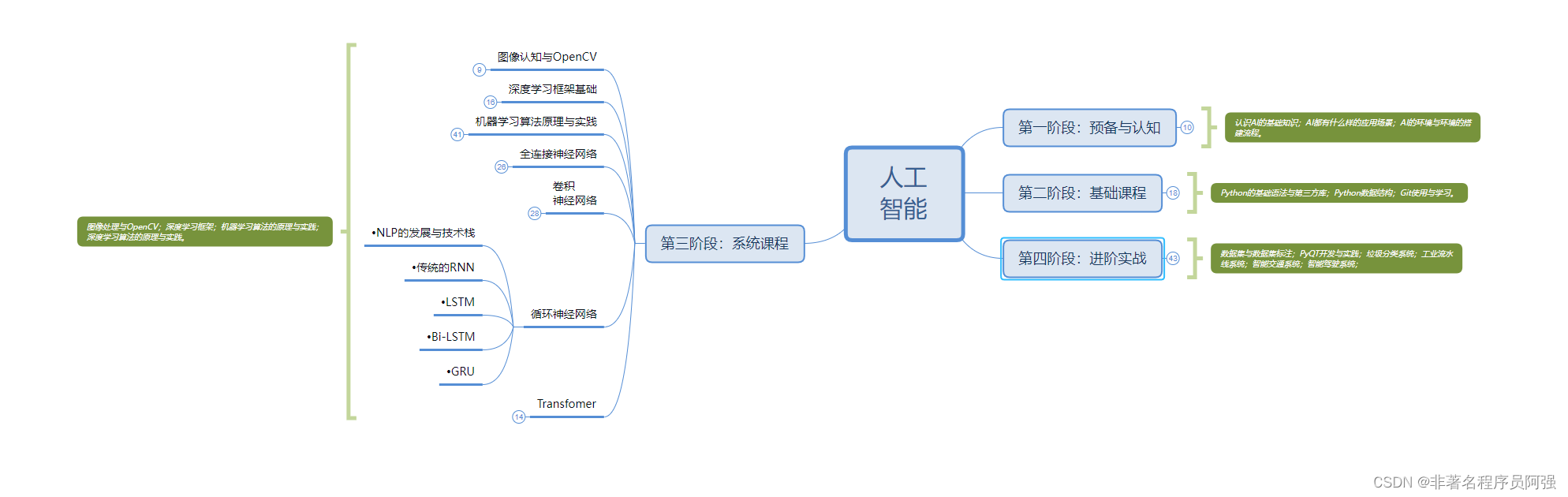
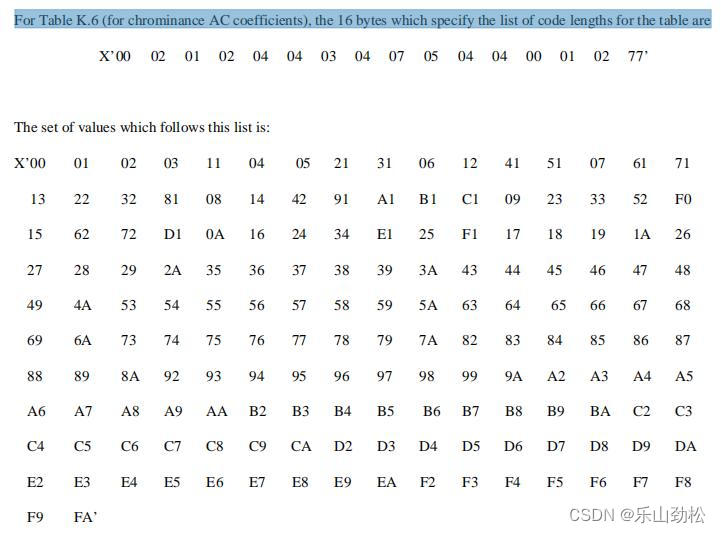
c jpeg 理论霍夫曼 DC AC表,c程序实现正向逆向转换
此4张表是理论表,不是针对某张图片的特定表。如编码程序不统计生成某图片的专用霍夫曼表,应该也可用理论表代用编码。 1.亮度DC表 左边第一列是二进制位数,就是对此位数编码 中间一列是生成比特流的位数,右边是生成的比特流。 2.色度DC表 3.亮度AC表 4. 色度AC表 利用这4张表转换生成亮度,色度的DC,AC比特流 图3图4两张表是用jpeg文件头的
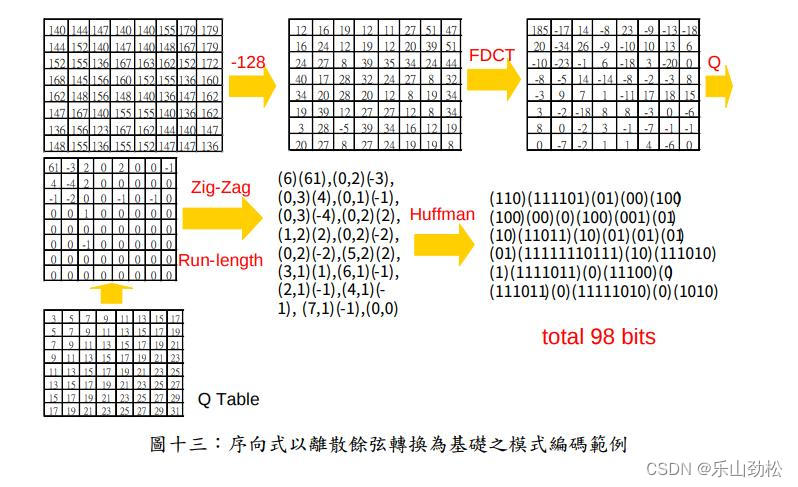
c YUV 转 JPEG(准备霍夫曼编码)
先取yuv 文件中一个16×8的块,跑通全流程 理解与思路: 1.块分割 YUV 文件分为:YUV444 YUV 422 YUV420。444:就是:12个char 有4个Y,4个U,4个 U,422:8个char 中有4个Y ,U,V各两个,420:意思就是8char里有6个Y,1个U,1个V。444与422 中的三分量多是交错存储的,420则是先存储Y,再存储U,
c YUV 转 JPEG(准备霍夫曼编码)
先取yuv 文件中一个16×8的块,跑通全流程 理解与思路: 1.块分割 YUV 文件分为:YUV444 YUV 422 YUV420。444:就是:12个char 有4个Y,4个U,4个 U,422:8个char 中有4个Y ,U,V各两个,420:意思就是8char里有6个Y,1个U,1个V。444与422 中的三分量多是交错存储的,420则是先存储Y,再存储U,

【图像压缩】基于霍夫曼编码的JPEG图像压缩(压缩比+信噪比)附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,matlab项目合作可私信。 🍎个人主页:Matlab科研工作室 🍊个人信条:格物致知。 更多Matlab仿真内容点击👇 智能优化算法 神经网络预测 雷达通信 无线传感器 电力系统 信号处理 图像处理 路径规划
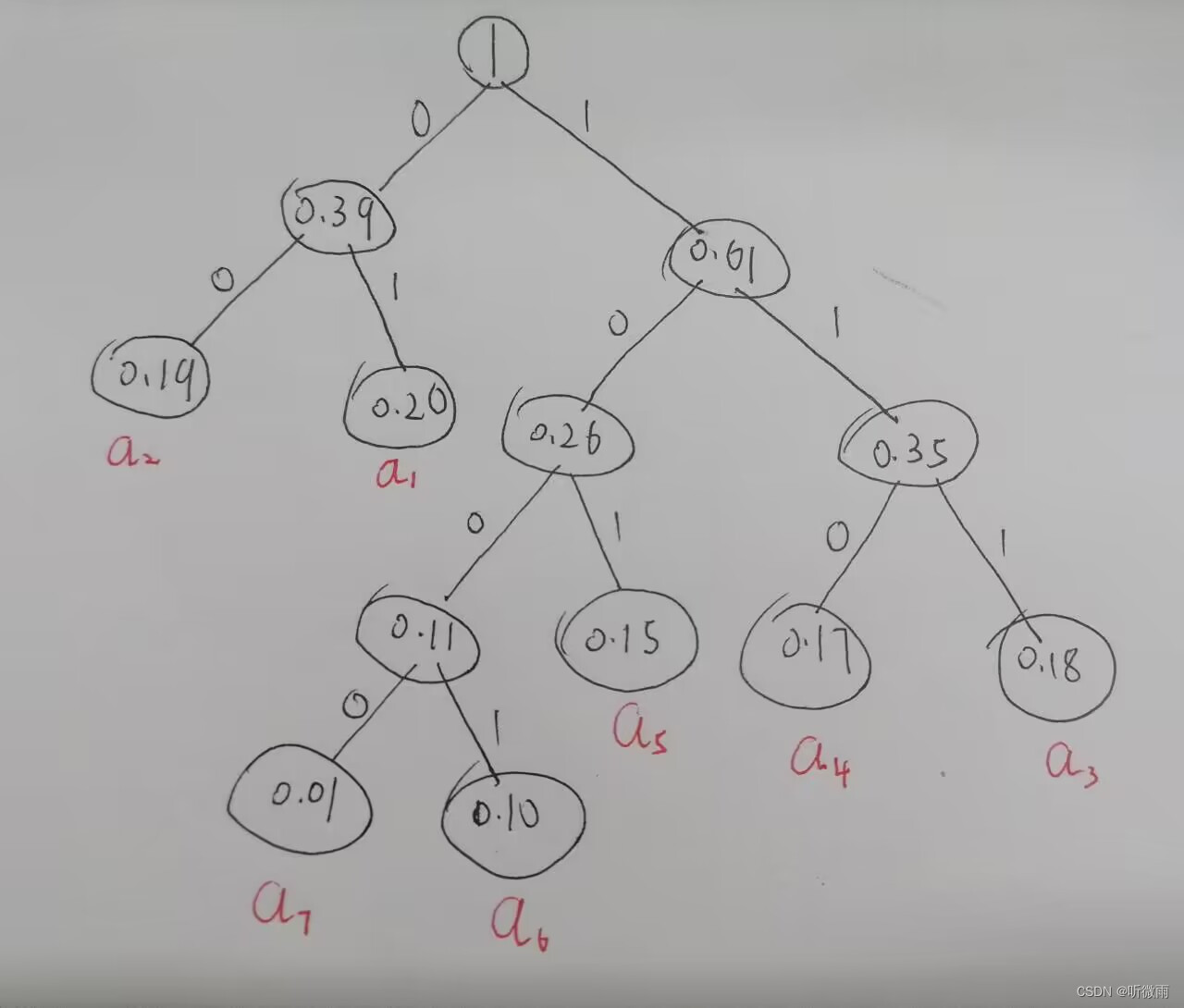
哈夫曼编码(霍夫曼、赫夫曼)
一、发展历史 哈夫曼使用自底向上的方法构建二叉树。 哈夫曼编码的基本方法是先对图像数据扫描一遍,计算出各种像素出现的概率,按概率的大小指定不同长度的唯一码字(这种长度不同的编码方式称为变长编码,对应的长度相同的编码方式叫定长编码),由此得到一张该图像的哈夫曼码表。编码后的图像数据记录的是每个像素的码字,而码字与实际像素值的对应关系记录在码表中。 (同理也可对字符数据,扫描字符数据,计算各字符出

霍夫曼編碼(英語:),又譯為哈夫曼编码、赫夫曼编码,是一種用於无损数据压缩的熵編碼(權編碼)演算法。由美國計算機科學家大衛·霍夫曼()在1952年發明。
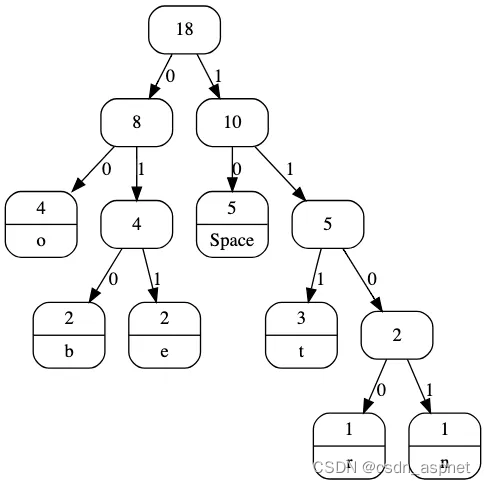
霍夫曼编码 霍夫曼編碼(英語:),又譯為哈夫曼编码、赫夫曼编码,是一種用於无损数据压缩的熵編碼(權編碼)演算法。由美國計算機科學家大衛·霍夫曼()在1952年發明。 這個句子“this is an example of a huffman tree”中得到的字母頻率來建構霍夫曼樹。句中字母的編碼和頻率如圖所示。編碼此句子需要135 bit(不包括保存树所用的空間) 字母頻率編碼space

ACM基础(四):树之Huffman Coding哈夫曼(霍夫曼)编码
文章目录 一、原理二、伪代码 一、原理 频率: 原理: 构造的方法就是将所有的指令按使用的频度(也就是程序中出现的概率)由小到大依次排列,每次将两个使用频度最小合并在一起,构成一个频度为两者之和的新结点,将其与余下的结点放在一起。接着再从这些结点中继续找两个使用频度最小合并在一起,构成一个频度为两者之和的新结点。重复上述过程,全部结点合并完成。 过
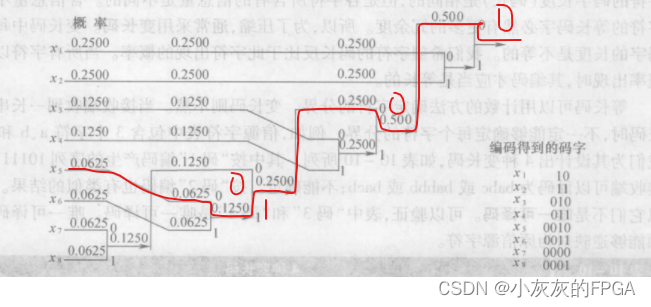
通信原理板块——数字数据压缩编码之霍夫曼编码
1、数字数据压缩编码基本原理 数据分为数字数据和模拟数据,此处的数据指的是数字数据或数字化后的模拟数据 (1)数字数据压缩编码要求 数据与语音或图像不同,对其压缩是不允许有任何损失,只能采用无损压缩的方式。压缩编码选用一种高效的编码表示信源数据,以减小信源数据的冗余度,即减小其平均比特数。并且,这种高效编码必须易于实现和能逆回原信源编码。 (2)熵编码 信源的熵的定义,表示信源中每个符号所含信息量