本文主要是介绍通信原理板块——数字数据压缩编码之霍夫曼编码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、数字数据压缩编码基本原理
数据分为数字数据和模拟数据,此处的数据指的是数字数据或数字化后的模拟数据
(1)数字数据压缩编码要求
数据与语音或图像不同,对其压缩是不允许有任何损失,只能采用无损压缩的方式。压缩编码选用一种高效的编码表示信源数据,以减小信源数据的冗余度,即减小其平均比特数。并且,这种高效编码必须易于实现和能逆回原信源编码。
(2)熵编码
信源的熵的定义,表示信源中每个符号所含信息量的统计平均值。减小信源数据的冗余度,相当于增大信源的熵。编码称为熵编码
(3)信源字符表
一个有限离散信源可以用一组不同字符xi(i=1,2,……,N)的集合X(N)表示。X(N)称为信源字符表,表中的字符为x1,x2,……,xn。信源字符表可以是二进制的,也可使多字符的,非二进制字符可以通过一个字符编码表映射为二进制码字。标准的字符二级制码字是等长的
(4)等长码和变长码
等长码中表示每个字符的码字长度是相同的,但是各字符所含有的信息量是不同的。含信息量小的字符的等长码字必然有更多的冗余度。
为了压缩,通常采用变长码。变长码中每个码字的长度是不等的,字符的码长反比于此字符出现的概率。当多有字符以等概率出现时,编码才是等长的。
等长码可以通过计数的方法确定字符的分界,但变长码则不可以,接收端收到一长串变长码,不一定能确定每个字符的分界。
为了压缩数据,常采用变长码,以求获得高的压缩效果,常见编码方式有霍夫曼(Huffman)编码、香农-费诺编码等
2、霍夫曼编码(Huffman)
霍夫曼编码是一种无前缀变长码。对于给定熵的信源,霍夫曼编码能得到最小平均码长。在最小码长意义上,霍夫曼编码是最佳编码,也是效率最高的编码。
(1)一个霍夫曼编码的示例
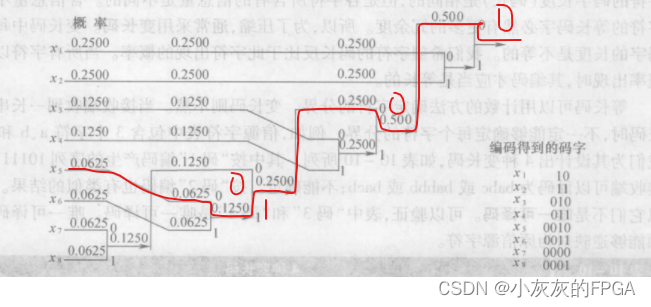
以8个字符的信源字符表来说明下霍夫曼编码的编码方式
设信源的输出字符为x1,x2,x3,x4,x5,x6,x7,x8
对应概率分别为
P(x1)=P(x2)=1/4
P(x3)=P(x4)=1/8
P(x5)=P(x6)=P(x7)=P(x8)=1/16
采用霍夫曼编码的过程
①将8个字符按照概率不增大的次序排序
②将概率最小的两个信源字符x7和x8合并,将x7分配二进制“0”作为其码字的最后一个码元;x8分配二进制“1”作为其码字的最后一个码元
③x7和x8合并后的复合字符的概率为P(x7)+P(x8)=1/8,并将新得到一组字符按照概率不增大的次序排列,注意:新复合字符与x3和x4概率相同,可放置在x2和x5之间的任何位置,此例子放置在x4之后,替换x5;
④将排序后的x6和x7合并,按照概率不增大的次序排列;
⑤最终得到一个下述的树状图;
⑥从树的最右端向左追踪,即可得到编码输出码字
以x5的码字获得来描述下,图中红线为x5的路径,从树的最右端向左追踪可得到编码为0010;其余类似
(2)压缩比和编码效率
用压缩比和编码效率来反映压缩编码性能的指标
压缩比是压缩前(采用等长码)每个字符的平均码长与压缩后每个字符的平均码长之比
编码效率等于编码后的字符平均信息量(熵)与编码平均码长之比
以上述霍夫曼编码示例来计算
若采用等长码对信源字符编码,由于存在8(2^3)种字符,故码长为3
编码后的字符平均信息量(熵)的计算
H(x)=
P(x1)[-log2(P(x1))]+P(x2)[-log2(P(x2))]+
P(x3)[-log2(P(x3))]+P(x4)[-log2(P(x4))]+
P(x5)[-log2(P(x5))]+P(x6)[-log2(P(x6))]+
P(x7)[-log2(P(x7))]+P(x8)[-log2(P(x8))]
=2×1/4×[-log2(1/4)]+2×1/8×[-log2(1/8)]
+4×1/16×[-log2(1/16)]
= 2.75(b)
编码平均码长
n1×P(x1)+n2×P(x2)+n3×P(x3)+n4×P(x4)+
n5×P(x5)+n6×P(x6)+n7×P(x7)+n8×P(x8)
=2×0.25+2×0.25+3×0.125+3×0.125
+4×0.0625+4×0.0625+4×0.0625+4×0.0625
=2.75
故压缩比=
(压缩前(采用等长码)每个字符的平均码长)/压缩后每个字符的平均码长
=3/2.75=1.09
编码效率=
(编码后的字符平均信息量(熵))/(编码平均码长)
=2.75/2.75=100%
这篇关于通信原理板块——数字数据压缩编码之霍夫曼编码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






