邻近专题

自然语言处理(NLP)-第三方库(工具包):Annoy 【向量最邻近检索工具】
自然语言处理(NLP)-第三方库(工具包):Annoy 【向量最邻近检索工具】 参考资料: 推荐系统的向量检索工具: Annoy & Faiss

自然语言处理(NLP)-第三方库(工具包):Faiss【向量最邻近检索工具】【为稠密向量提供高效相似度搜索】【多种索引构建方式,可根据硬件资源、数据量选择合适方式】【支持十亿级别向量的搜索】
一、Faiss介绍 Faiss是Facebook AI团队开源的针对聚类和相似性搜索库,为稠密向量提供高效相似度搜索和聚类,支持十亿级别向量的搜索,是目前最为成熟的近似近邻搜索库。它包含多种搜索任意大小向量集(备注:向量集大小由RAM内存决定)的算法,以及用于算法评估和参数调整的支持代码。Faiss用C++编写,并提供与Numpy完美衔接的Python接口。除此以外,对一些核心算法提供了GPU实

机器学习/数据分析--通俗语言带你入门K-邻近算法(结合案例)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 前言 机器学习是深度学习和数据分析的基础,接下来将更新常见的机器学习算法注意:在打数学建模比赛中,机器学习用的也很多,可以一起学习欢迎收藏 + 点赞 + 关注 文章目录 K-邻近算法模型简介1、模型简介2、模型难点与求解KNN难点解决方法K值选取问题选取K值后,如何遍历速度最快距离选取欧式距离曼

sklearn k最邻近算法
1、介绍 k最邻近算法可以说是一个非常经典而且原理十分容易理解的算法,可以应用于分类和聚合。 优点 : 1、简单,易于理解,易于实现,无需估计参数,无需训练; 2、适合对稀有事件进行分类; 3、特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好; 缺点: 1、对规模超
《机器学习实战(Scala实现)》(二)——k-邻近算法
算法流程 1.计算中的set中每一个点与Xt的距离。 2.按距离增序排。 3.选择距离最小的前k个点。 4.确定前k个点所在的label的出现频率。 5.返回频率最高的label作为测试的结果。 实现 python # -*- coding: utf-8 -*- '''Created on 2017年3月18日@author: soso'''from numpy impo

离我最近之geohash算法(增加周边邻近编号)
接着上一篇文章:查找附近网点geohash算法及实现 (Java版本) http://blog.csdn.net/sunrise_2013/article/details/42024813 参考文档: http://www.slideshare.net/sandeepbhaskar2/geohash 介绍geohash原理及例子 http://geohash.gofreerange.com
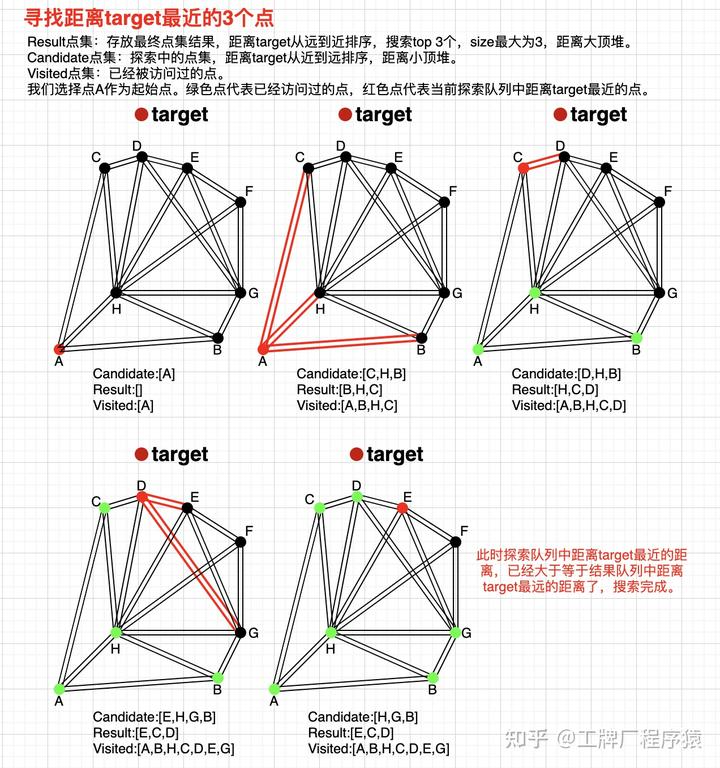
数据检索:倒排索引加速、top-k和k最邻近
之前在https://www.yuque.com/treblez/qksu6c/wbaggl2t24wxwqb8?singleDoc# 《Elasticsearch: 非结构化的数据搜索》我们看了ES的设计,主要侧重于它分布式的设计以及LSM-Tree,今天我们来关注算法部分:如何进行检索算法的设计以及如何加速倒排索引。然后看看topk的面试热门题如何解决。 状态检索:bitmap的哈希函数公式

《统计学习方法:李航》笔记 从原理到实现(基于python)-- 第3章 k邻近邻法
文章目录 第3章 k邻近邻法3.1 k近邻算法3.2 k近邻模型3.2.1 模型3.2.2 距离度量3.2.3 k值的选择3.2.4 分类决策规则 3.3 k近邻法的实现:kd树3.3.1 构造kd树3.3.2 搜索kd树 算法实现课本例3.1iris数据集scikit-learn实例kd树:构造平衡kd树算法例3.2 《统计学习方法:李航》笔记 从原理到实现(基于python)

Open3D 基于kdtree树的邻近点搜索(10)
Open3D 基于kdtree树的邻近点搜索(10) 一、算法简介二、算法实现1.K邻近点搜索2.R邻域点搜索 三、结果释义 一、算法简介 KD 树(k-dimensional tree)是一种用于组织 k 维空间中点的数据结构,旨在提供高效的 k 最近邻搜索和范围搜索(如半径邻域搜索)。KD 树通过递归地将空间划分为多个超立方体区域来组织数据。这种分割方式使得 KD 树能够在

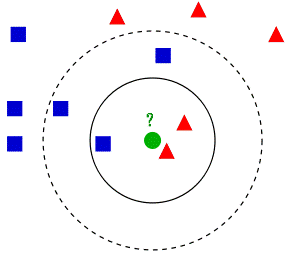
交友系统设计:哪种地理空间邻近算法更快?
小熊学Java:https://javaxiaobear.cn 交友与婚恋是人们最基本的需求之一。随着互联网时代的不断发展,移动社交软件已经成为了人们生活中必不可少的一部分。然而,熟人社交并不能完全满足年轻人的社交与情感需求,于是陌生人交友平台悄然兴起。 我们决定开发一款基于地理位置服务(LBS)的应用,为用户匹配邻近的、互相感兴趣的好友,应用名称为“Liao”。 Liao 面临的技术挑战包

基于GIS的建筑物邻近度计算工具及计算实例经验分享
目录 一、工具介绍1、工具界面2、计算结果示例3、计算原理 二、数据准备三、计算步骤1、生成渔网2、工具计算3、计算结果4、计算结果(马赛克) 一、工具介绍 利用C#语言,基于ArcGIS二次开发实现了建筑物邻近度计算工具,计算工具安装和使用简单,作为插件在ArcMap软件里运行,支持ArcGIS10.2及以上版本ArcMap。 1、工具界面 2、计算结果示例 3
SKIL/工作流程/KNN(K邻近值算法)
K邻近值算法 除了部署转换和网络模型,SKIL还允许你部署KNN模型。 KNN (k邻近值算法) 是最简单的分类算法之一,广泛用于解决机器学习的基本问题。通过计算输入数据和数据集中所有示例之间的相似度(或距离)函数,找出最接近给定数据点的示例。knn中的“k”表示算法在对数据执行时,我们希望获得的最接近的示例的“k”个分类数。 K邻近值算法流程 该工作流程涉及到生成一个二进制KNN向

数字图像处理实验记录三(双线性插值和最邻近插值)
前言:个人实验记录,仅供学习参考,实验报告别用我图 文章目录 一、基础知识1,为什么要进行插值:2,双线性插值原理:3,最邻近插值: 二、实验要求:1.分别编程实现最近邻插值和双线性插值。2.任意读入一幅图像,通过上诉两种插值方法,将图像放大2及2.5倍。3. 显示结果,并进行比较。 三、实验记录:1,双线性:2、最邻近:3,主程序: 四、结果展示1,原图:2,长宽各放大2倍:3,长宽各放大
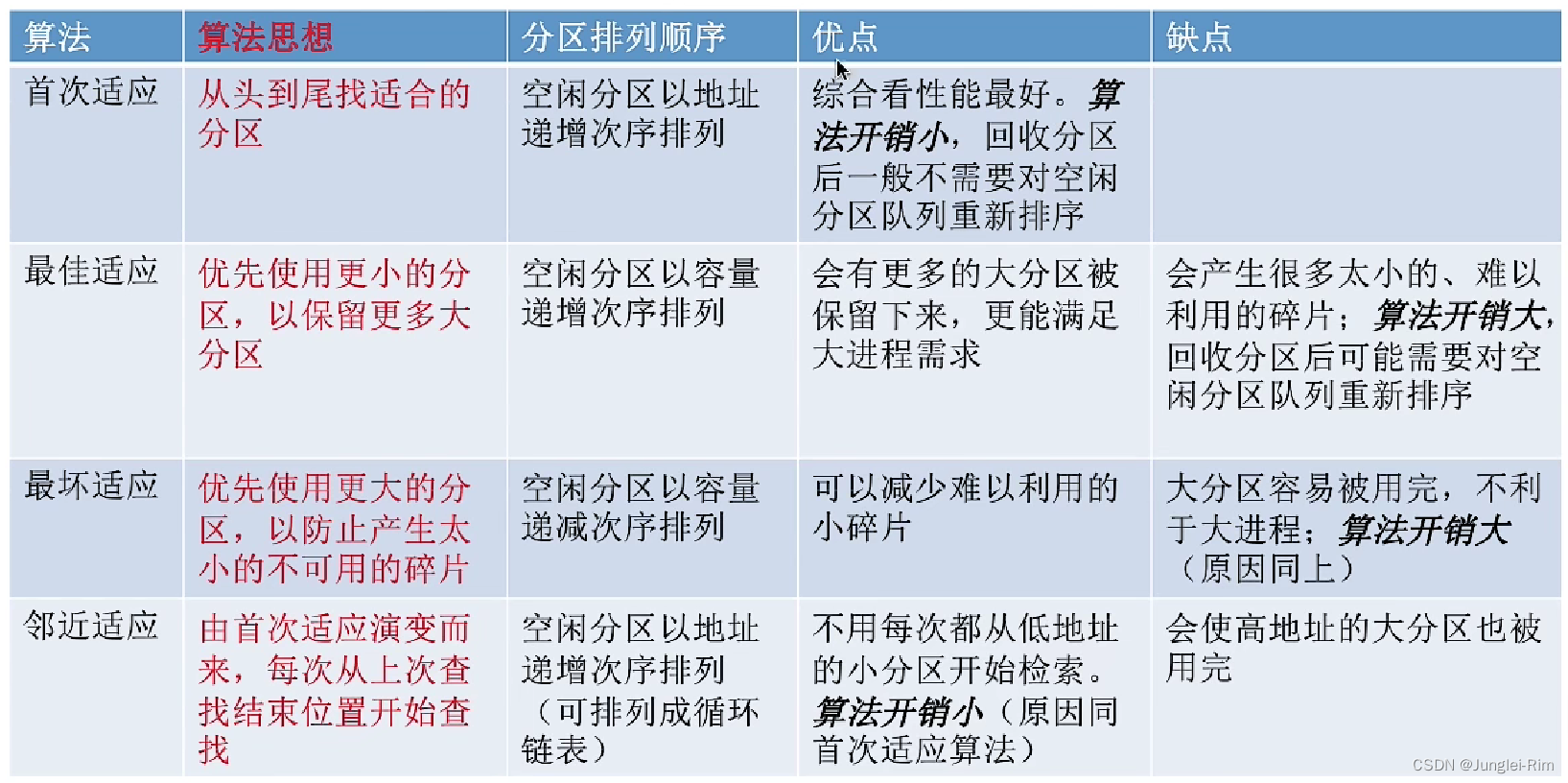
动态分区分配算法之首次适应算法,最佳适应算法,最坏适应算法以及邻近适应算法
1.首次适应算法(First Fit) 1.算法思想: 每次都从低地址开始查找,找到第一个能满足大小的空闲分区。 2.如何实现: 空闲分区以地址递增的次序排列。 每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。 空闲分区表: 空闲分区链: 2.最佳适应算法(Best Fit) 1.算法思想: 由于动态分区分配是一种连续分配方式,为各进程分配
动态分区分配算法之首次适应算法,最佳适应算法,最坏适应算法以及邻近适应算法
1.首次适应算法(First Fit) 1.算法思想: 每次都从低地址开始查找,找到第一个能满足大小的空闲分区。 2.如何实现: 空闲分区以地址递增的次序排列。 每次分配内存时顺序查找空闲分区链(或空闲分区表),找到大小能满足要求的第一个空闲分区。 空闲分区表: 空闲分区链: 2.最佳适应算法(Best Fit) 1.算法思想: 由于动态分区分配是一种连续分配方式,为各进程分配

K邻近算法k值选取以及kd树概念、原理、构建方法、最近邻域搜索和案例分析
一、k值选择 K值过小:容易受到异常点的影响k值过大:受到样本均衡的问题 近似误差:对现有训练集的训练误差,关注训练集,如果近似误差过小可能会出现过拟合的现象,对现有的训练集能有很好的预测,但是对未知的测试样本将会出现较大偏差的预测。模型本身不是最接近最佳模型 估计误差:可以理解为对测试集的测试误差,关注测试集,估计误差小说明对未知数据的预测能力好,模型本身最接近最佳模型 选择较小的K值,