本文主要是介绍邻近 算法 理论,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
K近邻模型由三个基本要素组成:
距离度量;
k值的选择;
分类决策规则
K近邻算法的核心在于找到实例点的邻居。
估算不同样本之间的相似性(SimilarityMeasurement)通常采用的方法就是计算样本间的“距离”(Distance),相似性度量方法有:欧氏距离、余弦夹角、曼哈顿距离、切比雪夫距离等。
欧氏距离
欧氏距离(EuclideanDistance)是最易于理解的一种距离计算方法,源于欧氏空间中的两点之间的距离公式。

曼哈顿距离
红线代表曼哈顿距离,绿色代表欧氏距离,也就是直线距离,而蓝色和黄色代表等价的曼哈顿距离。曼哈顿距离又叫作出租车距离或城市街区距离。

切比雪夫距离

余弦夹角

K值的选择
从最开始的例子可以看到, 当K=3时,绿色圆点被分为了红色三角形一类。K=5时,绿色圆点被分为蓝色正方形一类。说明,k值的选择会对k近邻法的结果产生重大影响。
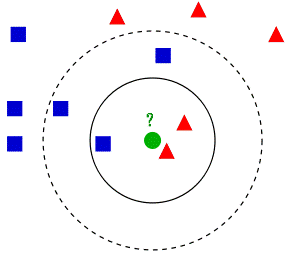
(1)k值较小,只有与输入实例较近(相似)的训练实例才会对预测结果起作用,预测结果会对近邻实例点非常敏感。如果近邻实例点恰巧是噪声,预测就会出错。容易发生过拟合。
(2)若k较大,与输入实例较远的(不相似的)训练实例也会对预测起作用,容易使预测
出错。k值的增大就意味着整体的模型变简单。
(3)如果k=N,那么无论输入实例是什么,都将简单地预测它属于在训练实例中最多的类。这时,模型过于简单,完全忽略训练实例中的大量有用信息,是不可取的。
在应用中,k值一般取较小值。通常通过经验或交叉验证法来选取最优的k值。
分类决策准则
投票表决:
少数服从多数,输入实例的k个近邻中哪个类的实例点最多,就分为该类。
加权投票法(改进):
根据距离的远近,对K个近邻的投票进行加权,距离越近则权重越大(比如权重为距
离的倒数)。
K近邻算法思想
KNN具体算法实现过程如下:
(1)计算当前待分类实例与训练数据集中的每个样本实例的距离;
(2)按照距离递增次序排序;
(3)选取与待分类实例距离最小的k个训练实例;
(4)统计这k个实例所属各个类别数;
(5)将统计的类别数最多的类别作为待分类的预测类别。
使用算法的一般流程
算法的一般流程:
(1)数据处理:准备,分析数据,进行归一化等。
(2)训练算法:利用训练样本训练分类器(模型)。
(3)测试算法:利用训练好的分类器预测测试样本,并计算错误率。
(4)使用算法:对于未知类别的样本,预测其类别。
测试k近邻分类器性能的流程:
(1)数据处理:归一化等(具体情况具体对待)
(2)测试算法:根据K近邻分类算法(函数classify0())预测测试样本类别,并计算错误率。
(3)使用算法:当输入新的未知类别样本,利用算法预测结果。
如何测试分类器性能
获取分类器以后,需测试分类器的效果,可以通过检测分类器给出的答案是否符合我们预期的结果。比如,可以使用已知答案的数据(已知类别标签),当然答案不能告诉分类器,检测由分类器给出的结果(预测类别)是否与数据的真实结果(真实类别)一致。
一个分类器的性能的好坏最简单的评价方法就是,计算其分类错误率。错误率即为测试数据中分类错误的数据个数除以测试数据总数。
错误率越低分类器的分类性能越好,错误率越高,分类性能就越差。
如何测试分类器性能
通常提供的数据集没有区分训练样本和测试样本。
如下为简单交叉验证:
从数据集中选取90%作为训练样本来训练分类器;而使用剩下的10%的样本数据来测试分类器。
其中10%的测试数据应该是从所提供的数据集中随机抽取的,可以多次随机抽取取平均的结果作为最终的检测分类器的错误率。
这篇关于邻近 算法 理论的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








