本文主要是介绍SKIL/工作流程/KNN(K邻近值算法),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
K邻近值算法
除了部署转换和网络模型,SKIL还允许你部署KNN模型。
KNN (k邻近值算法) 是最简单的分类算法之一,广泛用于解决机器学习的基本问题。通过计算输入数据和数据集中所有示例之间的相似度(或距离)函数,找出最接近给定数据点的示例。knn中的“k”表示算法在对数据执行时,我们希望获得的最接近的示例的“k”个分类数。
K邻近值算法流程
该工作流程涉及到生成一个二进制KNN向量文件,其中包含将在其上执行K邻近值算法的数据集。向量文件将包含行向量,表示数据集中的每个示例。有一个可选的标签文件,其中包含表示数据集中每个示例行数据向量的标签。如果没有提供,则在查询模型时,数据集中行向量的索引将作为标签返回,或者在标签字段中返回“None”字符串。
这些步骤可以概括为:
- 收集要表示为数据集的数据,其中每个示例都以行向量形式表示。
- 创建一个标签文件,表示数据集中每个数据点的标签。
- 使用BinarySerde和INDArray以二进制形式保存数据集。
- 保存标签文件,其中每一行包含数据集中每个数据点的标签,每个数据点位于不同的行中。
- 部署时导入KNN模型和标签文件。
- 查询KNN模型。
下面的示例将演示所有这些步骤。
示例
0. 载加依赖
本演示使用SMILE库计算任何k-means 数据的质心。要使用SMILE库,请在笔记本中加载以下依赖项。
%spark.depz.load("com.github.haifengl:smile-core:jar:1.5.1")1. 创建数据集
在这里,对于每个示例,KNN数据集中的数据点被展平为它们的行向量形式。演示使用k-means将12个数据点聚类为3个质心。
import smile.clustering.GMeans
import smile.clustering.KMeansimport io.skymind.zeppelin.utils._
import org.nd4j.linalg.factory.Nd4jval kmeanData = Array(Array(-1.0, -1.2, -1.1), Array(-1.1, -1.1, -1.0), Array(-0.9, -0.9, -1.2), Array(-0.9, -1.0, -0.9), Array(0.0, 0.0, 0.0), Array(0.1, 0.2, 0.3), Array(-0.1, 0.2, -0.1), Array(0.1, 0.1, 0.1), Array(1.0, 1.0, 1.0),Array(1.1, 1.1, 1.1),Array(1.0, 0.9, 0.9),Array(1.2, 0.9, 1.0)
)val kmeans = new KMeans(kmeanData, 3)kmeans.predict(Array(-1.0, 0.0, 0.0))val centers = kmeans.centroids()val array = Nd4j.create(centers)array变量包含3个质心,将用作KNN数据集。
2. 创建标签
这里的标签非常简单,每一行都被标记为其索引。实际上,这些标签可以是任何字符串值。
val labels = centers.indices3. 保存数据集
要将INDArrays序列化为二进制形式,请确保使用 BinarySerde#writeArrayToDisk。
import java.io.File
import org.nd4j.serde.binary.BinarySerdeBinarySerde.writeArrayToDisk(array, new File("/tmp/centroids.bin"))4. 保存标签
标签可以正常保存,每行代表数据集中每行数据向量的标签字符串。
import java.io.PrintWriterval writer = new PrintWriter(new File("/tmp/centroids.labels"))for (i <- labels) {writer.println(i.toString)
}
writer.close()5. 导入KNN
可以像在SKIL用户界面中导入其他部署模型一样导入KNN模型。
导入模型
在笔记本示例中,模型保存在/tmp/centroids.bin,标签保存在/tmp/centroids.labels。请记住,标签文件是可选的。
当你想知道从输入数据点到数据点的最远距离时,“inverted”复选框很有用。当你想在数据集中查找离群点时,这很有用。
“相似性函数”选择列表指定了在计算给定数据点与数据集中其余示例之间的相似性/距离时要使用的距离函数。
填写完表格后,如下图所示,单击“导入KNN(Import KNN)”。
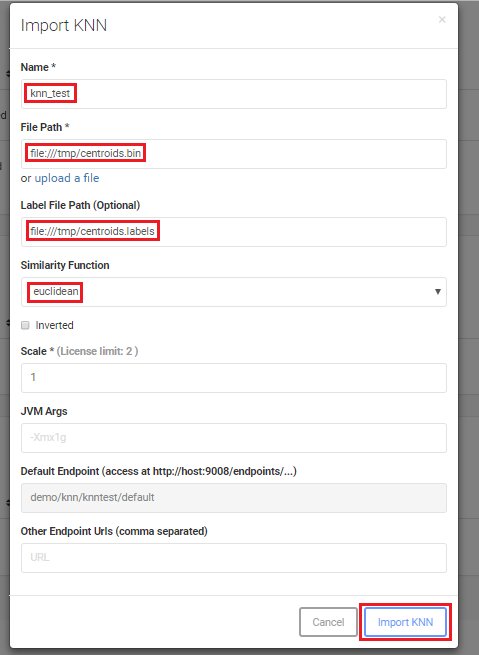
填写KNN导入明细
模型导入成功后,启动KNN服务器。
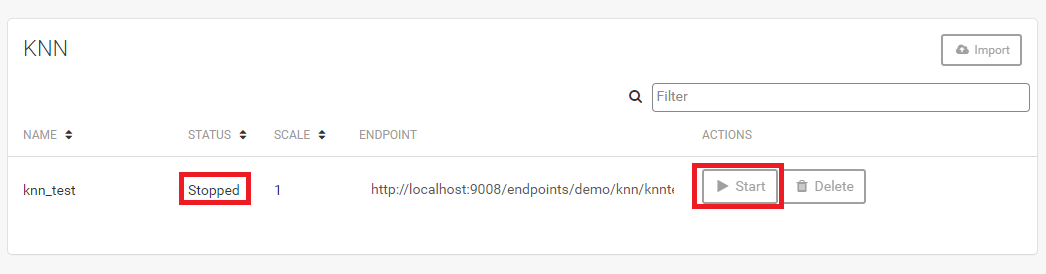
启动KNN服务器
在状态指示服务器已启动后,可以查询KNN服务器。同时复制使用“endpoint”头的端点URL。这里是http://localhost:9008/endpoints/demo/knn/knntest/default/。这可能会因填写在KNN导入模型表单中的表单设置而有所不同。
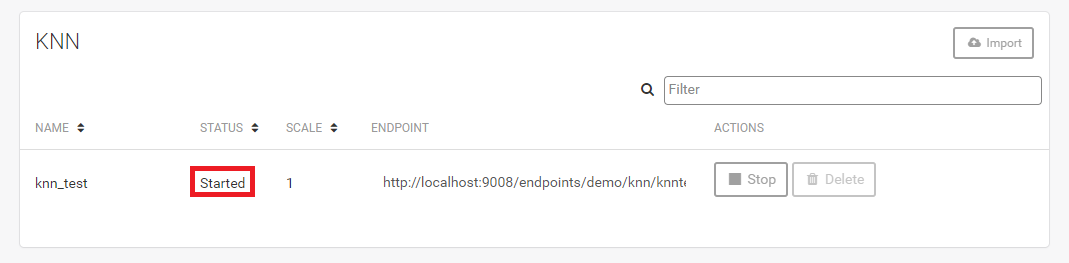
KNN 服务器启动
6. 查询KNN模型
要查询KNN模型,可以使用以下端点:
- https://docs.skymind.ai/v1.1/reference#knn
- https://docs.skymind.ai/v1.1/reference#knnnew
// 部署完之后:
import com.mashape.unirest.http.Unirest
import org.json.JSONObjectimport java.text.MessageFormatimport org.nd4j.linalg.factory.Nd4j
import org.nd4j.serde.base64.Nd4jBase64val skilContext = new SkilContext()Unirest.setDefaultHeader("Authorization", "Token " + skilContext.client.getAuthToken);//Ref: https://docs.skymind.ai/v1.1/reference#knn
val nearestNeighborResultsKnn = Unirest.post(MessageFormat.format("http://localhost:9008/endpoints/demo/knn/knntest/default/{0}", "knn")).header("accept", "application/json").header("Content-Type", "application/json").body(new JSONObject() //使用它是因为字段函数无法转换为可接受的JSON.put("k", 2).put("index", 1).toString()).asJson().getBody().getObject()val base64Array = Nd4jBase64.base64String(Nd4j.create(Array(0.0, 0.0, 0.0))); // Base64 Encoded form of Array - [0.0, 0.0, 0.0]// Ref: https://docs.skymind.ai/v1.1/reference#knnnew
val nearestNeighborResultsKnnNew = Unirest.post(MessageFormat.format("http://localhost:9008/endpoints/demo/knn/knntest/default/{0}", "knnnew")).header("accept", "application/json").header("Content-Type", "application/json").body(new JSONObject() //使用它是因为字段函数无法转换为可接受的JSON.put("k", 2).put("index", 1).put("ndarray", base64Array).toString()).asJson().getBody().getObject()这篇关于SKIL/工作流程/KNN(K邻近值算法)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




