skil专题
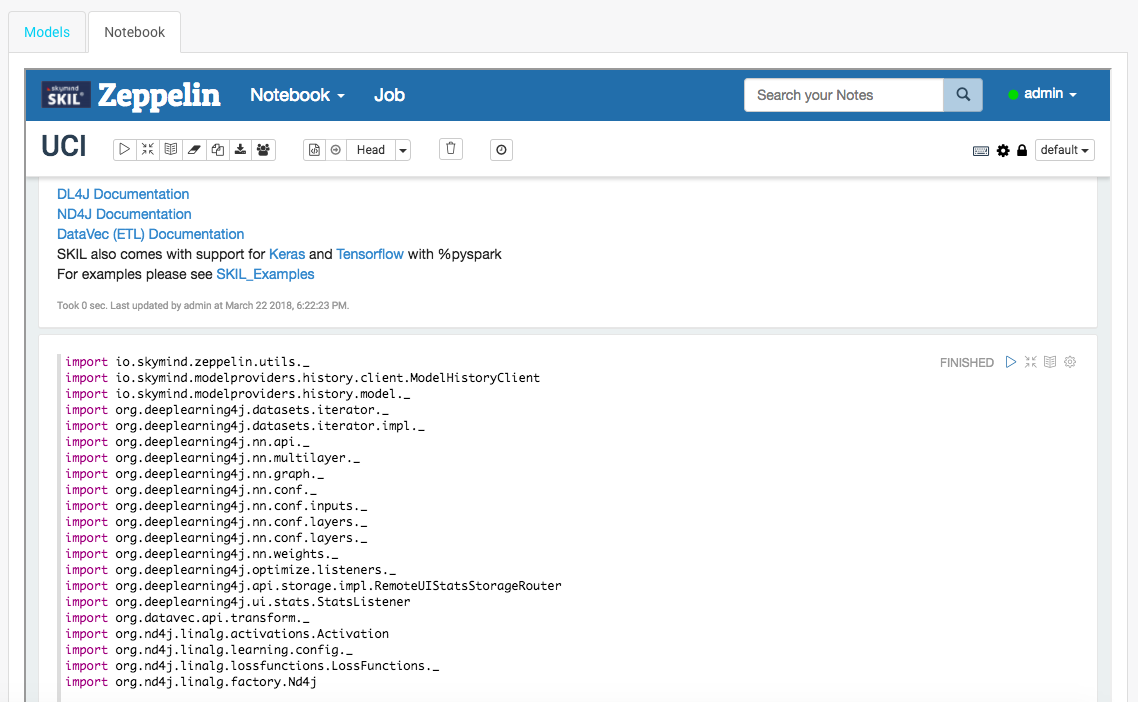
SKIL/工作流程/在实验中训练模型
在实验中训练模型 如果你想跟踪结果并进行可重复的评估,实验对于训练模型很有用。一旦你学习了工作间,笔记本和进行实验的基本知识你就准备好用SKIL练一个模型了。 先决条件 这个文档假设你已经设置了一个工作间并在SKIL中创建了一个新的实验。创建实验后,打开“笔记本”选项卡,该选项卡将显示scala的模板笔记本,其中已设置导入和结构化训练代码。 如果你不打算动态加载任何其他依赖项,可以单击
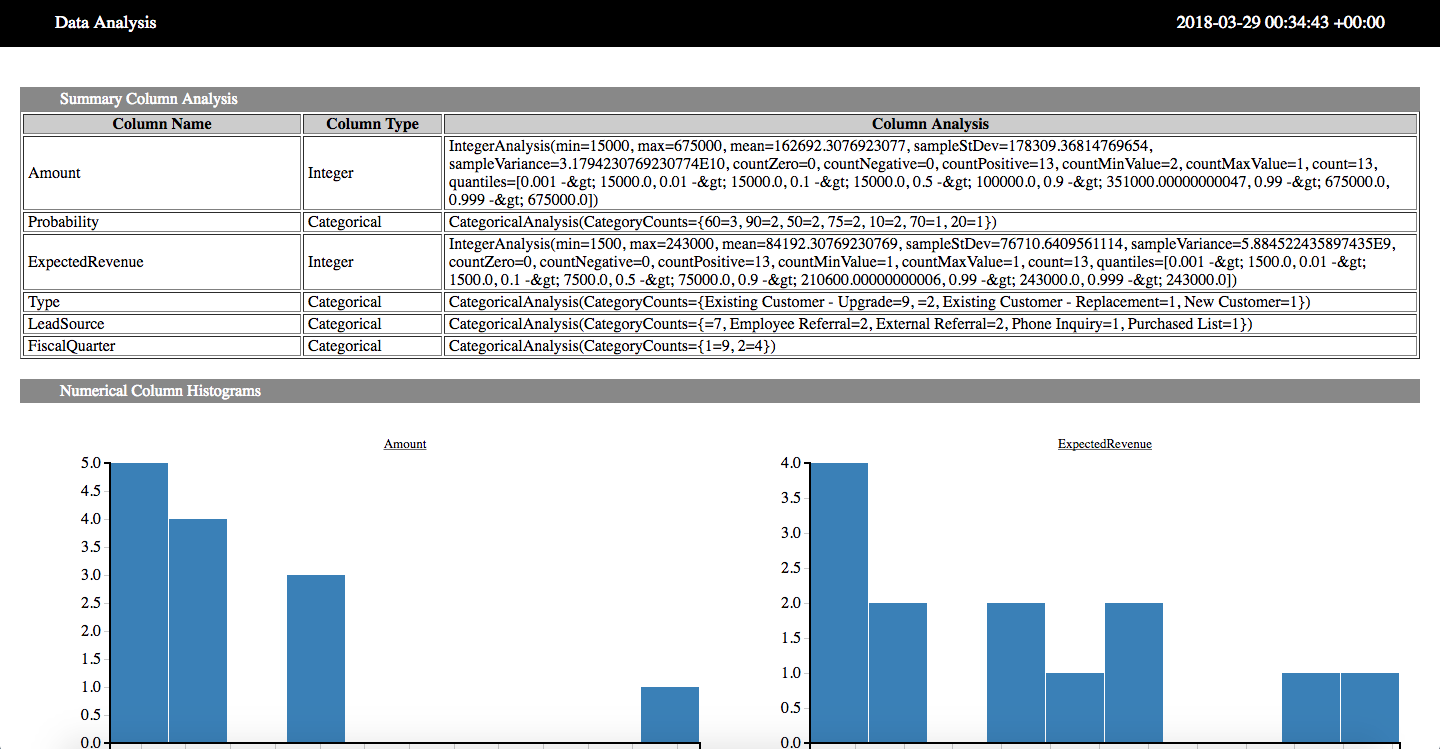
SKIL/工作流程/可视化
可视化 有两种方法可以在SKIL中可视化数据。可视化对于解释结果和理解其他复杂数组很有用,并且通常需要通过T-SNE或UMAP等算法实现降维。 训练可视化 使用Deeplarming4J用户界面 如果你正在使用deeplearning4j,则可以在训练模型时可视化统计数据。SKIL预先打包了一个ui服务器,该服务器将通过将ui标志传递到skil start脚本来自动启动: #如果没
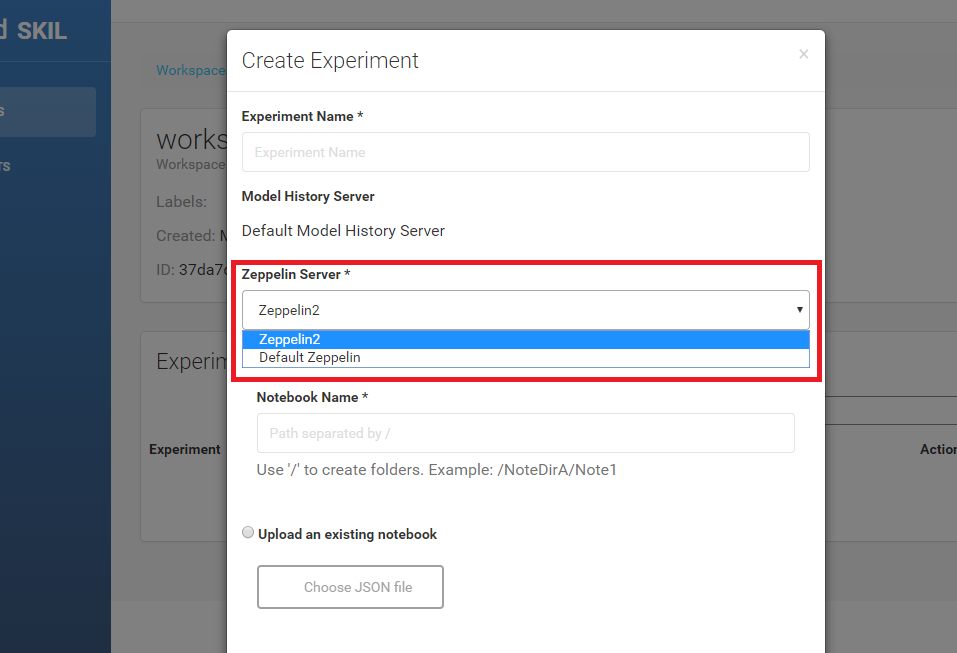
SKIL/工作流程/添加更多Zeppelin实例
添加更多Zeppelin实例 当SKIL启动时,它将默认创建一个名为“Default Zeppelin”(在端口8080上)的zeppelin服务器进程。此服务器负责管理SKIL中“实验”的笔记本。除了默认的Zeppelin服务器,还有一个默认的Zeppelin解释器进程(以“Default Interpreter”的名称),负责执行笔记本中的段落(在端口6500上运行)。下图显示了Zeppel
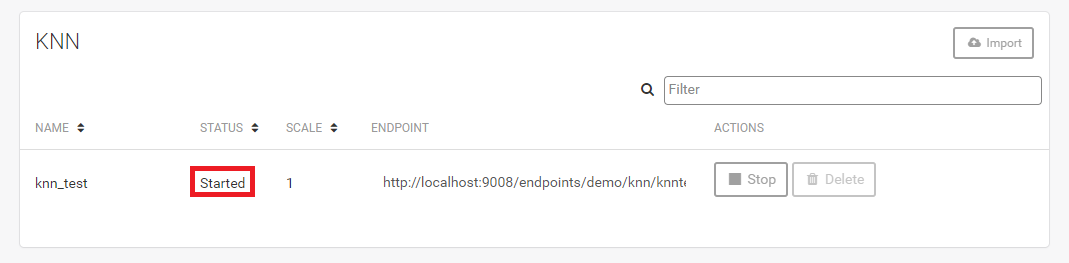
SKIL/工作流程/KNN(K邻近值算法)
K邻近值算法 除了部署转换和网络模型,SKIL还允许你部署KNN模型。 KNN (k邻近值算法) 是最简单的分类算法之一,广泛用于解决机器学习的基本问题。通过计算输入数据和数据集中所有示例之间的相似度(或距离)函数,找出最接近给定数据点的示例。knn中的“k”表示算法在对数据执行时,我们希望获得的最接近的示例的“k”个分类数。 K邻近值算法流程 该工作流程涉及到生成一个二进制KNN向