本文主要是介绍SKIL/工作流程/可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
可视化
有两种方法可以在SKIL中可视化数据。可视化对于解释结果和理解其他复杂数组很有用,并且通常需要通过T-SNE或UMAP等算法实现降维。
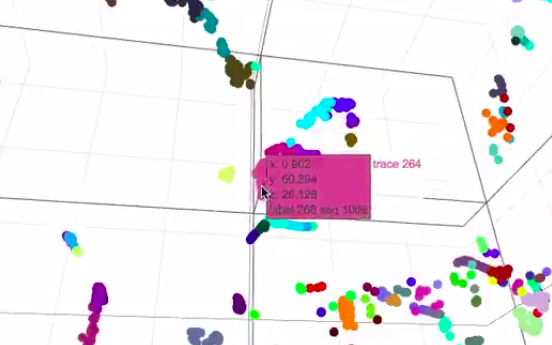
训练可视化
使用Deeplarming4J用户界面
如果你正在使用deeplearning4j,则可以在训练模型时可视化统计数据。SKIL预先打包了一个ui服务器,该服务器将通过将ui标志传递到skil start脚本来自动启动:
#如果没有设置SKIL_HOME和JAVA_HOME变量,请取消对以下行的注释
# export SKIL_HOME=/opt/skil
# export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk# 首先进行授权
$SKIL_HOME/sbin/skil login --userId admin --password admin # 你可能有不同的用户名和密码,请相应地替换它们。# 启动
$SKIL_HOME/sbin/skil ui
对于docker,你需要转发端口9002以访问UI。
# 从Docker启动,确保你映射了端口9002
docker run --rm -it -p 9008:9008 -p 8080:8080 -p 9002:9002 skymindops/skil-ce bash /start-skil.sh稍后,你可以在笔记本中添加一个%sh单元,专门启动UI服务器:
%sh#如果没有设置SKIL_HOME和JAVA_HOME变量,请取消对以下行的注释
# export SKIL_HOME=/opt/skil
# export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk# 首先进行授权
$SKIL_HOME/sbin/skil login --userId admin --password admin # 你可能有不同的用户名和密码,请相应地替换它们。# 启动
$SKIL_HOME/sbin/skil uiskil ui命令的默认参数及其详细信息如下:
| 参数 | 默认值 | 详情 |
| uiPort | 9002 | 用于用户界面服务器的端口 |
| enableRemote | True | 是否启用远程。它控制是否允许远程连接。 |
上面的命令$SKIL_HOME/sbin/skil ui将在端口9002启动一个用户界面服务器,默认情况下允许远程连接。你可以进一步提供--uiPort和--enableMemote参数,以在其他端口启动ui服务器,或者如果你想控制到该服务器的远程连接。
$SKIL_HOME/sbin/skil ui --uiPort 9010 --enableRemote False # 在端口9010启动UI服务器,禁用远程连接Visualizing the DL4J Network
You will need to route your StatsListener to the UI port (default 9002). You can view the demo for DL4J UI with the default notebook that is created when you create an "Experiment" in SKIL and uncomment the following lines in the 4th paragraph.
可视化DL4J网络
你需要将StatsListener路由到UI端口(默认9002)。你可以使用在skil中创建“实验”时创建的默认笔记本来查看DL4J UI的演示,并在第4段中取消对以下行的注释。
//val remoteUIRouter = new RemoteUIStatsStorageRouter("http://localhost:9002")
//model.setListeners(new StatsListener(remoteUIRouter))在取消对上述行的注释后,运行笔记本的前四段,然后在UI端口上可视化网络(此处,默认情况下,它设置为笔记本中的端口9002),这看起来类似于下面的图像。
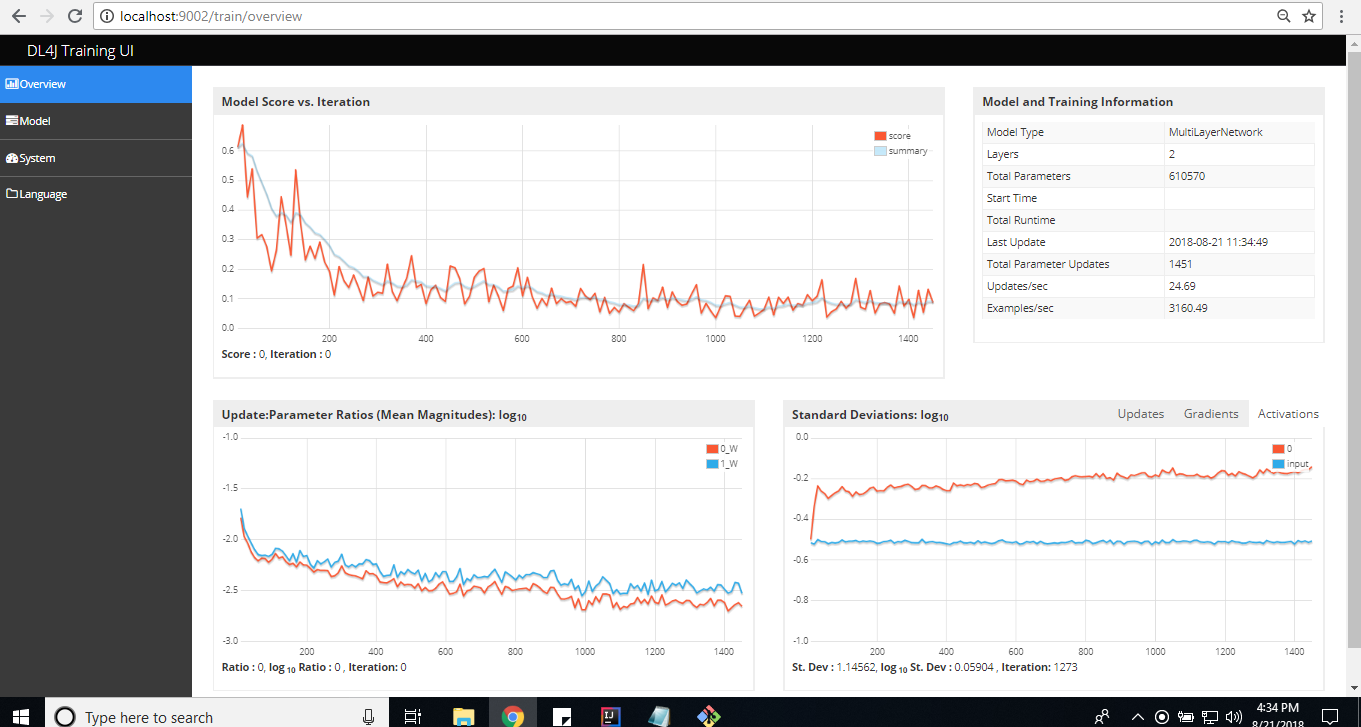
在DL4J UI中可视化模型。
有关更多信息和用法,请参阅Deeplarning4j UI文档。
Tensorboard中TensorFlow模型的可视化
SKIL预先打包了TensorBoard,允许你可视化TensorFlow模型的训练。在笔记本中进行训练时,你可以以标准方式使用Tensorboard:
# bare metal installation
tensorboard --logdir=path/to/log-directory# when using Docker, manually start a TensorBoard instance
docker exec -it skil_container /bin/bash
tensorboard --logdir=path/to/log-directory有关完整用法和示例,请参阅Tensorboard文档。
解释器功能
由于笔记本由ApacheZeppelin提供,许多内置可视化功能可用于结构化和非结构化数据。这是一个提供演示的可视化效果的示例笔记本。
使用SQL可以实现最简单的可视化。如果在笔记本中创建一个%sql单元,并对Spark RDD或任何其他缓存数据执行SQL查询,则可以很容易地以原始表格格式查看输出。
%sqlselect numPositions, count(1) value
from stats
where numPositions < 65
group by numPositions
order by numPositions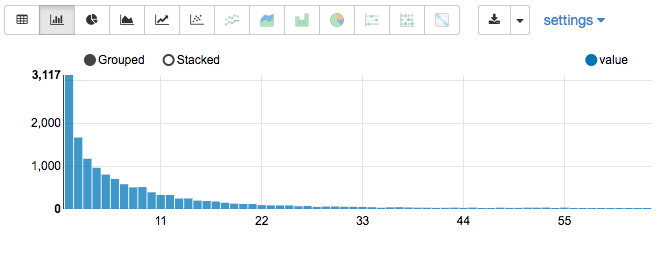
如果你喜欢手动使用内置可视化功能,还可以通过使输出以%table 开头并用\t 分隔每行数据来打印表。
%sparkprintln("%table\nx\ty")
(1 to 340).map(i => i.toDouble / 50).map(x => (x, Math.sin(x))).foreach{case (x,y) => println(x + "\t" + y)}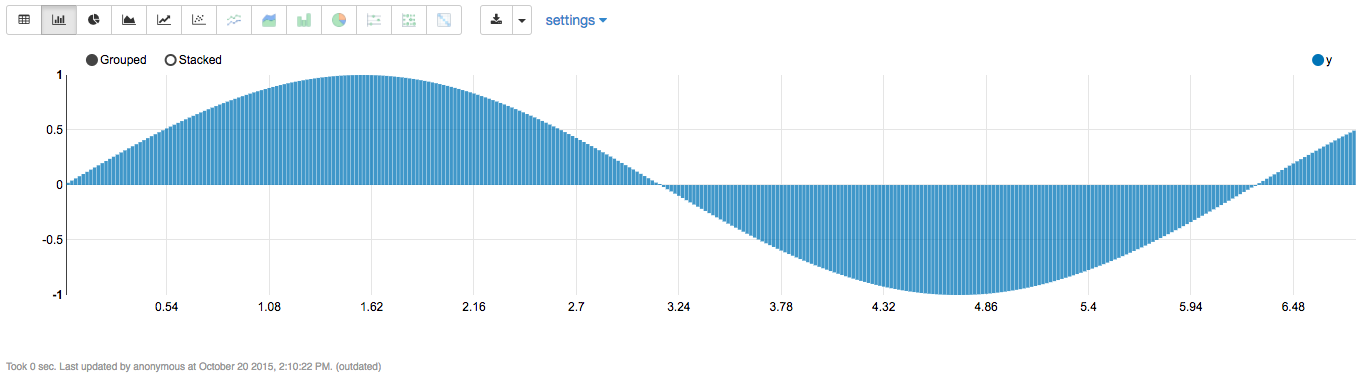
数据摘要
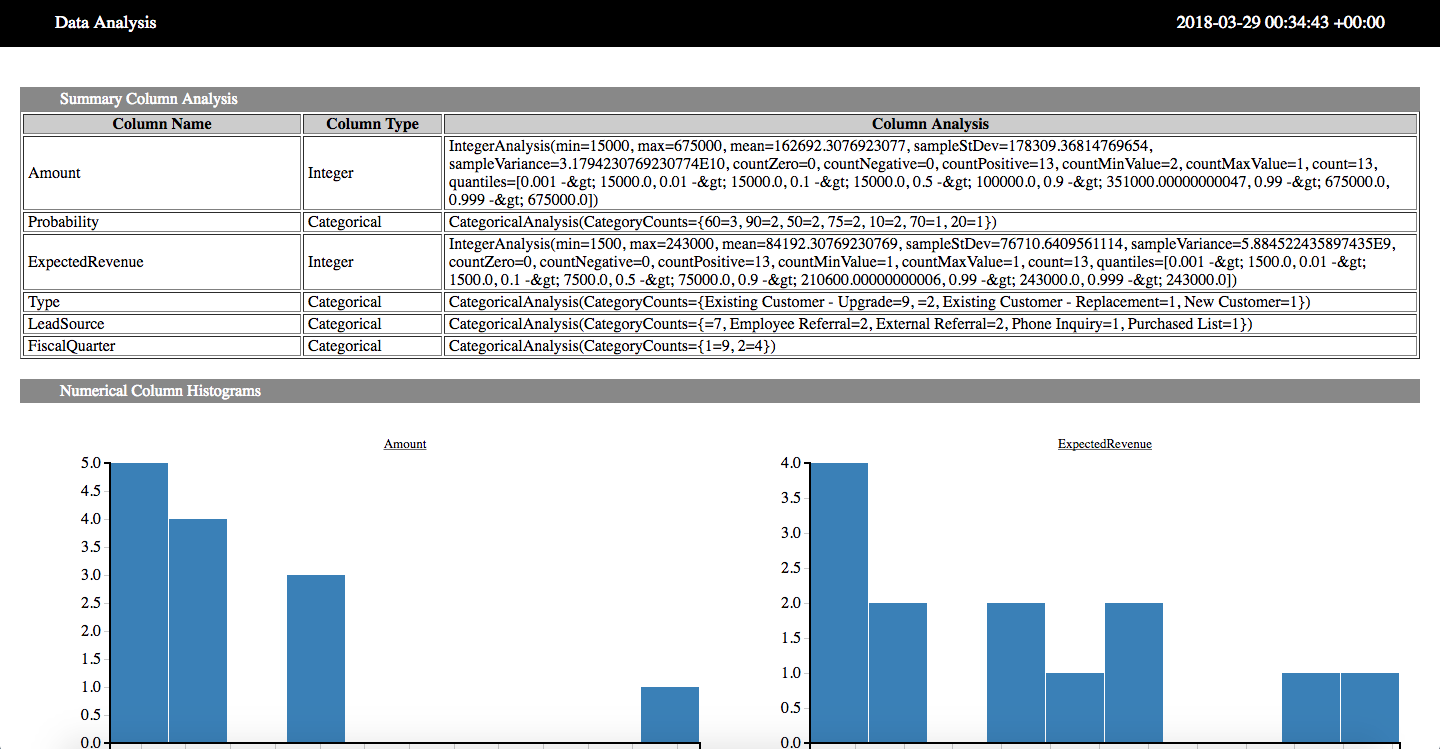
除了Zeppelin支持的内置功能外,SKIL还允许你对输入数据进行DataVec分析,并计算数据集的统计信息。你可以以内联方式呈现结果,也可以查看端口9508。如果使用docker,请记住在运行你的SKIL容器之前添加-p 9508:9508。
%sparkimport org.datavec.spark.transform.AnalyzeSpark
import org.datavec.api.transform.ui.HtmlAnalysis
import java.io.Fileval dataAnalysis = AnalyzeSpark.analyze(tp.getFinalSchema(), processedData, 10)// 提交到文件
HtmlAnalysis.createHtmlAnalysisFile(dataAnalysis, new File("/opt/skil/plugins/files/sf-analysis.html"))// 提交内联
print("%html <iframe src=\"http://localhost:9508/files/sf-analysis.html\"></iframe>")
结果将像一个常规的HTML页面,其中包含列和数据集统计信息。
这篇关于SKIL/工作流程/可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




